

本文阐述了计算机辅助医学成像领域的图像分析方法。机器学习,特别是深度学习领域的最新进展,对医学图像的识别、分类和量化的发展起到了促进作用。这些进展的核心是能够仅从数据中学习到分级特征,而不是根据领域特定的知识手动设计特征。深度学习正迅速成为一种最先进的学习方式,在各种医学应用场景中表现突出。本文介绍了深度学习的基本原理,并回顾了它们在图像配准、解剖和细胞结构检测、组织分割、计算机辅助疾病诊断和预后等方面的成功经验。最后,我们讨论了现有研究存在的问题,并对未来改进的方向提出了建议。本文发表在Annual Review of Biomedical Engineering杂志(原文:Deep Learning in Medical Image Analysis)https://doi.org/10.1146/annurev- bioeng- 071516- 044442
1. 简介
在过去的几十年里,计算机断层扫描(CT)、磁共振成像(MRI)、正电子发射断层扫描术(PET)、乳房X光检查、超声波、X射线等医学成像技术,已被广泛用于疾病的早期发现、诊断和治疗(1)。在临床上,医学图像的解释大多是由放射科医生和内科医生等人类专家进行的。然而,考虑到病理上的巨大差异和人类专家的潜在疲劳,研究人员和医生已经开始从计算机辅助干预中受益。虽然计算医学图像分析的发展速度没有医学成像技术那么快,但随着机器学习技术的引入,这种情况正在改善。
在机器学习应用的过程中,发现或学习能够很好地描述数据固有规律或模式的有效特征,在医学图像分析的各种任务中起着至关重要的作用。传统上,有意义的或与任务相关的特征通常主要是由人类专家根据他们对目标领域的知识设计的,这使得非专家在自己的研究中利用机器学习技术具有挑战性。与此同时,努力学习基于预定义字典的稀疏表示,而这是可能会从训练样本中学习到的。在许多科学领域中,稀疏表示的动机是简约原则,即对给定观测的最简单解释应该优先于更复杂的解释。稀疏诱导惩罚和字典学习已经证明了该方法在医学图像分析中用于特征表示和特征选择的有效性(2-6)。应该注意的是,文献中描述的稀疏表示或字典学习方法仍然可以在具有浅体系结构的数据中发现固有的信息模式或规律,从而限制了它们的表示能力。然而,深度学习(7)通过将特征工程步骤合并到学习步骤中,克服了这个障碍。也就是说,深度学习只需要经过较小预处理(如果有必要的话)的一组数据,然后以自学方式(8、9)发现信息表示,而不是手动提取特征。因此,特征工程的负担已经从人类转移到了计算机上,使得机器学习中的非专家可以有效地将深度学习用于他们自己的研究和/或应用,特别是在医学图像分析中。
深度学习取得前所未有的成功主要归功于以下因素:(a)高性能的中央处理器(CPU)和图形处理器(GPU)的发展,(b)海量数据(即大数据)的可获得性,以及(c)学习算法(learning algorithms)的发展(10-14)。从技术上讲,深度学习可以看作是对传统人工神经网络(ANN)(15)的改进,因为它能够构建具有多个(多于两个)层的网络。深度神经网络可以发现分级特征表示(hierarchical feature representations),使得可以从较低级别的特征(9)导出较高级别的特征。由于这些技术使分级特征表示能够仅从数据中学习,深度学习在各种人工智能应用程序(16-23)和挑战赛(24、25;https://grand-challenge.org) 中取得了破纪录的性能。计算机视觉技术的进步促进了深度学习在医学图像分析中的应用,例如图像分割(26,27)、图像配准(28)、图像融合(29)、图像注释(30)、计算机辅助诊断(CADx)和预后(31-33)、病变/标记点检测(34-36)和显微图像分析(37,38)。
当训练阶段可用样本数量较大时,深度学习方法是非常有效的。例如,在ImageNet视觉识别挑战赛(ILSVRC)中有100多万张带注释的图像可用(24)。然而,在大多数医学应用中,图像要少得多(通常数量少于1000)。因此,将深度学习应用于医学图像的主要挑战是可用于构建深度模型的训练样本数量有限,难以避免过拟合。为了克服这一困难,研究人员设计出了各种策略,例如:
(a) 将二维(2D)或三维(3D)图像块(image patches)而不是全尺寸图像作为输入(29,39-45),以降低输入维数并减少模型构建所需参数;
(b) 通过仿射变换人工生成样本(即数据增强)来扩展数据集,然后用增强的数据集从头开始训练它们的网络(39-42);
(c) 使用在计算机视觉中通过对大量自然图像训练生成的深度模型作为“现成”特征提取器,用目标任务样本(43,45)训练最终分类器或输出层;
(d) 使用来自非医学或自然图像的预训练模型的模型参数初始化模型参数,然后用与任务有关的样本微调网络参数(46,47);
(e) 通过将全连接层中的权重转换为卷积核,对任意大小的输入使用用小尺寸图像作为输入训练出的模型。
根据输入类型,我们可以将深度模型分为以矢量格式(即非结构化)值作为输入的典型多层神经网络和以2D或3D(即结构化)值作为输入的卷积网络。由于图像的结构特征(包含在相邻像素或体素中的结构信息是另一个重要的信息源),卷积神经网络(CNNs)在医学图像分析领域引起了极大兴趣(26,35-37,48-50)。然而,具有矢量化输入的网络也已成功地用于不同的医学应用(28、29、31、33、51-54)。与深度神经网络一起,深度生成模型(55)-例如深度信念网络(DBN)和深度Boltzmann机(DBMS)是具有多层隐藏变量的概率图形模型-已经被成功应用于脑部疾病诊断(29、33、47、56)、病变分割(36、49、57、58)、细胞分割(37、38、59、60)、图像解析(61-63)和组织分类(26、35、48、50)等领域的研究。
