

自闭症谱系障碍(ASD,Autism spectrum disorder )是一种神经发育障碍,患病率为1-2%。特别是在低资源环境中,对ASD的早期识别和诊断是一个重大挑战。因此,ASD迫切需要一种“语言自由、文化公平”,并且不需要专业人员参与的低成本筛选工具。在ASD和神经发育障碍中,EEG可用来寻找生物标记物。其中,关键挑战之一是确定适当的多元下一代分析方法(multivariate, next-generation analytical methodologies),这些方法可以描述大脑中复杂的非线性神经网络动态性,同时也考虑到可能影响生物标记物发现的技术和人口学混淆因素。开普敦大学儿童和青少年精神病科T. Heunis和P. J. de Vries等人在BMC Medicine杂志发文,评估定量递归分析(RQA,recurrence quantification analysis )作为ASD潜在生物标记物的稳健性,并对一系列潜在的技术和人口混杂因素进行系统的方法学探索。
研究方法:对连续5s/时间段的静息态EEG(rsEEG,resting state EEG)数据进行RQA特征提取,并测试线性和非线性分类器。为防止样本偏差、技术和人口统计学混淆因素的影响,数据分析的样本分为:16个ASD和46个正常发育(TD)个体的完整样本、16个ASD和19个TD儿童的子样本、以及7个ASD和7个TD儿童的年龄匹配样本。使用留一交叉验证分类法(leave-one-subject-out method)模拟诊断一个未知被试的临床场景。
研究结果:在年龄匹配样本中,从TD中区分出ASD,使用非线性支持向量机(SVM)分类器的留一分类法结果显示92.9%准确率,100%敏感性和85.7%特异性。将年龄、性别、智力水平以及每组训练和测试部分的数据数量定义为可能的人口和技术混淆因素。一致的重复性(正确识别每个被试的所有时间段)仍是个挑战。
研究结论:在年龄匹配样本中,rsEEG的RQA(评估定量递归分析)是一种精确的ASD分类器,这反映出了该方法在ASD筛选中的潜在作用。然而,这项研究还在实验方面揭示了一系列技术挑战,以及人口学混杂因素如何扭曲结果,并强调在未来研究中探索这些因素的重要性。研究者建议在因素匹配的婴儿和儿童大样本中验证此方法,尤其是在低收入和中等收入环境中进行验证。
研究背景
理想的生物标记物应是容易获得的、准确的、大众可以承担得起的,并且对区分不同群组具有高度的敏感性和特异性。该研究对EEG作为ASD和相关神经发育障碍的潜在生物标记物提出了挑战:
1)描述一系列潜在的人口学、临床和技术混淆因素,包括年龄、性别、智力、社会经济地位、共发病、药物的使用、睁眼与闭眼的情况、电极的数量和位置以及测试-重测的可靠性。这些因素均需要评估,EEG生物标记物才是足够可靠的,才能应用于临床环境。
2)描述在确定适当的、多元、下一代分析方法方面的关键技术挑战,这些方法可以描述大脑中复杂的非线性神经网络动态性。
