

现有的预测模型成功区分了酒精使用障碍(AUD)患者和对照组。然而,识别谁容易发生AUD的预测模型和指示AUD易感性的生物标记物仍不清楚。来自纽约州立大学精神病学系的Sivan Kinreich,Jacquelyn L.Meyers 等人在MolecularPsychiatry杂志上发表了相关研究。
目的:
利用基于发展前数据的AUD预测模型进行纵向研究分析,确定谁易患酒精使用障碍(AUD)、敏感性以及寻找相关生物标记物。
方法:
本研究的样本(N=656)包括欧洲美国人(EA)和非欧裔美国人(AA)血统的后代和非后代。酒精中毒遗传学研究所(COGA)招募了在12岁初未患AUD的656名被试,在随访时间后(约7年)对他们重新评估分为患AUD(n = 328)和未患AUD(n = 328)两组被试。使用机器学习分析了220个EEG特征,149个单核苷酸多态性(snp)特征以及两个家族史特征(FH),并使用线性支持向量机(SVM)分类器对这些特征进行预测,同时对年龄、性别和血统进行了分层分析。
结果:
结果表明,与EA预测模型相比,AA预测模型具有显著的高准确率,并且在EA和AA两个血统样本中,女性的模型准确率都高于男性。EEG+SNP特征的多维度模型在EA和AA样本中都优于仅基于EEG特征或仅基于SNP特征的单一模型。这种多维度模型的优势在AA年龄组(12-15、16-19、20-30)和EA年龄组(16-19)的随访分析中得到证实。在这两种血统的样本中,最年轻的年龄组比另外两个年龄较大的年龄组获得了更高的准确性评分。母性AUD提高了模型在两种血统样本中的准确性。分类预测模型同时识别出了多种有鉴别意义的EEG特征和SNPs(单核苷酸多态性)特征,包括较低的后脑区的gamma波、较高的慢波功能连接(delta、theta、alpha)、较高的额叶gamma波比例、较高的顶叶区beta波相关性,以及5个SNPs:rs4780836、rs2605140、rs11690265、rs692854、rs13380649。
结论:
多维特征模型比单模态模型(EEG或SNPs)产生了更好的预测,而FH(家族史特征)特征的添加进一步提高了预测分数。结果强调了抽样功能连接的重要性,其次是分层分析以及更广泛的选择特征生成了更好的预测分数,更准确的估计了AUD的发展。