本文结构如下。在第二节中,我们解释了神经网络和深度模型的计算理论[例如,堆叠自动编码器(SAE)、DBN、DBMS、CNN],并讨论了它们如何从数据中提取高级表示。在第三节中,我们介绍了使用深度模型在医学图像中的不同应用的最新研究,包括图像配准、解剖定位、病变分割、物体和细胞检测、组织分割以及计算机辅助检测(CADE)和CADx。最后,在第四节中,我们总结了研究趋势并提出了进一步改进的方向。
2.深度学习
在这一部分,我们解释了前馈神经网络的基本概念和文献中的基本深度模型。我们重点关注从数据中学习分级特征表示,并讨论了如何通过减少过拟合来有效地学习深度结构的参数。
2.1 前馈神经网络
在机器学习中,人工神经网络是一系列模型,它模仿神经系统的结构,并学习观察其中的固有模式。感知机(64)是最早的具有单层结构的可训练神经网络,由输入层和输出层组成。感知机或具有多个输出单元的改进感知机(图1a)被视为线性模型,但通常不会用于涉及复杂数据模式的任务,尽管在输出层使用了非线性激活函数。

图1. 两种前馈神经网络的体系结构
这一限制可以通过在输入层和输出层之间引入隐藏层来克服。请注意:在神经网络中,相邻层的单元完全彼此连接,但同一层中的单元之间没有连接。对于两层神经网络(图1b),也称为多层感知机,给定输入向量v = [vi ] ∈ RD ,我们可以将输出单元yk的估计函数 (estimation function ) 写成如下合成函数:
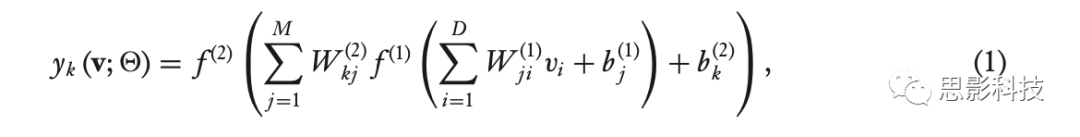
其中上标表示层索引,f(1)(·) 和 f(2)(·) 表示指定层处的单元的非线性激活函数,M是隐藏单元的数目, Θ = {W(1) , W(2) , b(1) , b(2) } 是参数集。隐藏单元的激活函数 f(1)(·) 通常用诸如Logistic Sigmoid函数或双曲正切函数的S型函数定义。因为估计是向前进行的,所以这种类型的网络也被称为前馈神经网络。
当将公式1中的隐层视为来自输入v的特征提取器 φ(v)=[φj(v)]∈RM 时,输出层仅为一个简单线性模型,
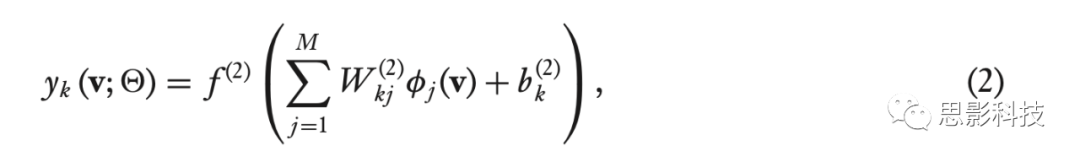
其中,
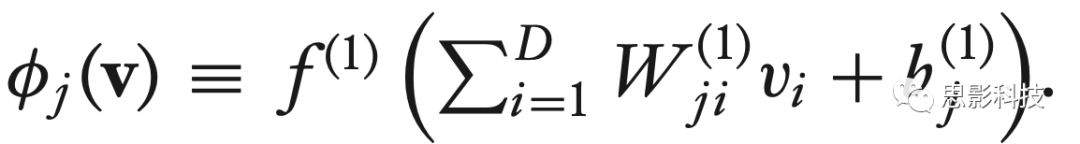
同样的解释也适用于隐层数量较多的情况。因此,可以直观地看出,隐层的作用是查找对目标任务有用的特征。
神经网络的实际应用要求从数据中学习模型参数。参数学习问题可以表示为误差函数的最小化。从优化的角度来看,神经网络的误差函数E是高度非线性和非凸的。因此,参数集没有解析解。取而代之的是,可以通过迭代更新参数来使用梯度下降算法。为了利用梯度下降算法,必须有一种方法来计算在参数集Θ处求值的梯度∇E(Θ)。
对于前馈神经网络,可以通过误差反向传播(65)有效地评估梯度。一旦知道所有层的梯度矢量,参数集Θ∈{W(1),W(2),b(1),b(2)} 可以更新如下:

其中η是学习率,τ表示迭代指数。重复更新过程,直到收敛或达到预定义的迭代次数。对于公式3中的参数更新,文献(66)中通常使用具有小训练样本子集(称为小批量(minibatch) )的随机梯度下降。
2.2 深度模型
对激活函数作一个温和预设,具有有限个隐含单元的两层神经网络就可以逼近任意连续函数(67),因此,它被认为是一个通用逼近器(approximator )。不过,通过使用单元数量少得多(8)的深层架构(即具有两层以上的架构) ,也可以将复杂函数近似到相同的精度。因此,可以减少可训练参数的数量,使得能够用相对较小的数据集(68)进行训练。
2.3 无监督特征表示学习
与大多数基于专业知识手工设计良好的特征提取器的浅层体系结构相比,深度模型对于以分级(即从精细到抽象)的方式从数据中发现信息特征是有用的。在这里,我们介绍了三种广泛应用于不同场景的无监督特征表示学习的深度模型。
2.3.1 栈式自编码器(SAE)
自动编码机或自动关联器(69)是一种特殊类型的两层神经网络,通过最小化网络的输入和输出值之间的重构误差(reconstruction error)来学习输入的潜在或压缩表示,即通过学习表示(representations),重构输入。由于其结构比较简单且层数较浅,单层自动编码机的表现力非常有限。但是,当在称为SAE的结构中堆叠多个自动编码机(图2A)时,通过使用一个自动编码器的隐藏单元的激活值作为下一个较高自动编码器(70)的输入,可以显著提高表示能力。SAE最重要的特点之一是能够学习或发现高非线性且复杂的模式,如输入值之间的关系。当将一个矢量输入SAE时,网络的不同层表示不同级别的信息。也就是说,网络中的层越低,模式就越简单,层越高,输入矢量中固有的模式就越复杂或抽象。

图2.三种具有代表性的输入数据矢量化的无监督特征学习深度模型。红色箭头(包括所有有向的和无向的)表示两个连续层间的单元全部相连,但同一层中的单元之间没有连接。请注意有向/无向连接模型之间的差异,以及描述条件关系的连接方向。
一种直接获取SAE中权重矩阵和偏差的训练参数的方法是将反向传播应用到基于梯度的优化技术中,即将SAE作为传统的前馈神经网络随机初始化。但是,以这种方式训练的深度网络比具有浅层体系结构的网络性能更差,因为它们落入较差的局部最优(71)。为了绕过这个问题,我们应该考虑逐层贪婪训练(greedy layer-wise learning)(10,72)。逐层贪婪学习的关键思想是一次预先训练一层,即用户以训练数据作为输入来训练第一隐层的参数,然后以来自第一隐层的输出作为输入来训练第二隐层的参数,依此类推。换言之,将第l个隐层的表示用作第(l+1)个隐藏层的输入。这种预训练技术的一个重要优点是利用标准的反向传播算法以无监督的方式进行,使用户能够通过利用用于训练的未标记样本来增加数据集的大小。
2.3.2 深度信念网络(Deep belief network)