识别ASD风险的三种新的潜在rsEEG生物标记物包括:
1)采用修正的(modified)多尺度熵方法(multiscale entropy; MME)对rsEEG进行分析,比较ASD高风险婴儿(HRA,high risk for ASD, 有一个患ASD的兄弟姐妹)和TD婴儿。准确率为80-100%,但婴儿从12个月到24个月,准确率下降。有研究者反对该发现,因为只有小部分HRA婴儿会发展成为ASD。
2)频谱相干分析(spectral coherence analysis; CA)作为ASD的生物标记物。在430名ASD患者和554名TD儿童的二分类中,准确率为86%和88.5%。在限制年龄的子样本中,准确率提高。在ASD与TD的二元分类中,CA生物标记物方法有用,但关于生物标记物发展的临床和分析问题仍未得到解答。
3)RQA(评估定量递归分析)作为ASD分类的新的生物标记物。RQA是EEG应用领域一种新兴的非线性数据分析技术。这项技术是基于大脑等复杂系统固有的递归的基本特性。在之前的原理论证分析中,对7名ASD和5名TD被试的RQA进行研究,并对12个好的分段进行分析。结果表明,线性判别分析(LDA)分类器的准确率为83.3%,敏感性为85.7%,特异性为80%。
该研究的目的是在大样本中重复和延伸先前研究结果,并在系统的方法学探索中,将一些变量作为协变量或混杂因素,研究潜在的RQA生物标记物的稳健性。研究者细化生物标记物参数,评估生物标记物的潜在混杂因素,如年龄,性别和智力水平,以识别分类的准确率,敏感性和特异性;并探索RQA生物标记物的测试-重测可靠性。使用留一分类法模拟一个未知被试的临床场景。因此,这项工作的新颖性在于RQA在rsEEG的多元应用,以发现早期ASD的风险性,并在准确率、敏感性和特异性方面对潜在的技术和人口混杂因素进行系统评估。
方法
递归分析:
递归图(RP)可以在二维图中使高维相位空间可视化,可用来描述系统的基本动力学特征。根据公式(1),使用每个样本对i和j的时间序列x以及具体的阈值距离ε(邻域大小),计算递归事件,并储存在N×N矩阵中(用于构建RP)。在坐标(i, j)处的RP,当递归事件(Ri,j = 1)出现时,画黑点;无事件时(Ri,j=0)画白点。

将RQA应用于RPs提供了一个定量系统动力学的客观测量。从RPs可以提取几个特征,例如:递归率(RR;任何状态再次出现的概率)、决定论(DET;表明系统的可预测性)、熵(ENTR;提供递归结构的复杂性度量)和分层性(LAM;下一步,状态不会改变的概率)。Marwan et al.和Schinkel et al.为RPs和RQA特征提供了进一步的数学细节。
编者注:RQA的具体数学细节也可参考更早的一篇文章(如需原文可添加微信siyingyxf或19962074063获取)
被试:
从美国波士顿儿童医院和洛杉矶加州大学塞梅尔研究所获得rsEEG数据。16名非综合征ASD患者(2-6岁)和46名TD(正常发育)被试(0-18岁)。收集每个被试的年龄、性别并测试智力水平。