引言:
确定谁易患酒精使用障碍(AUD),确定“敏感期”以及寻找相关生物标记物是一项重大挑战。研究表明,青少年时期饮酒比例急剧增加,遗传和环境因素会增加转变为AUD的风险。然而,谁容易发展AUD的明确迹象仍不清楚。最近的研究表明,与一维测量相比,遗传、生物和心理社会信息的多维建模可能更好地反映潜在的病理生理学。在过去的十年中,机器学习(ML)方法和数据挖掘过程已经成功地应用于多维数据集的分析,包括神经成像和遗传数据,以帮助疾病诊断,表现优于经典的回归方法。ML支持向量机(SVM)分类器已成功应用于疾病预测,临床诊断结果,以及分类障碍等。
具体来说,AUD分类器利用电生理特征,如EEG功能连接和频谱功率、EEG非线性特征、AUD家族史(FH)、心理社会特征以及遗传信息,实现了显著的准确性。但是,目前还没有基于发展前数据的AUD预测模型的纵向研究分析。这样的模型可以提供关于生物标志物的重要信息以及发展AUD的敏感性。
本研究使用来自COGA(电生理、SNP、FH)的纵向多维数据,包括欧裔美国人(EA)和非欧裔美国人(AA)血统的后代。COGA收集数据,并跟踪AUD/非AUD个体,之后随访并比较患AUD之前和之后的状态。
研究者的中心假设是:多维特征模型将比单独的每一种模式(EEG测量和基因组数据)产生更好的预测,而FH特征的添加将进一步增加预测分数。在该研究中,研究者提出了一种监督的ML方法(SVM),将所有被试分为随访年限内被诊断为AUD的被试和未被诊断为AUD的被试。该分析将EEG(EEG)测量、遗传学(FH)信息和一组来自最近酒精消费、酒精依赖和酒精相关EEG测量的单核苷酸多态性(SNPs)数据作为特征。识别一个真正的分类器的一个基本方面是控制可能导致模型错误分类的混淆变量的影响,例如年龄、性别和祖先。年龄、性别和血统分层分析可以为每一组建立单独的、更精确的模型,使用分层来控制混杂变量、年龄、性别和血统。该文中作者还研究了预测模型中最具鉴别性的特征来增强对这些特征在AUD发展下的理解。
方法:
被试:
总样本:来自酒精中毒遗传的合作研究(COGA)招募的656名被试(376名男性和280名女性),年龄在12-30岁之间。