受限玻尔兹曼机(RBM)(73)是一种单层无向图模型,具有可见层和隐层。它假定可见层和隐层之间存在对称连接,但同一层内的单元之间没有连接。由于连通性的对称性,它可以从隐藏表示(hidden representations)生成输入观测(input observations)。因此,RBM自然成为自动编码器(10,73),并且其参数通常通过使用对比发散算法(contrastive divergence algorithm)(74)来训练,以便最大化观测的对数似然(log likelihood)。与SAE类似,可以堆叠RBM以构建深层架构,从而形成称为DBN的单一概率模型。DBN具有一个可见层v和一系列隐层h(1),…,h(L)(图2b)。注意,当多个RBM分层堆叠时,尽管最上面两层仍然形成无向生成模型(即RBM),但较低层形成有向生成模型。因此,DBN中观测单元v和L个隐藏层h(l)(l=1,…,L)的联合分布为:

其中,P(h(l)|h(l+1)) 对应于给定层l+1单元的层l的单元的条件分布,而P(h(L-1),h(L))表示层L−1和L中的单元的联合分布。
对于参数的学习,逐层贪婪预训练方案(10)可以应用于以下步骤中:
1. 将第一层训练为v=h(0)的RBM(受限玻尔兹曼机)。
2. 利用P(h(1)=1|h(0))的平均激活或P(h(1)|h(0))绘制的样本作为输入,使用第一隐层获取输入表示,并将其用作第二隐层的观测。
3.将变换后的数据(平均激活或样本)作为训练样本(用于RBM的可见层),将第二隐层训练为RBM。
4.针对所需层数重复步骤2和3,每次向上传播平均激活P(h(l)=1|h(l+1)) 或根据条件概率P(h(l)|h(l+1))抽取的样本。
在逐层贪婪训练过程完成之后,可以应用唤醒-睡眠算法(wake–sleep algorithm)(75)来进一步增加观测的对数似然。不过通常在实践中不会对整个DBN进行进一步的联合训练。
2.3.3 深度波尔兹曼机(DBM)
DBM(55)也是通过以分层方式堆叠多个RBMs来构建的。与DBN相比,DBM的不同之处在于RBM中的所有层在堆叠之后形成了一个无向生成模型(图2c)。因此,对于隐层l,除了l=1和l=L的情况外,层的概率分布由其两个相邻层l+1和l−1[即P(h(l)|h(l+1),h(l−1))]来限定。来自上层和下层的信息的结合提高了DBM的表示能力(representational power),从而使其对噪声观测更鲁棒(robust)。
如图2C所示,当L=2时,一个三层DBM给定相邻层中的单元值,将二进制可见单元或二进制隐藏单元设置为1时,概率计算如下:

其中σ(·)表示Sigmoid函数符号。为了学习参数 Θ={W(1),W(2)},我们最大化观测的对数似然。对于模型参数,观测值的对数似然的导数采用以下简单形式:

其中,Edata[·]表示通过对以可见单元v(=h(0))为条件的模型进行采样而获得的数据依赖统计(data-dependent statistics ),而Emodel[·]表示通过模型采样获得的数据独立统计(data-independent statistics )。当模型很好地逼近数据分布时,数据依赖统计和数据独立统计达到均衡。
2.4 微调目标任务的深度模型
我们可以注意到,在上述三个深度模型的特征表示学习期间从不涉及目标值(观察的离散标签或连续实值)。因此,不能保证SAE、DBN或DBMS学习的表示对于分类任务是有区别的。为了解决这一问题,通常在无监督特征表示学习之后进行微调步骤。对于涉及分类或回归的特定任务,通过使用适当的输出函数在SAE、DBN或DBM中的最高隐藏层之上堆叠另一输出层,可以直接将特征表示学习模型转换为深度神经网络。
对于DBM,当将DBM转换成深度神经网络(55)时,应该顺便用第二隐层的近似后部边缘来增广原始输入向量。之后,使用顶部输出层来预测输入的目标值。为了微调深度神经网络的参数,我们首先将预训练好的隐层连接权值作为初始值,随机初始化隐层顶层和输出层之间的连接权重,然后用反向传播算法以梯度下降法以有监督(即端到端)的方式联合训练参数。通过预训练初始化参数有助于降低有监督优化陷入较差局部最优(10,71)的风险。
2.5 卷积神经网络
如上所述,在SAE、DBN和DBMS的深度模型中,输入总是矢量形式的。然而,对于(医学)图像,相邻像素或体素之间的结构信息也很重要,但矢量化不可避免地会破坏图像中的这种结构和结构信息。通过将2D或3D图像作为输入,CNN(76)可以更好地利用空间和结构信息。在结构上,CNN的卷积层间散布着池化层,并且具有标准神经网络的全连接层。与深度神经网络不同,CNN利用了三种机制--局部感受野、参数共享及降采样(图3)--这三种机制大大降低了模型的自由度。

图3. 卷积神经网络中的三个关键机制(局部感受野,参数共享和降采样)
卷积层的作用是利用可学习的核kij(l)检测输入特征图中不同位置处的局部特征,即层l−1处的特征图i和层l处的特征图j之间的连接权重。
具体地说,卷积层l的单元,仅基于前一层l-1的特征图Ai(l-1) 在空间上相邻的单元子集,通过将核kij(l)卷积为公式(9)来计算它们的激活Aj(l) :
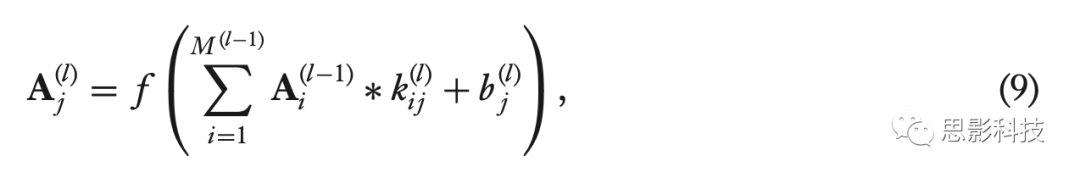
其中M(l−1)表示层l−1中的特征映射(feature maps)的数目,星号表示卷积算子,bj(l)是偏置参数,f(·)是非线性激活函数。由于参数共享机制和局部感受野机制,当输入特征图稍有偏移时,特征图中各单元的激活位移相同。
池化层在卷积层之后,并对卷积层的特征图进行下采样。具体来说,池化层中的每个特征图与卷积层中的特征图相连接;池化层的特征图中的每个单元是基于来自对应的卷积特征图的局部感受野内的单元的子集来计算的。类似于卷积层,感受野在其区域中的单元找到表示值(例如:最大值或平均值)。通常,卷积过程中感受野的大小变化被设置为等于用于降采样的感受野的大小,使得CNN平移不变。
从理论上讲,梯度下降法和反向传播算法相结合也可以应用于CNN的学习参数。然而,由于参数共享、局部感受野及池化的特殊机制,需要进行细微的改变;也就是说,需要使用核权重对所有连接中给定权重的梯度求和,从而确定每层的特征图中的哪个块对应于下一层的特征图中的单元,并对池化层的特征图进行上采样以恢复尺寸减小的图。