Table 1 人口学特征和样本组成

EEG信号处理方法:
EEG信号处理流程主要包括:数据采集、预处理、特征提取和分类,参见Fig.1。流程细节在后续详述。

Fig. 1 EEG信号处理方法
数据获取:
从常规临床EEG记录或长期EEG监测中收集EEG数据,数据来源于两个研究机构。波士顿儿童医院的数据:使用Biologic记录系统(采样率为256-512Hz,带通滤波为0.1-100Hz)或Natus Neuroworks系统(采样率为200Hz,带通滤波为0.1-100Hz),19个标准电极((Fp2, Fp1, F4, F3, Fz, C4, C3, Cz, P4, P3, Pz, F8, F7, T8, T7, P8, P7, O2, O1)。加州大学洛杉矶分校的数据:使用EGI 128导联系统、NetAmps Amplifiers和NetStation软件(采样率为250Hz)采集数据,并且采用National Instruments Board进行数字化。所有EEG系统均采用标准10-20电极定位。
数据预处理:
1. 原始数据进行分段,删除包含伪迹的时间段;
2. 进行60Hz的陷波滤波,重采样为200Hz,空间降采样为标准的临床19个电极点。由于Fp1和Fp2主要包含眼部伪迹信息,因此在进一步分析中删除这两个电极。17个电极用于后续的多元分析。
3. 使用BESA Rsearch 3.5软件对数据进行平均参考。
4. 使用EEGLAB工具包中的FIR滤波器(1-70Hz)对数据进行滤波。儿科神经科医生和临床神经生理学家检查数据,手动删除伪迹段(长度至少2min),并且挑选清醒的无任务数据。有可能的话,也删除肌电伪迹。采用EEGLAB中的ICA方法进行眼电伪迹矫正。
5. 提取每个被试所有连续5s的可用数据。
特征提取:
1. 采用多元嵌入方法,利用17个电极点和时间滞后嵌入方法构建EEG动态的相位空间表征。对每个被试每个时间段创建多通道滞后轨迹矩阵,每列嵌入相同的滞后和维度,然后水平拼接形成多通道滞后轨迹矩阵。使用每个被试所有可用的连续5s时间段。
2.使用PCA方法对每个多通道滞后轨迹矩阵进行降维。使用每个主成分(PC)向量重建多维相位空间中的吸引子。
3. 使用The Cross Recurrence Plot MATLAB工具包画RPs(递归图),并且从每个被试的多维约简嵌入段矩阵中提取10个RQA特征。提取的10个RQA(Table S1)分别是:RR, DET, 平均对角线长度, 最长对角线, ENTR, LAM, 捕获时间, 最长垂直线, 第一次Poincaré递归的递归时间(T1),第二次Poincaré递归的递归时间(T2)。用Kolmogorov–Smirnoff和Wilcoxon秩和检验(分布和形状)分析训练数据特征的特征统计显著性。
Table S1 10个RQA特征的具体描述。