本研究收集了6个站点的数据。研究者只检查了第一次就诊时未受影响的被试,并在几年后对他们重新进行评估(两次评估时间相差约7年)。同时将他们分为两组: AUD组和对照组。如图1所示。
AUD组:首次就诊时未被诊断为AUD但在随访时间内(平均随访年数=7.36±3.01 )被诊断为终身AUD的被试。 n= 328,(188名男性,140名女性),平均年龄:17.88±2.95岁。
对照组:首次就诊和随访时间内(平均随访年数= 6.64±3.35)都没有被诊断为AUD的被试。n = 328,(188男性,140名女性)。对照组年龄与AUD组相匹配(p=0.5),平均年龄17.69±3.11。
在后续分析中,根据血统(EA, AA)、年龄(青春期早期:12 - 15岁,青春期晚期:16 - 19岁,成人:20 - 30岁)、性别(男、女) 对被试进一步划分组别。所有的组都是按年龄匹配的。血统、性别、年龄等特征决定了一系列的分析包括不同的被试子集。每一组的详细说明见补充表1和表2。
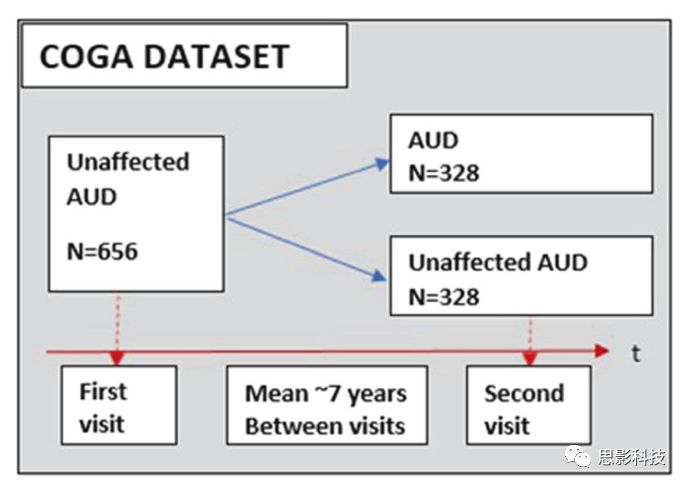
图1:数据流程图
补充表1:被试分组数据
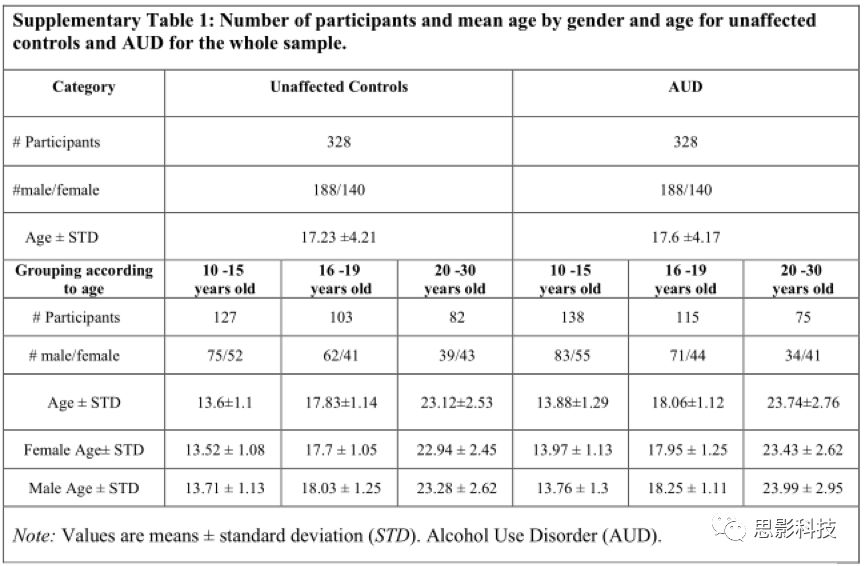
补充表2:各种特征模型下的分组数据
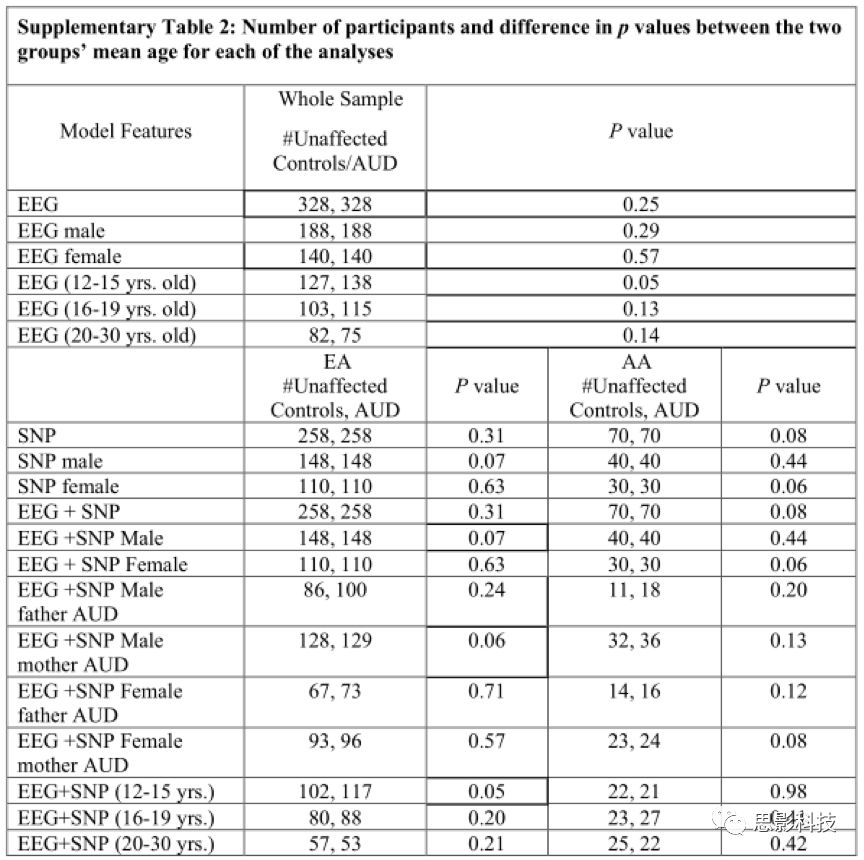
过程:
脑电数据采集与预处理
EEG采集:所有被试在屏蔽室里采用基于扩展10-20系统的64通道电极帽记录了4分钟的静息EEG。参考电极位于鼻尖,接地电极位于前额。眼电图由眼眶上垂直电极和左眼外的水平电极记录。采样频率:500Hz或512Hz。频带范围:0Hz~100Hz。
预处理:使用MATLAB+EEGLAB进行低通滤波,范围:0~60Hz,并在60Hz时采用数字凹陷滤波去除交流电引起的伪影。
特征提取
EEG(EEG)特征提取:连续EEG的时频分析的时间分辨率为0.002s和频率0.3Hz计算得来。将每个电极的绝对频率分为5个频带delta(1-4Hz),theta(4–8 Hz), alpha(8–12 Hz), beta(12–30 Hz)和gamma(30–60Hz),将电极划分为5个感兴趣区域:额叶(F3, F4, F7,F8), 顶叶(P3, P4, CP1,CP2), 颞叶 (T7, T8),下顶叶(P7, P8, CP5,CP6)和枕叶(O1, O2)。