2.6 减少过拟合
训练深度模型的一个关键挑战是与可学习参数的数量相比,训练样本的数量是有限的。因此,长期以来,如何减少过拟合一直是一个挑战。最近的研究已经设计出一些算法技巧来更好地训练深度模型。其中一些技巧如下所示:
1.初始化/动量(77,78):使用精心设计的随机初始化参数,及随着迭代过程缓慢增加动量参数的特定调度(particular schedule)。
2.校正线性单元(ReLU)(12,79,80):使用ReLU作为非线性激活函数:
3.去噪(11):堆叠多层去噪自动编码器,这些去噪自动编码器在本地训练,从它们的损坏版本(corrupted versions)重建原始的“干净”输入。
4.丢弃(13)和丢弃连接(81):对于每个训练迭代,随机停用网络中的部分(例如50%) 单元或连接。
5.批次归一化(14):对每个小批次执行归一化并通过归一化参数反向传播梯度。
有关此部分的详细信息,请参阅引用的参考文献。
3.在医学图像方面的应用
与文献中的其他机器学习技术相比,深度学习取得了重大进展。这些成功促使医学图像计算领域的研究人员研究了医学图像中深度学习的潜力,包括通过CT、MRI、PET和X光获取的医学图像。在这一部分中,我们将讨论深度学习在图像配准和定位、解剖和细胞结构检测、组织分割以及计算机辅助疾病预测和诊断中的实际应用。
3.1 医学图像中的深度特征表征(Deep Feature Representation)学习
现有的许多医学图像处理方法依赖于形态学特征表示来识别局部解剖特征。然而,这样的特征表示大多是由人类专家设计的,并且图像特征通常是特定于问题的,并不能保证适用于其他类型的图像。例如,为1.5T T1加权的脑MR图像设计的图像分割和配准方法不适用于7.0T T1加权的MR图像(28,52),更不用说其他模态或不同的器官了。此外,7.0T磁共振图像可以显示大脑的解剖结构,分辨率相当于从体外薄层切片获得的分辨率(82)。因此,研究人员可以在微米尺度上清楚地观察到精细的大脑结构,而这在以前只有通过体外成像才能实现。然而,缺乏有效的计算工具在很大程度上阻碍了新的成像技术向医学成像领域的转化。
虽然最新的方法使用监督学习来寻找与目标任务最相关和最基本的特征,但是它们需要大量的人工标记的训练数据,并且所学习的特征可能是表浅(superficial)的,并且可能在表达解剖结构的复杂性时产生一定的错误。更重要的是,学习过程通常局限于特定的具有一定数量的预先设计的特征的模板域。因此,一旦模板或图像特征改变,整个训练过程必须重新开始。为了打破这些局限,Wu等人(28,52)开发了一个通用的特征表示框架,该框架可以(a)捕捉精确分割和检测大脑区域所需的解剖结构的的内在特征,并可以(b)灵活地应用于不同类型的医学图像。具体地说,这些作者使用具有稀疏约束的SAE,因此他们称之为稀疏自动编码器,以逐层方式分级学习特征表示。他们的SAE模型由分层的编码和解码模块组成(图4)。在编码模块中,给定输入图像块x(patch x),该模型通过非线性确定性映射将输入映射到激活向量y(1)。然后,作者重复这个过程,使用y(1)作为输入来训练第二层,依此类推,直到他们获得高级特征表示(图4)。解码模块通过最小化输入图像块x和解码后的重构块z之间的重建误差来验证学习特征表示的表达能力。
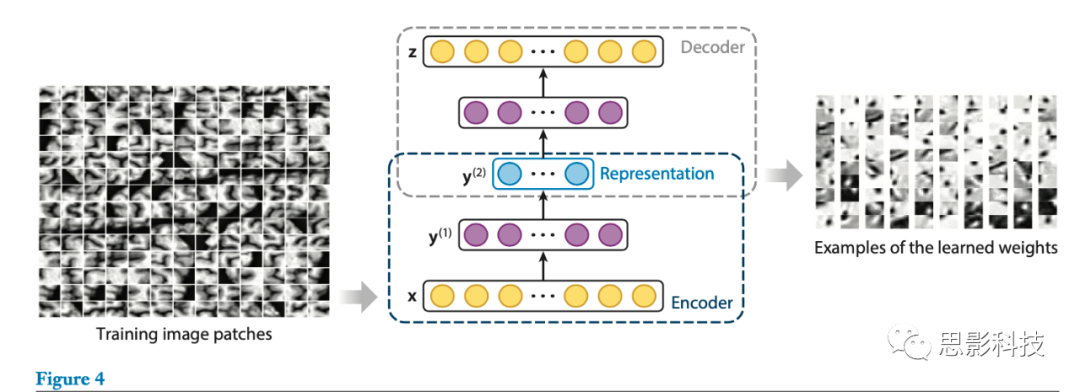
图4. 通过堆叠自动编码器和可视化学习到的特征表示来构建深度编码-解码器。蓝色圆圈表示高级特征表示。黄色和紫色圆圈表示编码器和解码器中各层之间的对应关系。
图5展示了通过深度学习方法学习特征表示的强大功能。图5a-c所示为老年患者的脑图像的典型图像配准结果。图5d-f比较了为找到模板点对应关系的不同特征表示。显然,图5c中变形的受试图像远未与图5a中的模板图像很好地配准,尤其对于脑室而言。从不完美的图像配准给出的不精确的对应关系中学习有意义的特征是非常困难的,这是许多有监督学习方法所面临的问题(83-85)。此外,当使用整个灰度图像块(intensity patch)作为特征向量(图5d)时,特征[例如,局部图像块和尺度不变特征变换(SIFT)(86)]或者检测到过多的非对应点,或者具有太低的响应导致在使用SIFT时错过对应(图5e)。同时,SAE学习到的特征表示为受试图像点提供了最不易混淆的对应信息,使得在受试图像域中定位相应的模板点变得更容易。
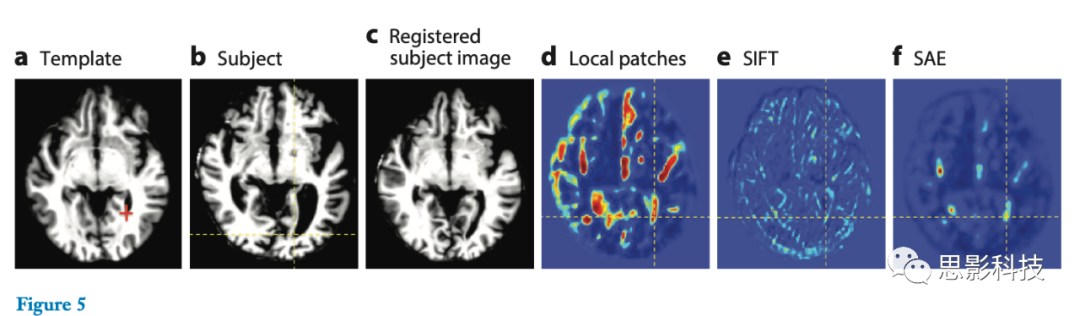
图5.相似图显示了通过手工设计的特征(d,e)和通过无监督深度学习(f)堆叠的自动编码器(SAE)特征来识别模板(a)中的红十字点与受试图像(b)的点的对应关系。配准的主体图像如图c所示。显然,不准确的配准结果可能会破坏高度依赖于所有训练图像之间的对应关系的有监督的特征表示学习。在图d-f中,体素的不同颜色表示它们被选为对应于它们各自位置的可能性。SIFT (scale-invariant feature transform ):比例不变特征变换。
为了定性评价配准精度,Wu等人从各种公共数据集上获得可变形图像配准结果(图6)。对于1.5T和3.0T的MR图像,与Demons的基于强度的微分同态配准方法(87)和HAMMER的基于特征的配准方法(88)等最新配准方法相比,图6e中显示的SAE学习的特征表示具有更好的性能。
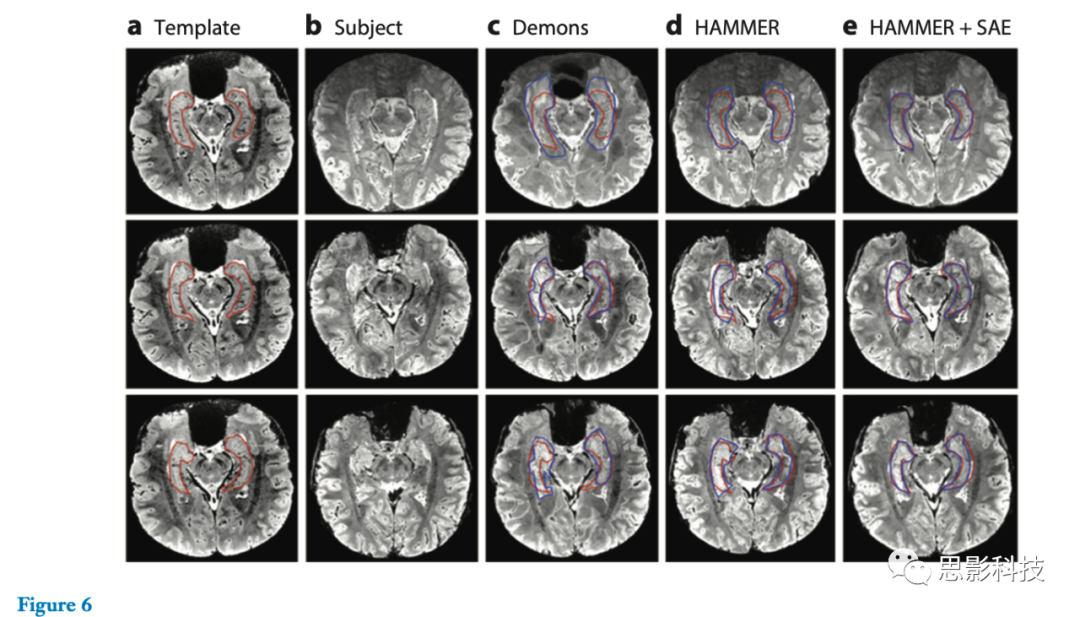
图6 通过(c)Demons(87)、(d)HAMMER(88)和(e)HAMMER结合堆叠自动编码器(SAE)学习的特征表示,在7.0T脑部磁共振图像上的典型配准结果。这三行表示模板、受试者和受试图像配准后的三个不同断层。模板图像上人工标记的海马和不同配准方法得到的受试者变形图像海马分别用红色和蓝色轮廓线标记。 另一个成功的医学应用是在MR图像中定位前列腺(89、90)。在MR图像中精确定位前列腺是困难的,原因有两个:
(a)前列腺周围边界的外观模式在不同患者之间差异很大,(b)不同患者图像之间的灰度(intensity)分布不同,并且通常不遵循高斯分布。为了应对这些挑战,Guo等人(90)使用SAE从MR前列腺图像中学习分级特征表示。学到的特征被集成到一个稀疏的图像块匹配框架(a sparse patch-matching framework)中,从而在图像图集中找到相应的图像块用于标签传播(label propagation)(91)。最后,通过将形状先验信息与稀疏图像块匹配得到的前列腺似然图相结合,利用可变形模型对前列腺进行分割。图7显示了由三种不同的特征表示产生的来自不同患者的典型前列腺分割结果。
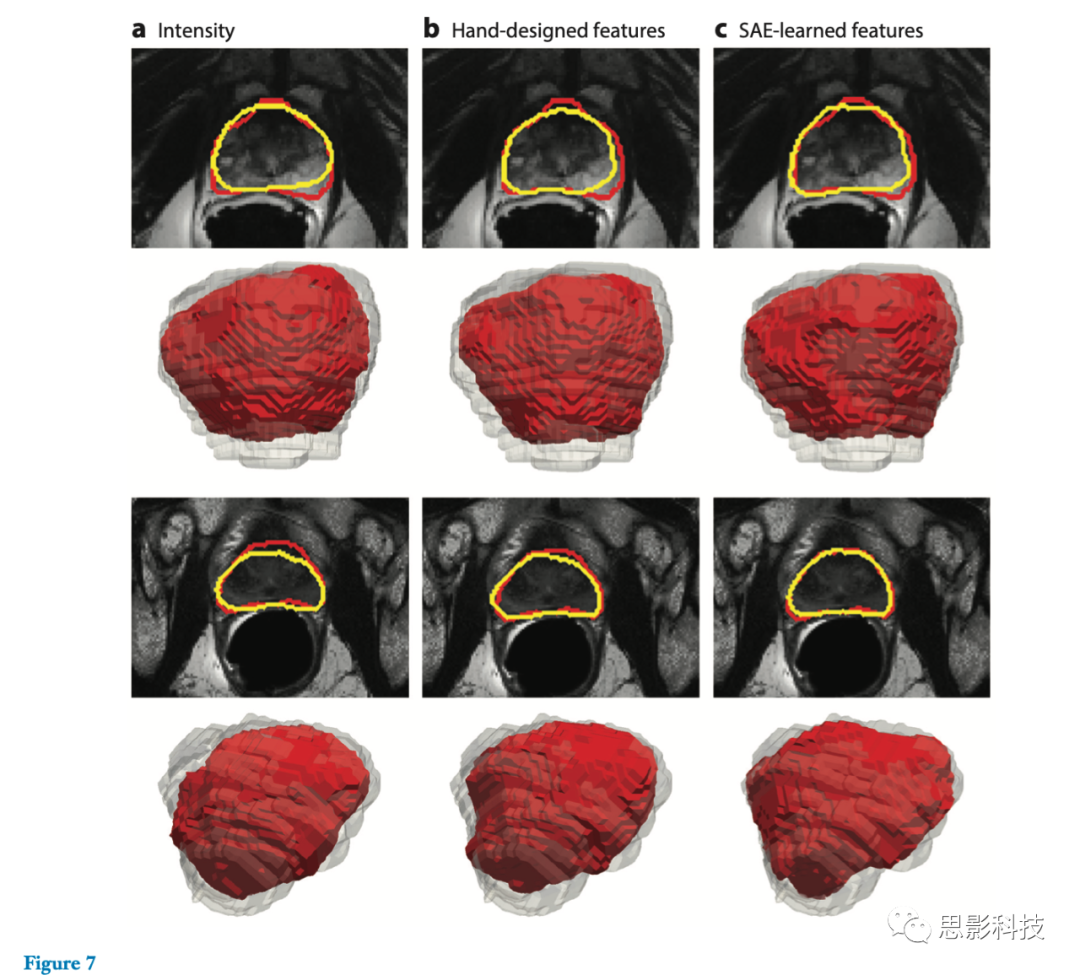
图7.由三种不同的特征表示产生的两个不同患者的典型前列腺分割结果。红色轮廓表示手动标注分割,黄色轮廓表示自动分割。第二和第四行表示对应于上述图像的分割结果的三维(3D)可视化。对于每个3D可视化,红色表面表示使用不同特征(例如灰度(intensity)、手动设计特征和堆叠自动编码器(SAE)学习特征)的自动分割结果。透明的灰色曲面表示手动标注分割。
上述应用表明:
(a) 通过深度学习推断出的潜在特征表示可以成功地描述局部图像特征;
(b) 研究人员可以通过使用深度学习框架来学习固有特征表示,从而快速开发新的医学图像模态的图像分析方法;
(c) 整个基于学习的框架可以适用于学习成像特征表示,并扩展到各种医学图像应用,如MR图像中的海马分割(92)和前列腺定位等(89,90)。
3.2 深度学习在解剖结构检测中的应用
医学图像中解剖结构的定位和插值是放射学工作流程中的关键步骤。放射科医生通常通过识别某些解剖特征来完成这些任务,即可以将一个解剖结构与其他解剖结构区分开来的图像特征。计算机有可能自动学习这样的解剖特征吗?计算机方法的成功本质上取决于通过计算操作可以提取多少解剖特征。尽管早期的研究通常通过创建特定的图像滤波器(image filters)来提取解剖特征,但最近的研究表明,基于深度学习的方法已经变得流行起来,原因主要有两个:(a)深度学习技术现在已经足够成熟,可以解决现实世界中的问题;(b)越来越多的医学图像数据集变得容易获取,为探索医学图像大数据提供了便利。
3.2.1 器官和身体部位检测
Shin等人(51)利用SAE分别学习视觉和时间特征,以便在来自两项肝转移研究和一项肾转移研究的数据集上的3D动态增强MRI扫描的时间序列中检测多个器官。与传统的SAE不同,本研究中的SAE在每一层之后增加了池化操作,使得输入区域逐渐增多的特征基本上都被压缩。因为不同的器官类别有不同的属性,所以作者训练了多个模型,以有监督的方式将每个器官从所有其他器官中分离出来。
Roth等人(93)提出了一种利用深度卷积网络对医学图像进行器官或身体的一部分特定解剖分类的方法。具体地说,他们通过使用4298个轴向2D CT图像来训练他们的深度网络,以学习身体的五个部位:颈部、肺部、肝脏、骨盆和腿部。他们的实验结果中,解剖学特异性分类误差仅为5.9%,平均AUC值(受试者-操作特征曲线下的面积)为0.998。然而,现实世界的应用程序可能需要比仅用于身体五个部位的更细粒度的区分(例如,它们可能需要从心脏切片中识别主动脉弓)。为了解决这一限制,Yan等人(94,95)用CNN设计了一个多状态深度学习框架来识别横切面的身体部分。因为每个切片可以包含多个器官(包围在边界盒(bounding boxes)中),所以CNN以多实例方式(96)训练,其中目标函数被调整,使得只要一个器官被正确标记,相应的切片就被认为是正确的。 因此,预先训练好的CNN对判定性边界盒(discriminative bounding boxes)很敏感。在预先训练的CNN应答的基础上,判定性和非信息性的边界盒被选择出来,以进一步提高预先训练的CNN的表征能力(representation power)。在运行时,采用滑动窗口的方法将增强(boosted)的CNN应用于受试图像。因为CNN只有在判定性的边界盒上才有尖峰响应,所以它基本上是通过关注最有区分度的局部信息来识别身体部位。与基于全局图像的方法(global image context-based approaches)相比,这种局部方法具有更高的准确性和鲁棒性。这些作者在7489张CT层上对12个身体部位进行了测试,这些CT层来自于675名年龄从1岁到90岁不等的患者的扫描。整个数据集被分成三组:2413(225名患者)用于训练,656(56名患者)用于验证,4043(394名患者)用于测试。3.2.2 细胞检测
组织病理学数字化最近已被用于显微镜检查和疾病自动分级。显微图像分析的一个主要挑战是需要分析所有单个细胞以进行准确诊断,因为大多数疾病级别的分化强烈依赖于细胞水平的信息。为了应对这一挑战,研究人员利用深度CNN从组织病理图像(37,38,53,54,97-99)中鲁棒而准确地检测和分割细胞,这将大大有助于癌症诊断的细胞水平分析。
在一项开创性的研究中,Cireş等人(37)使用深度CNN检测乳腺癌组织学图像中的有丝分裂。他们的网络通过一个以图像块(patches)为中心的像素,被训练为可以在图像中对每个像素进行分类。他们的方法在2012年国际模式识别(ICPR)有丝分裂检测大赛中获胜,以显著优势超过其他4名参赛者。