采用迭代方法确定最优参数和特征集组合。产生最好分类结果的组合即为最优。对PCA降维后的嵌入滞后、嵌入维数、保留百分比变异(PVR)和RQA邻域大小进行了评价。使用交叉验证run1和“显著RQA特征集”的数据确定最优参数;这些参数值用于所有交叉验证runs。
1. 嵌入滞后:使用每个电极平均互信息指数的第一个最小值评估15-25的嵌入滞后估计。
2. 嵌入维数:使用Quick-Ident MATLAB工具包的假最近邻法计算每个通道的相应最优嵌入维数,并且产生的数值为10。
3. PVR:在测试PVR参数的敏感性时,评估10-100个不同增量的PVR范围。
4. 邻域大小:用最大范数邻域形状定义检测递归事件的邻域,采用“最大相位空间直径的几个百分点”的启发式方法确定邻域大小。以0.1的间隔评估2.0-4.0的邻域大小。考虑到上述启发式的方法以及递归图的视觉检查,初步估计邻域大小为3.0。
在确定最优参数值后,通过特征打乱分析确定最优特征集,以确认所有特征都为分类器提供了用于类成员预测的有用区分信息。
1. 逐一对每个特征的测试标签进行打乱,同时对所有特征进行分类,使用打乱标签对包括相关特征的所有特征集进行分类;
2. 将打乱特征集的分类性能与未打乱特征集的分类性能进行比较。此外,特征被逐个分类,并按特征重要性进行排序;
3. 通过在集合中每次添加一个特征(根据重要性递减的顺序添加)来确定最优特征集。实现最佳分类性能所需的特征被确定为最优集。为了本研究的目的,仅选择显著的RQA特征。然而,这一决定值得怀疑,因为一个特征在组间可能没有统计学意义,但结合其他特征,它可以使分类后的群体区分更加明确。为解决Heunis等人确定的一些临床挑战,将年龄和性别作为协变量进行研究。测试的特征集是所有显著的RQA特征(‘RQA’)、包含显著RQA特征和人口学特征的组合特征集(‘RQA + age’, ‘RQA + sex’, ‘RQA + age + sex’)以及没有RQA特征的人口学特征。使用10折交叉验证分析,研究两个特征集选择:特征集1包括所有显著的RQA特征,特征集2包括所有显著的RQA和人口学特征(包括年龄和性别)。
分类:
采用10折交叉验证(10-fold cross-validation;将“k折交叉验证”中的k=10,即将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。)和留一法(leave-one-subject-out;指将“k折交叉验证”中的k等于数据集中数据的个数,每次只使用一个作为测试集,剩下的全部作为训练集)。使用10折交叉验证方法优化参数值,然后使用留一法验证交叉验证分类的结果,并模拟临床场景,评估“诊断”一个未知被试的结果。10折交叉验证法创建10个训练集和10个测试集。每个训练集和测试集分别包括从每个被试随机选取70%的训练数据和30%的测试数据。由于有14名被试的年龄匹配样本(Table 1),因此,留一法创建14个训练集和14个测试集。每个训练集包括13个被试,测试集包括另外一个被试(14个leave-one-out runs)。按要求对训练数据和测试数据进行标准化(平均值为零,标准差为1)。利用MATLAB实施3种分类算法:
(1)LDA,线性判别分析;
(2)MLP,多层感知机神经网络(multilayer perceptron),一个隐藏层包含9个节点,利用尺度化共轭梯度反向传播训练算法;
(3)SVM,支持向量机,使用非线性径向基核函数。
报告训练和测试数据集中的准确率、敏感性、特异性、样本大小、时间段数量和样本组成(每组中时间段的比例),以便对分类性能结果进行有意义的解释。
编者注:交叉验证是机器学习中的一种常用技术,通常具有两种应用场景:
(1)优化超参数。比如多项式模型,多项式的最高次数便是一个超参数,可以用交叉验证的方式选择使得预测性能最佳的最高次数作为超参数。
(2)评估模型预测精度。超参数确定后,为了量化模型的预测效果,也可以用交叉验证的方式计算一些常见的预测精度指标,比如总预测正确率、敏感性、特异性等。
抽样人口分析:
评估完整样本、子样本以及年龄匹配样本。完整样本包含所有被试;子样本包含年龄在6岁以下的被试;年龄匹配样本要求年龄、性别、智力水平一致。细节参见Fig. 2。
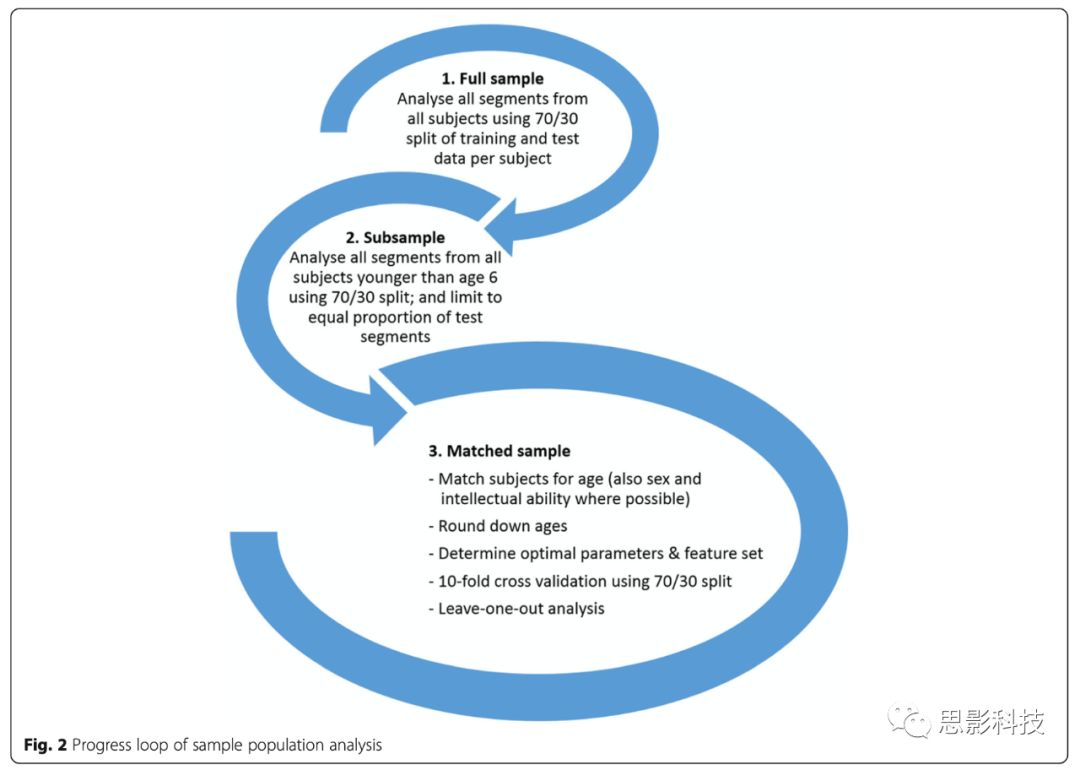
Fig. 2 抽样人口分析的处理
结果
完整样本(交叉验证方法,Fig. 3):
确定的最优参数集:嵌入滞后为25、嵌入维数为10、PVR为22.12(相当于6个PCs)、邻域大小为3.0。MLP分类器结果显示RQA特征集的分类准确率为96.18%,组合特征集的分类准确率为99.08%。结合RQA特征集,年龄和性别似乎是有用的协变量,有助于提高分类准确率。然而,‘年龄’的分类准确率是98.3%,‘性别’的分类准确率是93.92%,‘年龄+性别’的分类准确率是98.66%。考虑到随机样本中的年龄和性别不能预测ASD或TD组成员,这些虚假结果可能是样本偏差。为解决虚假结果问题,选取所有年龄小于6岁的被试子样本进行进一步分析。对完整样本的进一步观察发现rsEEG测试数据时间段中93.9%是TD,6.1%是ASD。为避免对分类结果的误解,在子样本中,每组使用相同数量的测试时间段进行分析,从而使分类器有50/50的机会正确地猜测每组成员。
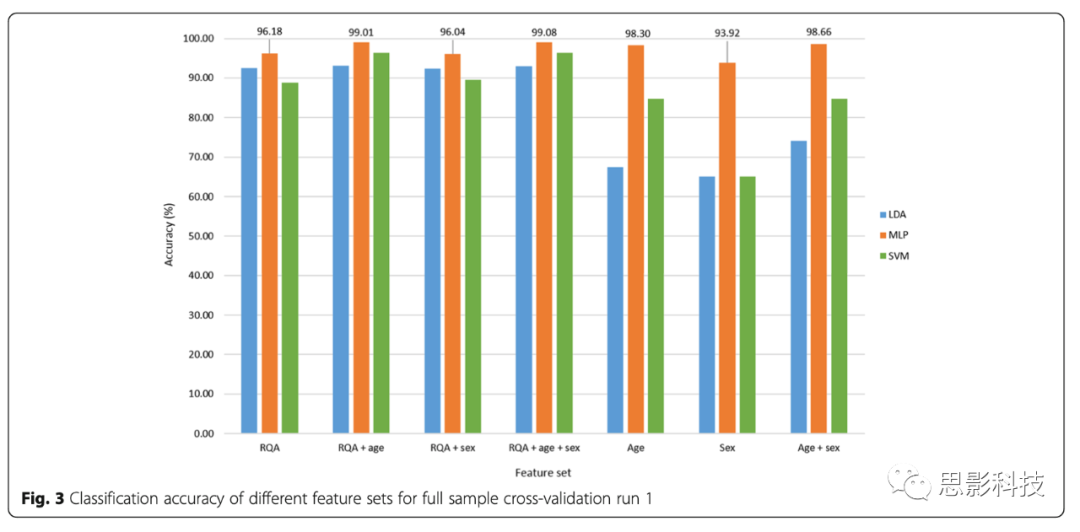
Fig. 3 完整样本交叉验证run1的不同特征集的分类准确率。
子样本(交叉验证法,Fig. 4):
确定的最优参数集:嵌入滞后为25、嵌入维数为10、PVR为12.60(相当于3个PCs)、邻域大小为3.0。SVM分类结果显示RQA特征集的分类准确率为86.63%,组合特征集的分类准确率为96.51%,‘年龄’的分类准确率是83.72%,‘性别’的分类准确率是66.28%,‘年龄+性别’的分类准确率是88.37%。考虑到子样本中年龄和性别的分布情况,人口学特征仍然足以对ASD和TD被试进行分类,其准确率高于“RQA”特征集。因此,样本偏差仍是问题。为解决这个问题,下一步是分析匹配样本。此外,将年龄四舍五入,以防止分类器根据训练数据中的确切年龄值预测组成员。