提取了以下电生理特征:
1:功率谱(40个特征):对每个ROI内的电极分为两个半球进行平均,计算额叶双侧半球每个电极的右/左功率比。
2:相干值(90个特征):计算每个频带信号的相干性。
3:相关值(90个特征):计算每个频段信号的皮尔逊相关系数。
家族史(FH)特征提取:父母的AUD数据(母亲或父亲AUD数据)(2个特征)。
遗传数据(SNPs)特征提取:SNPs(149个特征)是根据最近几项涉及EA和AA人群的全基因组关联研究(GWAS)中EEG和酒精相关特征的相关性选择的。包括快速EEG,饮酒量,DSM-IV酒精依赖情况和24小时内最大饮酒量。
基因分型:基因分型率<98%或违反Hardy-Weinberg平衡(P<10−6)的snp被排除在分析之外。去除Mendelian不功能连接,然后使用SHAPEIT和IMPUTE2将数据代入1000个基因组。计算之后,概率≥0.90才被分为一类基因型。在特征提取过程中,排除了所有小等位基因频率(MAF) <0.03的snp,以及输入信息得分<0.30的snp。
特征选择和分类模型估计
每组(EEG,SNP,EEG+SNP,男性,女性,AA,EA,不同年龄组)分别进行特征选择、模型估计和验证。为了控制变量过拟合,采用正则化方法,提高统计模型的预测精度和可解释性。对于特征选择,研究者使用LASSO。LASSO的稀疏度(即生成正好为0的系数估计值)使得他在减少估计方差的同时提供了一个更具解释性的最终模型,因此对于特征选择具有优势。其在基因组数据中的应用表明,选择少量具有代表性的特征可以实现满意的分类。首先使用十折交叉验证(CV)确定正则化参数,使用 AUD和对照组两个标签作为响应变量。所有非零系数的特征都保留在后续分析中。将大多数鉴别特征的简化集输入分类器将被试进行分类,即要么是AUD组,要么是对照组。
训练一个线性核支持向量机在十折交叉验证过程中来区分AUD组和对照组,包括参数优化。对于十折交叉验证,被试被随机分为10个相等的组,然后在10组中的9组上训练一个分类器,并在剩下的一个组上进行测试。每一次折叠,整个数据集被打乱,以保证随机性。由于随机划分对分类结果的影响,重复这个过程十次,对输出结果进行平均。