从那之后,不同的小组使用了不同的深度学习方法来检测组织学图像。例如,Xu等人(54)使用SAE检测乳腺癌组织图像上的细胞。为了训练他们的深度模型,他们使用了一个去噪自动编码器来提高对异常值和噪声的鲁棒性。Su等人(53)还使用SAE以及稀疏表示从显微图像中检测和分割细胞。Sirinukunwattana等人(100)提出了一种空间受限的细胞神经网络(constrained CNN,SC-CNN)来检测和分类组织病理学图像中的细胞核。他们使用SC-CNN来估计像素成为细胞核中心的可能性,其中具有高概率值的像素在空间上被限定在核中心附近。他们还开发了一种与CNN相结合的邻近集成预测器,以便更准确地预测被检测到的细胞核的类别标签。Chen等人(38)利用全CNN技术设计了一种深级联CNN,用全卷积核代替了全连接层(101)。他们首先训练了一个粗略的检索模型来识别和定位有丝分裂候选者,同时保持高灵敏度。然后,在检索到的候选者的基础上,他们通过调用在大型自然图像数据集上学习到的深度的和丰富的分级特征来创建精细判别模型,以区分有丝分裂和硬模仿(hard mimics)。他们的级联CNN在2014年ICPR MITOS-ATYPIA挑战赛中达到了最高的检测准确率。
3.3 深度学习在分割中的应用
脑图像的自动分割是对各个年龄段的患者进行大脑定量评估的前提。脑图像预处理的一个重要步骤是去除非大脑区域,如头骨。虽然目前的方法在非增强的T1加权图像上显示了良好的效果,但当应用于其他模态和病理改变的组织时,自动分割仍然很困难。为了绕过这些限制,Kleesiek等人(27)使用3D卷积深度学习结构进行颅骨提取,该技术不局限于非增强的T1加权MR图像。在训练3D CNN时,为了提高计算效率,他们构建了多个立方体(cubes)的迷你批次(minibatches),这些立方体比3D CNN的实际输入要大。他们的深度模型可以通过构建全卷积网络(101)来将任意大小的3D图像体(patch)作为输入;因此,输出可以是每个输入的预测块,而不是像传统的CNN中那样的单个预测。在四个不同的数据集上,与六种常用工具(即BET、BEAST、BSE、ROBEX、HWA和3dSkullZone)相比,他们的方法实现了最高的平均特异性度量,而其灵敏度约为平均水平。
Moeskops等人(102)设计了一种多尺度细胞神经网络来增强新生儿图像分割的鲁棒性和空间一致性。他们的网络使用多尺寸的图像块及不同大小的卷积核来获取关于每个体素的多尺度信息。使用这种方法,作者在8种类型的组织分割中获得了令人满意的结果,在5个不同的数据集上,Dice Ratio平均为0.82到0.91。
人脑发育最活跃的阶段是出生后第一年,其特点是大脑组织快速生长和发育,认知及运动功能广泛发展。将婴幼儿脑部MRI图像准确分割为白质(WM)、灰质(GM)和脑脊液(CSF)是研究早期脑发育正常和异常的关键。由于组织对比度低(103)、噪声多、且具有严重的部分容积效应(104)和正在进行的WM髓鞘形成(103,105),婴儿大脑MR图像的分割比成人要困难得多。WM和GM表现出几乎相同的灰度水平(特别是在大脑皮层区域),导致图像对比度较低。虽然已经提出了许多婴儿脑图像分割的方法,但大多数集中在使用单个T1加权或T2加权图像来分割新生儿(∼3个月)或婴儿(>12个月)的图像(106-110)。很少有研究解决等强度相位图像(isointense-phase images) (大约6个月大)分割带来的挑战。
为了克服这些困难,Zhang等人(26)设计了四种基于多模态MR图像的CNN结构来分割婴儿脑组织。每个CNN包含对应于测量13×13体素的T1加权、T2加权和分数各向异性(FA)图像块的三个输入特征图。作者对每个CNN应用了三个卷积层和一个全连接层,最后是一个具有Softmax函数的输出层,用于组织分类。在一组手动分割的等强度相位脑图像上,这些CNN的表现明显优于竞争方法。
最近,Nie等人(48)提出使用多个完全卷积网络(MFCNs)(图8)来分割具有T1加权、T2加权和FA模态信息的等强度相位脑图像。他们不是简单地组合来自原始(低级)特征图的三个模态数据,而是采用深层架构来有效地融合来自所有三个模态的高层信息。他们假设来自不同模态的高级表示是相辅相成的。首先,作者为每个模态训练一个网络,以便有效地利用来自多个模态的信息;其次,他们融合了来自每个网络高层(high layer)的多个模态特征(图8)。在这些实验中,mFCNs利用来自8个受试者的图像,实现了以下平均Dice ratios:脑脊液0.852,GM 0.873,WM 0.887,优于全卷积网络和其他竞争方法。
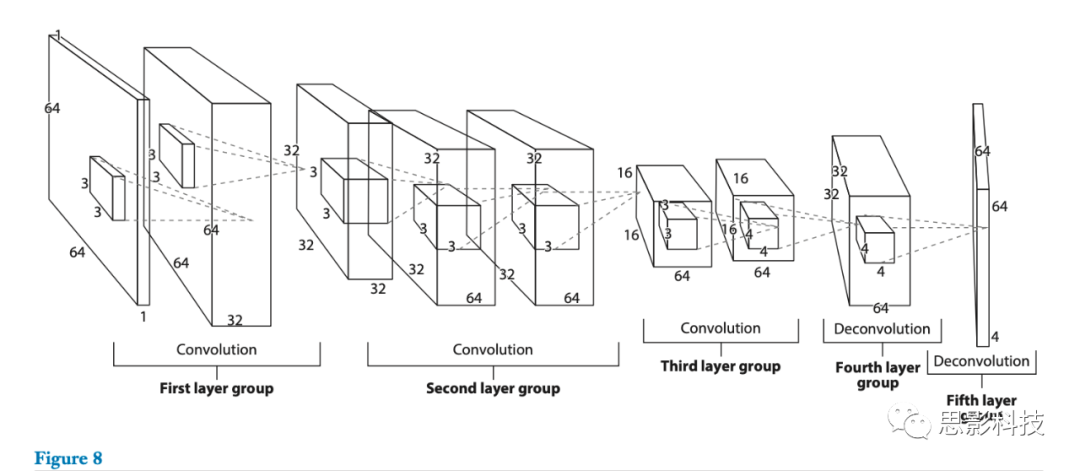
图8. 参考文献48中用于组织分割的全卷积网络的体系结构。
3.4 深度学习在计算机辅助检测(Computer-Aided Detection,CADE)中的应用
CADE的目的是发现或定位结构图像中的异常或可疑区域,从而对临床医生起到提示作用。CADE旨在提高病变区域的检出率,同时降低假阴性率,而这些可能是由观察者的错误或疲劳造成的。虽然CADE在医学图像方面已经有了很好的基础,但是深度学习方法在不同的临床应用中都提高了它的性能。
通常,CADE应用于如下场景:(a)通过图像处理技术检测候选区域;(b)候选区域由诸如形态学或统计信息之类的一组特征来表示;以及(c)将特征送入支持向量机(SVM)等分类器中,从而输出罹患疾病的概率或做出是否存在疾病的判定。如第1节所述,人工设计的特征表示可以合并到深度学习中。许多小组已经成功地将自己的深度模型应用于肺结节的检测、淋巴结的检测、CT图像中间质性肺疾病的分类、脑微出血的检测以及MR图像中的多发性硬化症病变的检测。值得注意的是,文献中描述的大多数方法利用深度卷积模型来最大限度地利用二维、两维半或三维的结构信息。
Ciompi等人(43)使用预先训练好的OverFeat(111)作为特征提取器,经验表明,从完全不同的自然图像域学习的CNN可以为肺周围结节的分类提供有用的特征描述。Roth等人(40)专注于从头开始训练深度模型。为了解决深度CNN训练中数据不足的问题,他们通过对随机过度训练样本(random overtraining samples)进行缩放、平移和旋转来扩展数据集。他们以类似的方式增加测试样本;获得每个增加的测试样本的CNN输出;并取随机转换、缩放和旋转的图像块的输出的平均值,用于检测淋巴结和结肠息肉。为了更好地利用图像中的体积信息,Ciompi等人(43)和Roth等人(40)都考虑了具有三个正交视图(轴向、矢状面和冠状面)的2D块的2.5维(2.5D)信息。Setio等人(42)考虑了来自3D图像块的总共9个视图的三组正交视图,并使用集成方法融合来自不同视图的信息以检测肺结节。