Fig. 4 子样本交叉验证run1的不同特征集的分类结果
年龄匹配样本:
确定的最优参数集:嵌入滞后为25、嵌入维数为10、PVR为30.09(相当于10个PCs)、邻域大小为2.9。这一邻域大小约占所有交叉验证runs的平均最大相位空间大小(43.13)的6.7%。每次交叉验证run时,都会对训练和测试数据进行不同的随机70/30%拆分,并可能识别出不同的具有统计意义的特征集。临床意义是,一旦为ASD和TD样本中确定了一个稳健范围,根据新提取的RQA特征下降的范围,未知被试就可以被“诊断”为“有ASD的风险”或“TD”(Table 2)。
Table 2年龄匹配样本的交叉验证run1的特征集1的总结

对交叉验证run1的SVM分类结果显示‘RQA’特征集的分类准确率为93.94%,组合特征集的分类准确率为90.91%,‘年龄’的分类准确率是53.03%,‘性别’的分类准确率是63.64%,‘年龄+性别’的分类准确率是63.64%(Fig. 5)。使用年龄匹配样本以及四舍五入的年龄,显著最小化了先前取得的虚假结果。
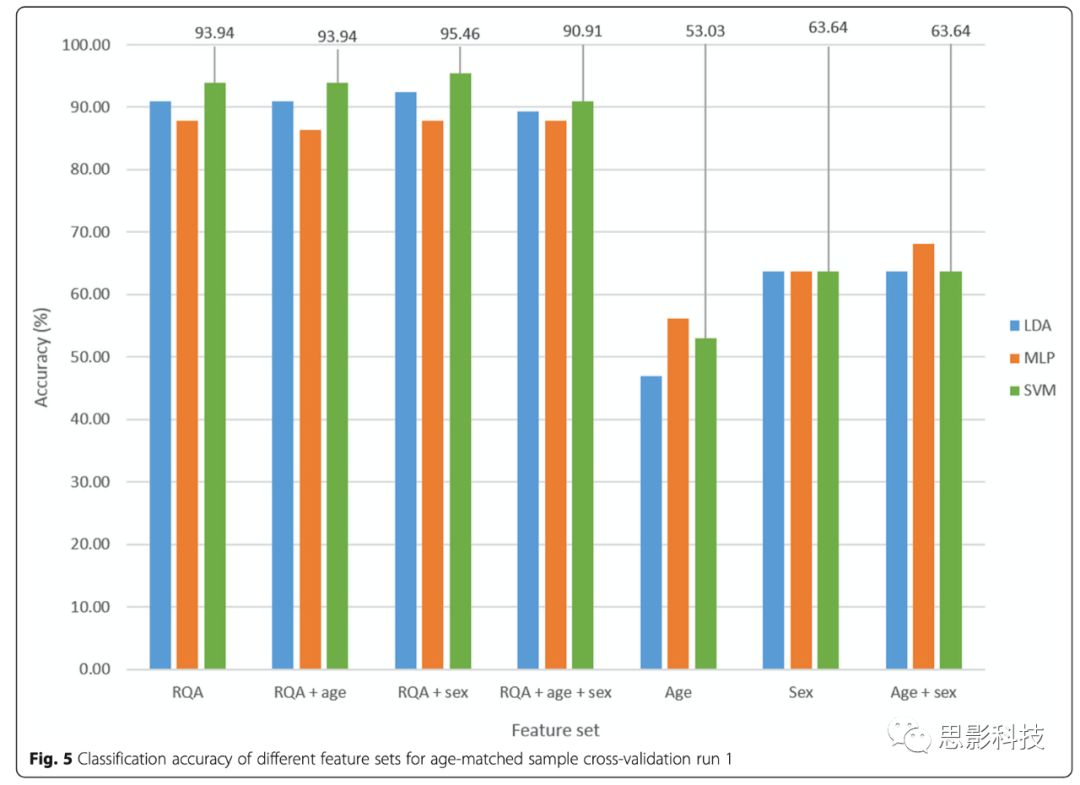
Fig. 5 年龄匹配样本交叉验证run1的不同特征集的分类准确率。
敏感性和特异性测量都很重要——理想的诊断测试是100%敏感性和100%特异性。SVM显示了最好的泛化性能,即可接受的敏感性和特异性。特征集1包含6个RQA特征,特征集2包含6个RQA特征以及性别。加上性别,SVM准确从93.94%增加到95.46%,敏感性从90.91%增加到93.94%,特异性仍为96.97%(Fig. 6)。
编者注:敏感性强可以保证病人一定能被检测出来,但也可能存在正常人被误诊为病人的情况;特异性强可以保证正常人一定不会被误诊,但也可能存在病人没有被检测出来的情况。(请仔细品品)
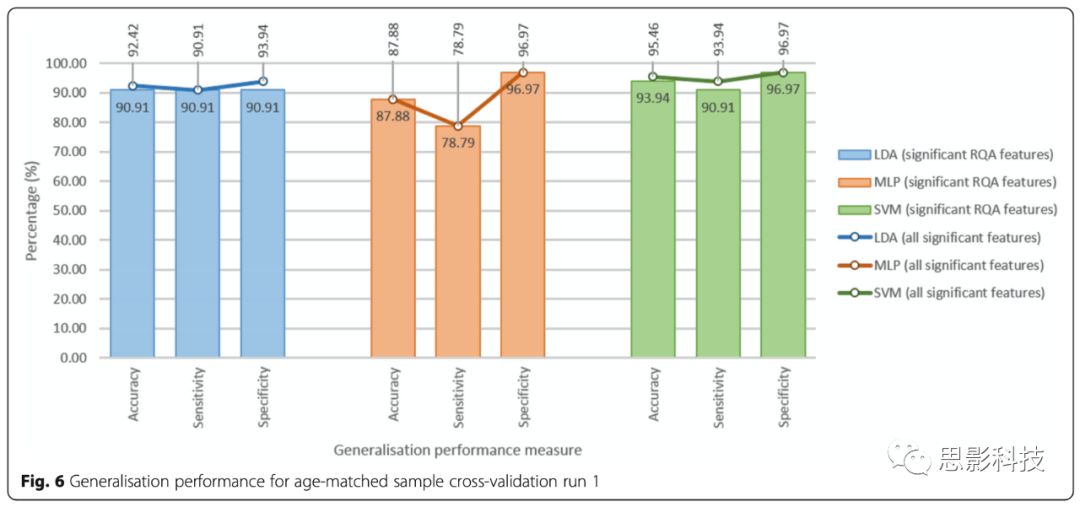
Fig. 6 年龄匹配样本交叉验证run1的泛化性能。
10折的交叉验证结果(Fig. 7)显示特征1(显著的RQA特征)的分类优于特征2(所有显著的特征,RQA和人口学)的分类。特征1的分类准确率分别为:87.27%(LDA)、86.67%(MLP)、85%(SVM)。

Fig. 7 LDA、MLP以及SVM分类器的交叉验证性能。
特征打乱分析结果(Fig. 8)显示对于3个分类器来说,LAM(Laminarity,层流性)是最重要的特征。当对LAM的打乱标签的测试特征集进行分类时,分类准确率的显著下降说明了这一点。这一特征表明层流状态的发生,即状态在下一步中不会改变的概率。从每种情况下的分类准确率下降可以看出,6个显著RQA特征对SVM分类器都很重要。同时对6个显著RQA特征的测试标签进行打乱后,准确率大约为50%,证实所有特征都对分类器提供了重要的区分性信息。