Gao等人(112)利用CNN对间质性肺病的CT表现进行了整体分类。他们借用了参考文献113的网络结构,输出层有6个单元,将图像块分类为正常、肺气肿、磨砂玻璃、纤维化、微结节和实变。为了克服过度拟合的问题,他们使用了一种数据增强策略,通过随机抖动(randomly jittering)和将每个原始CT切片裁剪为10个子图像来生成图像。在测试阶段,他们生成了10张抖动的图像,并将它们输入到经过训练的CNN。最后,他们通过聚合来预测输入切片,类似于Roth等人的研究(40)。
Shin等人(45)在胸腹淋巴结(thoraco-abdominal lymph node)检测和间质性肺病分类的数据集上进行了实验,以探索CNN的性能如何根据体系结构、数据集特点和迁移学习而变化。他们考虑了五个深度CNN,即CifarNet(114)、AlexNet(113)、OverFeat(111)、VGG-16(115)和GoogLeNet(116),它们在各种计算机视觉应用中取得了最先进的性能。通过大量的实验,这些作者得出了一些有趣的结论:(a) 从大规模注释自然图像数据集(ImageNet)中学习的特征的迁移对CADE问题始终是有利的;(b)通过探索人为设计的特征的性能互补特性,可以改进现有的深度CNN特征在CADE问题中的应用。
与上述使用确定性深度结构的研究不同,van Tulder和de Bruijne(35)采用了以卷积RBM为基础的深度生成模型来对间质性肺病进行分类。具体地说,他们使用带有附加标签层的输入层和隐藏层的判别性RBM来提高学习特征表示的判别力。这些实验证明了生成性和判别性学习目标相结合的优势,比单纯的生成性或判别性学习方法的表现更好。
Pereira等人(34)做了利用CNNs分割MR图像中的脑肿瘤的研究。为了在使用更少参数的情况下形成更深层次的架构,他们探索了小型核(kernels)的使用。他们针对低级别和高级别肿瘤训练了不同的CNN架构,并在2013年脑瘤分割(BRATS)挑战赛中验证了他们的方法,在挑战赛数据集的完整、核心和增强区域中,他们的方法名列前茅。Brosch等人(49)将深度学习应用于MR图像上的多发性硬化症病变分割。他们的模型是由两条相互连接的路径组成的三维CNN,即一个学习到类似于其他CNNs的分级特征表示的卷积路径和包含与相应卷积层有捷径连接的反卷积层及反池化层的反卷积路径。反卷积层被设计成根据每个卷积层的特征表示和前一个反卷积层的激活(如果适用的话)来计算抽象分割特征。与目前已有的5种多发性硬化病变分割方法相比,该方法在Dice相似系数、绝对体积差和病变假阳性率三个方面都取得了最好的效果。
对于典型的深度CNN,一个重要限制来自于其模型本身的固定体系结构。当输入的观测值大于输入层中的单元时,直接的解决方案是应用滑动窗口策略(sliding-window strategy)。但是这样做在计算上非常昂贵,并且耗费时间/内存。由于CNNs中存在这种尺度问题,Dou等人(36)通过将全连接层中的单元转换为3D(1×1×1)可卷积核来设计了3D全连接网络,使其能够有效地处理任意大小的输入(101)。此3D全连接网络的输出可以重新映射回原始输入,从而可以更直观地解释网络输出。为了检测磁共振图像中的脑微出血,学者们设计了一个级联框架。他们首先用提出的3D全连接网络对输入进行筛选,以检索出大脑微出血的高概率候选对象,然后应用3D CNN判别模型进行最终检测。这些实验验证了该方法的有效性,消除了大量的冗余计算,大大加快了检测过程。
3.5 深度学习在计算机辅助诊断(Computer-Aided Diagnosis,CADx)中的应用
CADx从基于图像的信息中提供了关于疾病评估的第二种客观意见。CADx的主要应用包括鉴别良恶性病变及从一幅或多幅图像中识别某些疾病。通常,大多数CADx系统都是为了使用由领域专家设计的人工设计特性而开发的。近年来,深度学习方法已成功地应用于CADx系统中。
Cheng等人(39)使用带去噪技术(SDAE)的SAE来区分乳腺超声病变和肺部CT结节。首先将图像感兴趣区域(ROI)的大小调整为28×28,其中每个图像块中的所有像素都被视为SDAE的输入。在预训练阶段,作者用随机噪声破坏输入图像块,以增强其模型的噪声容忍度。随后,在微调步骤中,它们加入了两个ROI维度的尺度调整因子及原始ROI的尺寸比,以保留原始信息。Shen等人(41)用多尺度CNN创建了一个分级学习框架来捕捉不同大小的肺结节。在该CNN结构中,三个以不同尺度的结节图像块为输入的CNN被并行组装。为了减少过拟合,作者将三个CNN的参数设置为在训练期间共享。将三个CNN中最高隐层的激活(每个尺度一个)连接起来,形成一个特征向量。对于分类,作者使用具有径向基函数核的支持向量机(SVM)和随机森林,该分类器被训练为伴生目标最小化,所述伴生目标定义为总体铰链损失函数( hinge loss function)和伴生铰链损失函数的和(117)的组合。
Suk等人(31)利用SAE,通过融合神经成像和生物学特征来识别阿尔茨海默病或轻度认知障碍。他们从MR图像中提取GM体积特征,从PET图像中提取区域平均强度值,从脑脊液中提取三个生物学特征(Aβ42, p-tau, and t-tau)。在训练特定模态的SAE之后,对于每个模态,它们通过将原始特征与各个SAE的顶层隐层的输出相连接来构造增广的特征向量。一个多核支持向量机(118)进行了临床决策训练。相同的作者将他们的研究扩展到通过在特征表示学习期间而不是在分类器学习步骤(29)中组合不同的模态来寻找分级特征表示。他们使用DBM从3D图像块中找到潜在的分级特征表示,然后设计了一种系统的方法,用于从具有多模态DBM的MRI和PET的配对图像块中进行联合特征表示(图9a)。为了提高诊断性能,他们还使用了判别DBM,在最高隐层的顶部添加了判别RBM(119)。也就是说,顶部隐层同时连接到输入图像块中的下层隐层和指示标签的附加标签层(图9a)。使用这种方法,作者训练了一个多模态DBM,通过融合发现特征及其在分类中的使用来发现分级和判别特征表示。图9b,c显示了从MRI路径和PET路径学习到的连接权重。