Fig. 8 年龄匹配样本交叉验证run1的特征集1的特征打乱分析。
用SVM对各个特征进行分类显示准确率分别为:78.79%(LAM)、78.79%(DET)、69.70%(ENTR)、65.15%(T2)、62.12%(RR)、59.09%(T1)。最优特征子集的识别表明当包含6个显著的RQA特征时,分类准确率达到最高水平(Fig. 9)。在该图中,‘1 RQA’表示LAM特征,‘2 RQA’表示LAM+ DET,依次类推,‘6 RQA’表示LAM+ DET + ENTR + T2 + RR + T1。

Fig. 9 年龄匹配样本交叉验证run1的最优特征子集识别。
最优RQA特征子集包括6个RQA特征,表示六维特征空间中的一个点(或状态)。通过将数据投射到2D和3D PC子空间,使用PCA实现多维特征空间的可视化。PCA不是在数据的低维表征中对分类进行优化,而是将数据线性转换为一组新的正交轴,其中每个后续成分试图解释数据中的最大剩余方差。Fig. 10和11显示PC子空间中交叉验证run1的数据2D和3D表征,分别约占数据方差的94%和99%。根据训练数据特征确定PC方向;然后将测试数据特征投射到该PC子空间。在特征空间的2D表征中,很难直观地区分ASD和TD组,但在3D表征中,分类变得更加清晰。在两组样本中似乎存在一些重叠。
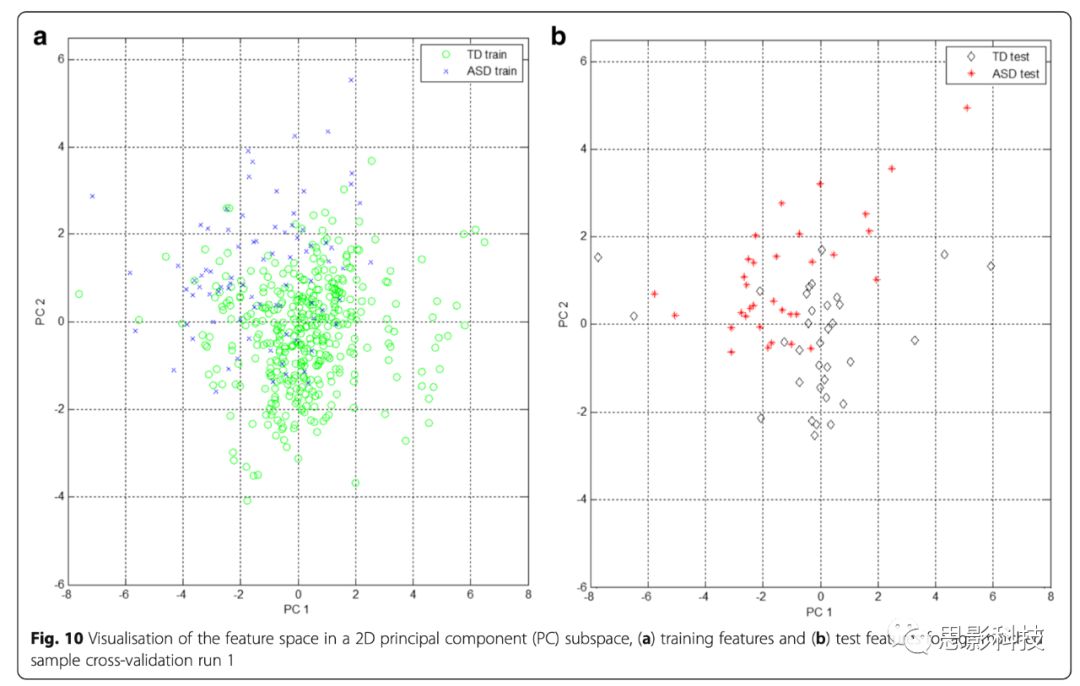
Fig. 10 年龄匹配样本交叉验证run1在2D PC子空间中的特征空间可视化。
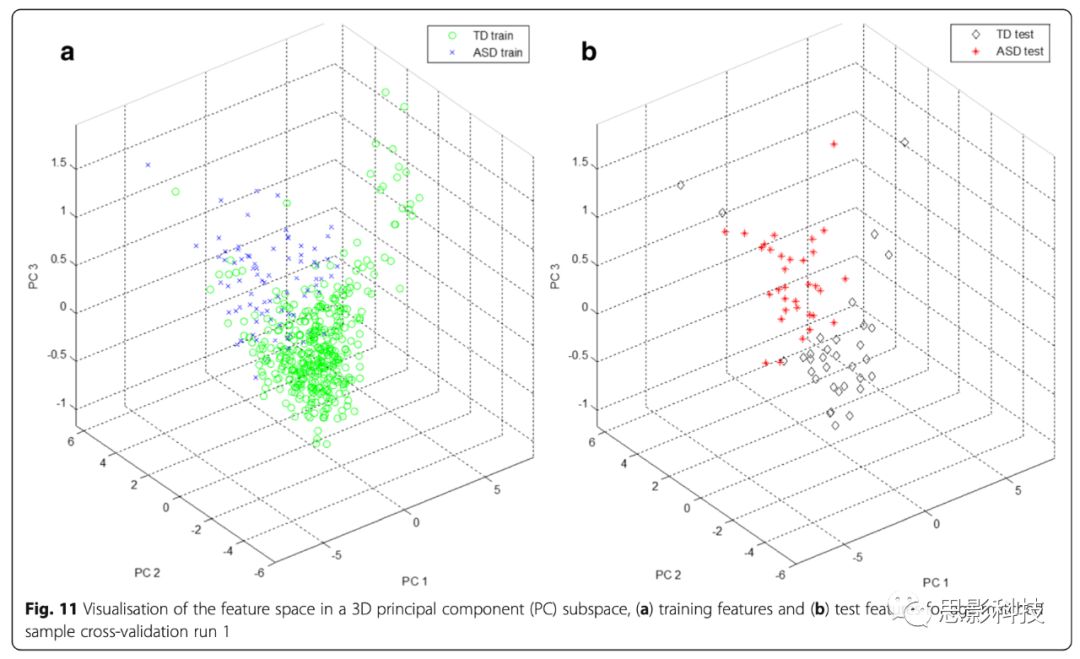
Fig. 11 年龄匹配样本交叉验证run1在3D PC子空间中的特征空间可视化。
研究每个被试的测试-重测信度:
在分类分析中,通常使用“多数投票”识别测试示例的预测标签,并采用50%的阈值进行量化。在每个被试正确分类所有时间段的重复准确率达到50%或50%以上的情况下,该被试被正确识别。SVM分类器识别了4/7个ASD,6/7个TD被试,准确率为100%。LDA和SVM分类器均产生了相似的整体重复性性能,10/14个被试被正确识别(Fig. 12)。
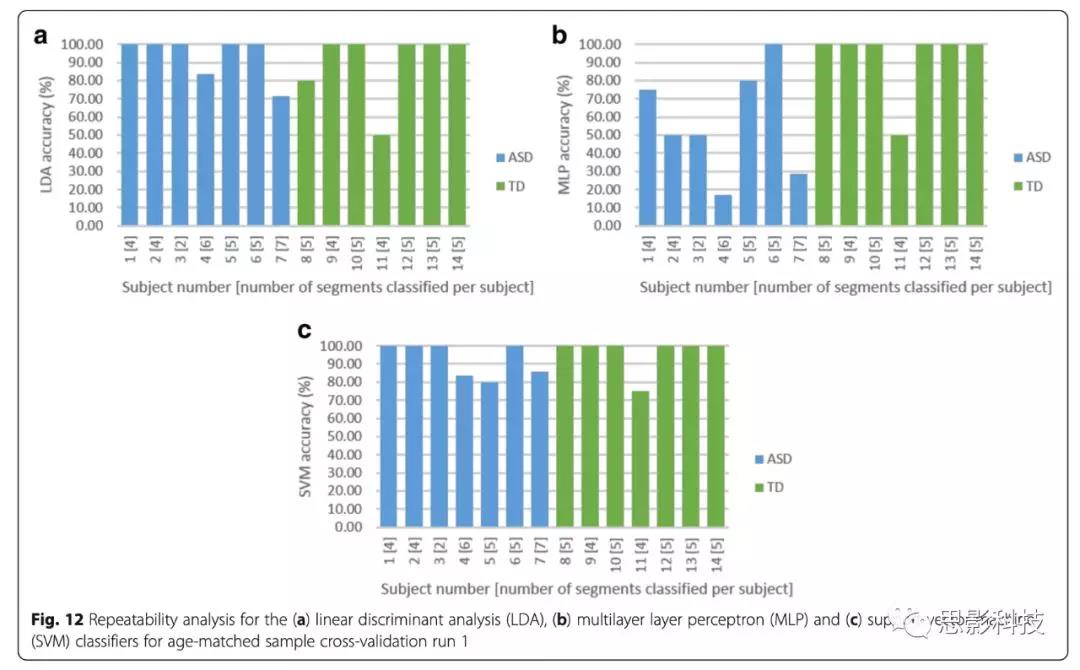
Fig. 12 年龄匹配样本交叉验证run1的LDA、MLP和SVM分类器的可重复性分析。
年龄匹配样本(留一法):
最优参数和特征集的定义与交叉验证run1的参数一致。所有14个leave-one-subject-out runs中,邻域大小为2.9,相当于平均最大相位空间大小的6.7%。对特征集1使用MLP和SVM分类器的分类准确率为92.86%(13/14个被试被正确识别),SVM分类器更加敏感,而MLP分类器更加特异(Fig. 13)。SVM分类器的敏感性为100%(7/7个ASD被正确识别),特异性为85.71%(6/7个TD被正确识别);MLP分类器的敏感性为85.71%(7/7个ASD被正确识别),特异性为100%(7/7个TD被正确识别)。敏感性和特异性是同等重要的,但该研究选择高敏感性的分类器(即SVM),这是由于让“TD”接受第二步确认诊断比排除掉“ASD”更为安全,因此SVM分类器更适合本研究。Fig. 14显示测试-重测信度仍是一个挑战。较大数量的TD时间段可能会使分类器偏向TD组,但结果表明,这种影响可以忽略不计,因为ASD被试的错误分类是很小的。
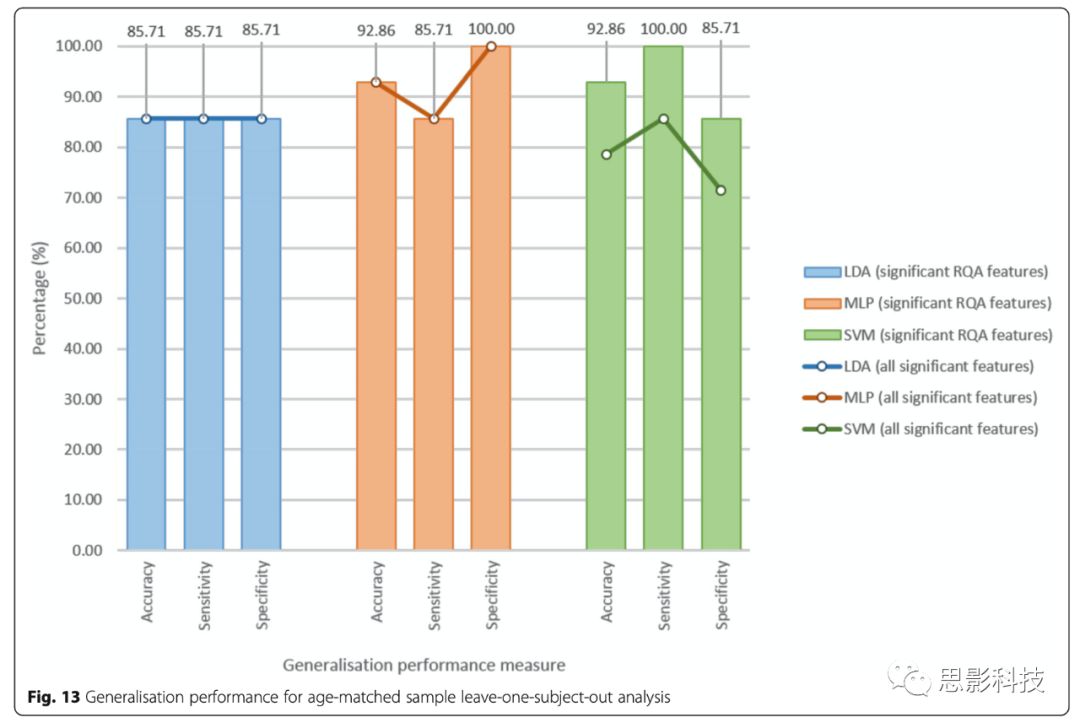
Fig. 13 年龄匹配样本留一法分析的分类性能。
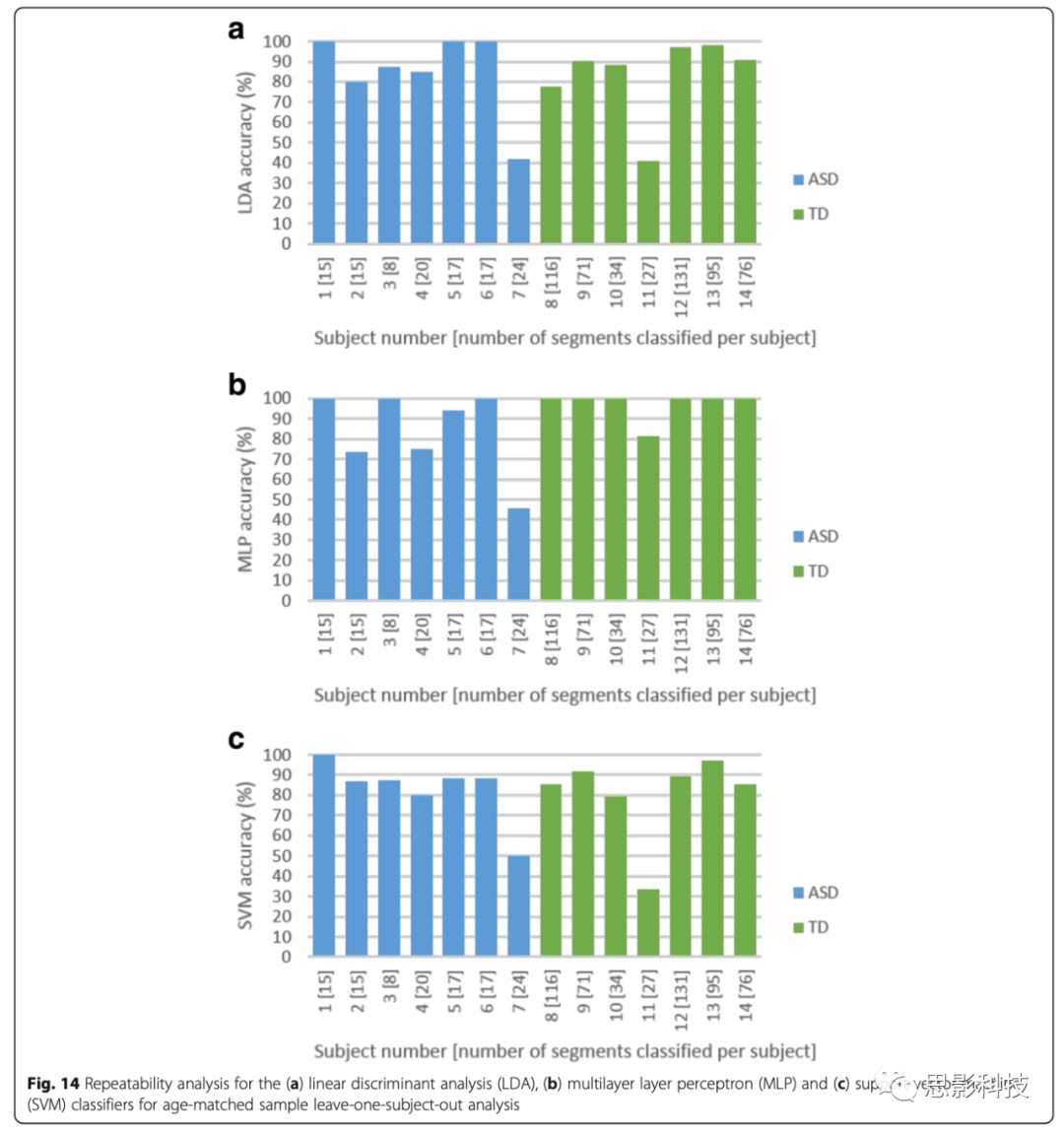
Fig. 14 年龄匹配样本留一法的LDA、MLP、SVM分类器的可重复性分析。
总结:
RQA可能是识别ASD风险儿童的一个准确的、敏感的和特异性的生物标记物。本研究将rsEEG的RQA作为ASD风险的潜在新生物标记物进行评估,因为它能够对rsEEG的短、非线性和非平稳时间段进行多元分析。考虑到潜在混杂因素对发现ASD和相关神经发育障碍生物标记物的影响,本研究控制年龄、性别和智力的三个关键潜在混杂因素。为检验和排除潜在的混淆因素(样本偏差、测试时间段数量不匹配与四舍五入年龄),该分析逐步从完整样本(62个被试;4802个5-s rsEEG时间段)过渡到年龄匹配样本(14个被试;666个5-s rsEEG时间段)。
结果发现:在年龄匹配样本中,RQA在区分ASD和TD方面表现出很好的准确率、敏感性和特异性。在显著的RQA特征集上,SVM分类器使用留一法(模拟诊断一个未知被试的临床场景)表现出稳健的性能:92.86%准确率, 100%敏感性和85.71%特异性。这项研究的结果证明RQA生物标记物可能是用于ASD筛查的一种强有力、可靠的“语言自由、文化公平”技术解决方案;强调在生物标记物研究中考虑年龄、性别和智力作为潜在混杂因素或协变量的重要性。但一致的重复性(即每个被试所有时间段的正确识别)仍是一个挑战。
本研究的新颖之处:
1. 在更大的样本中重复和扩展了原理证明研究,并研究RQA生物标记物在许多协变量或混杂因素中的稳健性。
2. 采用留一法模拟诊断一个未知被试的临床场景。3. 进行测试-重测可靠性分析,确定正确分类每个被试数个时间段的准确率。

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
更新通知:第十届脑影像机器学习班(已确定)
磁共振脑影像结构班(预报名)
弥散磁共振成像数据处理提高班(预报名)
小动物磁共振脑影像数据处理班(预报名)
更新通知:第二十届脑电数据处理中级班(已确定)
脑电信号数据处理提高班(预报名)
眼动数据处理班(预报名)
近红外脑功能数据处理班(预报名)
数据处理业务介绍:
招聘及产品:
招聘:脑影像数据处理工程师(重庆&南京)