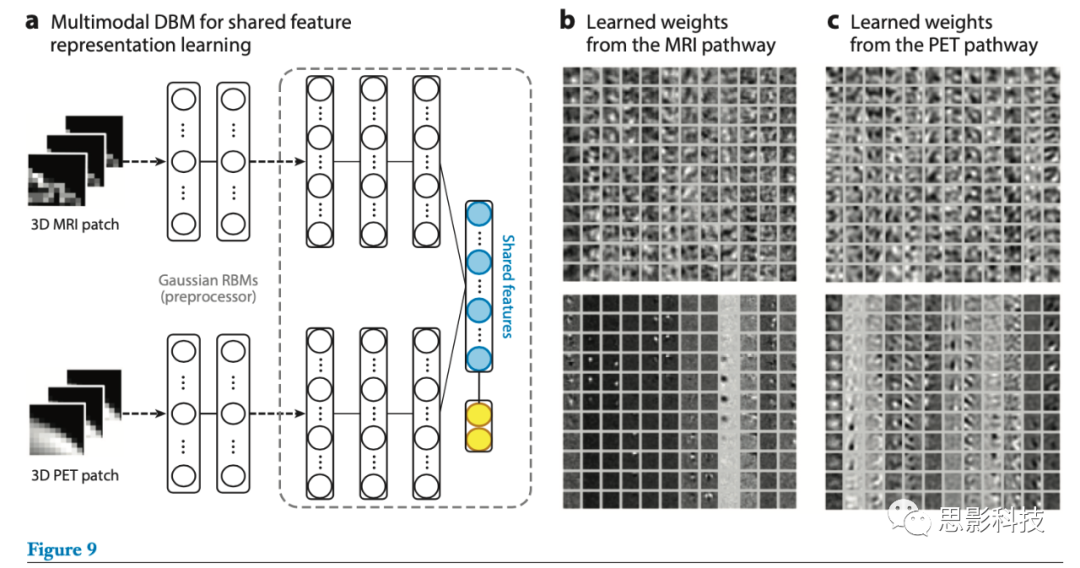
图9.(a)利用多模态深度Boltzmann判别机(DBM)从不同模态的图像块(例如磁共振成像(MRI)和正电子发射断层扫描(PET))进行共享特征学习。黄色圆圈表示输入图像块,蓝色圆圈表示联合特征表示。(b,c)为多模态DBM(29)中高斯受限Boltzmann机器(RBM)(底部)中的学习权重和来自MRI第一隐藏层(顶部)及PET路径的学习权重(顶部)的可视化。每列由上块和下块中的11个图像块组成一个三维图像体。
Plis等人(120)将DBN应用于MR图像,通过调查一个深度生成模型的构建块是否能与功能MRI中最广泛应用的独立元分析进行竞争,来验证应用的可行性。他们还检查了深度模度的深度对精神分裂症(aschizophrenia)数据集和亨廷顿病(Huntington disease)数据集的结构磁共振图像分析的影响。受到Plis等人工作的启发,Kim等人(121)和Suk等人(33)独立研究了深度学习在基于fMRI的大脑疾病诊断中的应用。Kim等人在精神分裂症的诊断及与精神分裂症相关的异常功能连接模式的识别中使用SAE作为全脑静息状态功能连接模式表征。他们首先根据区域平均血氧水平依赖(BOLD)信号计算了116个区域对之间的皮尔逊相关系数。在对系数进行Fisher r-to-z变换和高斯归一化之后,他们将伪z得分水平反馈到他们的SAE中。
最近,Suk等人(33)提出了一种将深度学习与隐马尔可夫模型(hidden Markov model,HMM)相融合的fMRI功能动力学估计的新框架,并成功地将该框架用于轻度认知损伤(MCI)的诊断。他们设计了一个深度自动编码器(DAE),通过堆叠多个RBM来发现大脑区域之间的分级非线性功能关系。图10以功能网络的形式展示出了学习到的连接权重的示例。该DAE用于将区域平均BOLD信号变换到嵌入空间,嵌入空间的基础被理解为复杂的函数网络。在嵌入功能信号之后,Suk等人。然后利用隐马尔可夫模型(HMM)通过内部状态估计静息状态fMRI固有的功能网络的动态特性,这些动态特性可以从观测数据中统计推断出来。通过用隐马尔可夫模型(HMM)建立生成模型,他们估计了静息状态fMRI的输入特征属于相应状态(即MCI或正常健康对照)的可能性,然后使用这一信息来确定测试对象的临床标签。
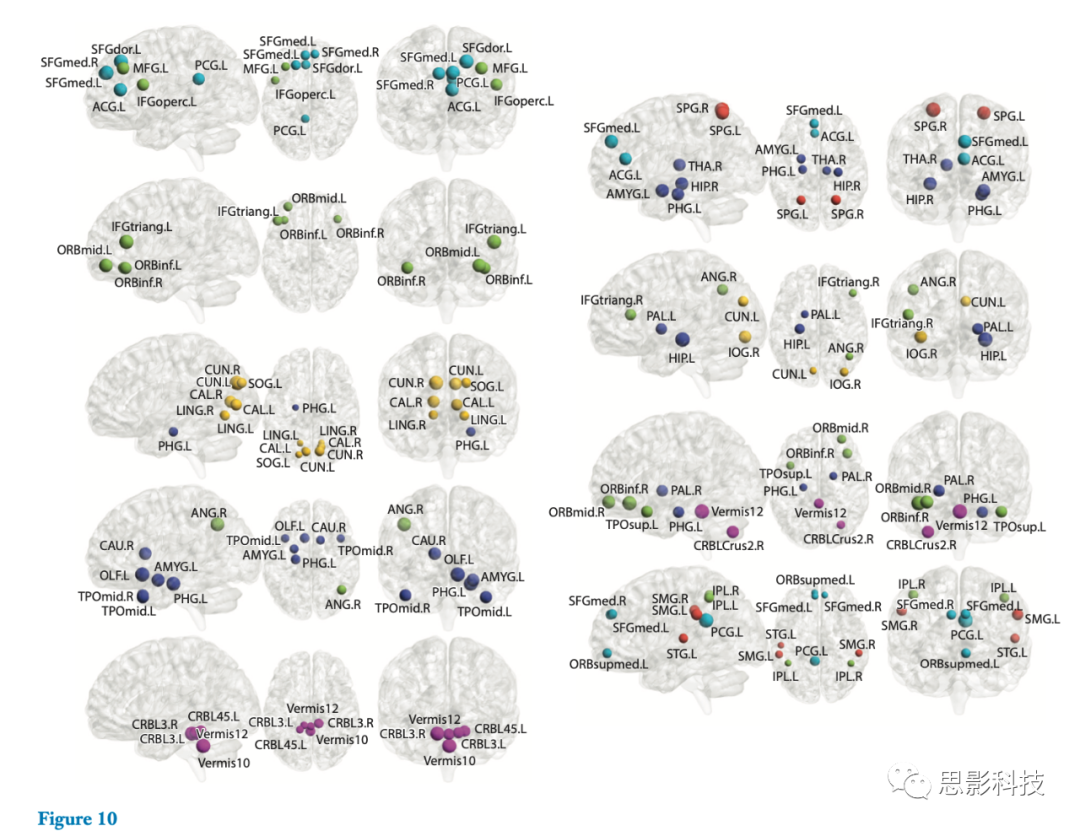
图10. 参考文献33中的深度自动编码器构建的从第一隐层学习到的功能网络。左栏中的功能网络(从上到下)对应于默认模式网络、执行注意网络、视觉网络、皮质下区域和小脑。右栏中的功能网络显示了不同网络区域、大脑皮层和小脑之间的关系。
一些其他研究也使用CNNs来诊断大脑疾病。Brosch等人(47)使用由三个卷积RBM和两个RBM层组成的深度生成模型,从下采样的MR图像中进行流形学习。卷积计算的速度是训练算法的瓶颈,为了加快速度,他们在频域进行训练。通过从他们的深度生成模型生成体素样本,他们验证了在没有明确定义的相似性度量或邻近图(proximity graph)的情况下,流形嵌入(manifold embedding)深度学习的有效性。Li等(44)构造了一个具有两层卷积层和一层全连接层的三层CNN。他们建议使用CNNs来集成多模态神经成像数据,方法是设计一个3D CNN结构,接收一个体积MRI图像体(patch)作为输入,另一个体积PET图像块(patch)作为输出。当利用受试者的两种数据模态进行端到端的训练时,网络可以捕捉到两种模态之间的非线性关系。这些实验表明,给定输入的MRI数据,PET数据是可以预测和估计的,并且作者通过将预测的PET图像与实际的PET图像的分类结果进行比较,对所提出的数据补全方法进行了定量的评估。
4. 结论
医学图像分析的计算建模对临床应用和科学研究都有着重要的影响。深度学习的最新进展使仅从数据中发现图像中的形态和/或纹理模式成为可能,从而为医学图像分析带来了新的曙光。深度学习方法在不同的医疗应用中实现了最先进的性能,但仍有进步空间。
首先,如计算机视觉中所证明的,通过使用大量的训练数据(例如,ImageNet(24)中的100多万个带注释的图像)可以实现突破性的进步,深度模型也可以从大型、公开可用的医学图像数据集中找到更一般化特征,从而实现更高的性能。
第二,虽然数据驱动的特征表示帮助提高了准确性,特别是以无监督的方式,但设计一种涉及特定领域知识的新的方法体系结构是可取的。
第三,有必要开发算法技术来有效地处理用不同扫描协议获取的图像,这样就不需要训练特定于模态的深度模型。
最后,当使用深度学习来研究fMRI等图像中的潜在模式时,由于深度模型的黑匣子特性,直观地理解和解释学习到的模型仍然具有挑战性。
原文:Deep Learning in Medical Image Analysishttps://doi.org/10.1146/annurev- bioeng- 071516- 044442
。

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
更新通知:第十届脑影像机器学习班(已确定)
磁共振脑影像结构班(预报名)
弥散磁共振成像数据处理提高班(预报名)
小动物磁共振脑影像数据处理班(预报名)
更新通知:第二十届脑电数据处理中级班(已确定)
脑电信号数据处理提高班(预报名)
眼动数据处理班(预报名)
近红外脑功能数据处理班(预报名)
数据处理业务介绍:
招聘及产品:
招聘:脑影像数据处理工程师(重庆&南京)