为了评估模型性能,记录了真阳性数(TP,正确分类的AUD数)和真阴性数(TN,正确分类的对照组数)得分。分类精度计算为TP和TN之和除以所有分类对象之和的比值,使用曲线下面积AUC和F-scores对分类模型进行评价。F定义:
F=(1+β2)×(精确率×召回率)/(β×精确率+召回率)
解释为加权精度和数量值的调和平均值。精确率:真阳性的数量除以真阳性的数量加上假阳性的数量,召回率:真阳性的数量除以真阳性的数量加上假阴性的数量。β设置为1。
统计分析:
采用双尾t检验比较两种分类模型准确性(比较100个精度值,10x10 交叉验证)。为了确定一组稳定的优势特征及其重要性排序(权重排序),研究者对10个模型重复进行了平均分类权重。所有样本均进行了基于EEG的分类,而任何涉及遗传信息的分析均分别对EA和AA样本进行。根据性别和年龄组分别计算模型。
结果:
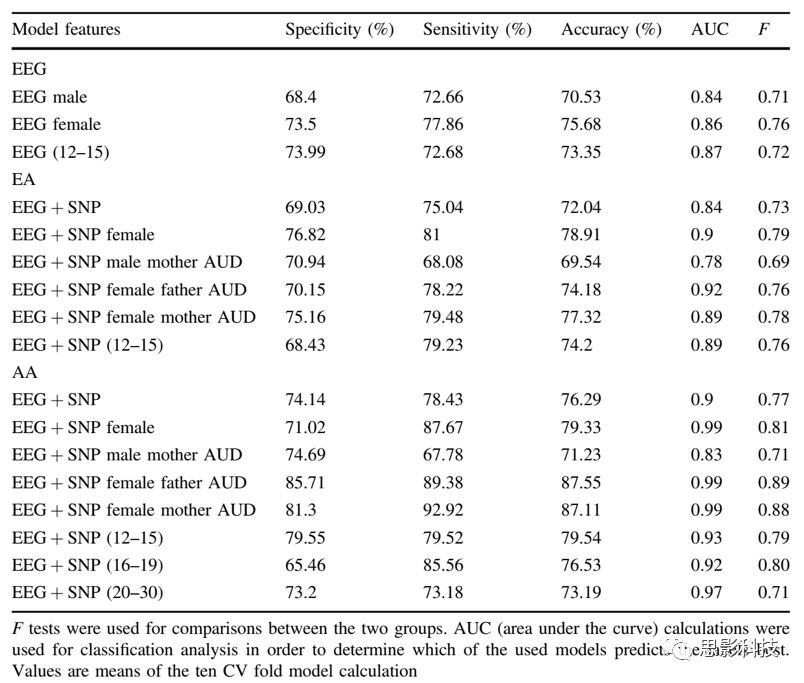
预测模型采用具有重叠特征的不同SVM预测模型和根据血统、年龄和性别划分的不同受试者子集。如表一所示:总结了显著的预测模型在血统、性别和年龄方面的得分结果:包括模型特征、敏感性、特异性、准确性、AUC值和F分数。表1:不同模型下根据血统、年龄、性别对AUD和对照组分类的结果
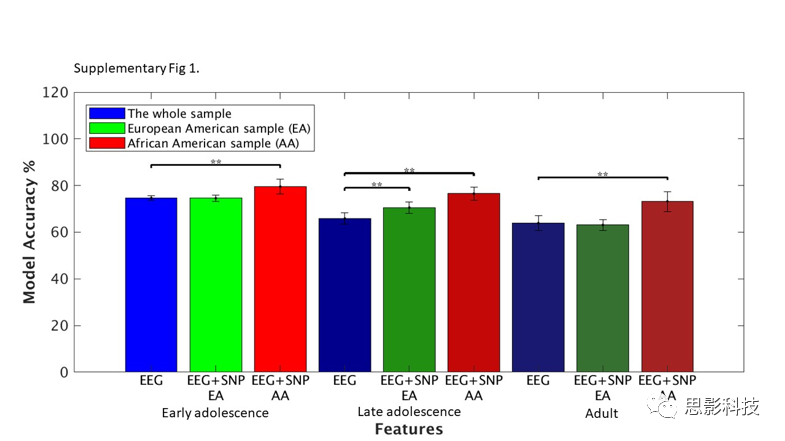
补充图1:根据年龄和血统确定模型的准确性。通过单独的EEG特征和EEG+SNP联合特征对各年龄进行分类:青少年早期(12-15岁),青少年晚期(16-19岁)和成人(20-30岁)。结果表明:在AA样本和EA样本的2个年龄组中,联合模型都优于单模式EEG特征模型。
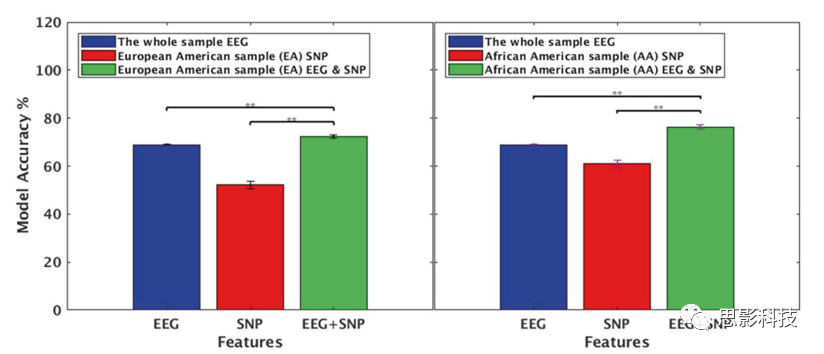
图2.根据血统确定模型准确性。对于EA和AA样本,显示了根据EEG特征、SNP特征和EEG+SNP特征下的分类结果。结果表明:复合模型比单一特征模型具有更高的精度。
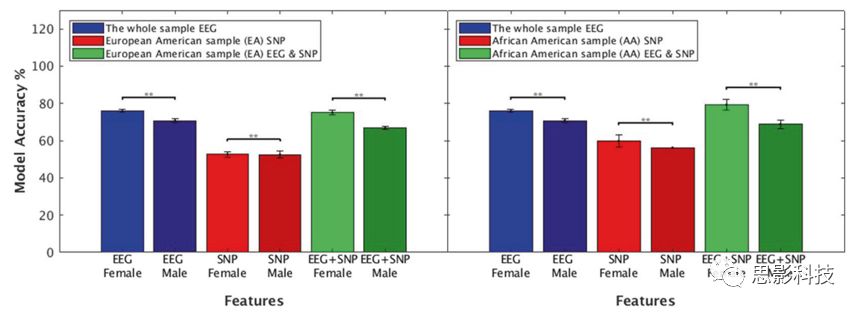
图3.根据血统和性别确定模型准确性。显示了对于不同性别的EEG特征、SNP特征和EEG+SNP特征下的分类结果。结果表明:在三个特征模型的EA和AA样本中,女性的准确性得分均高于男性。
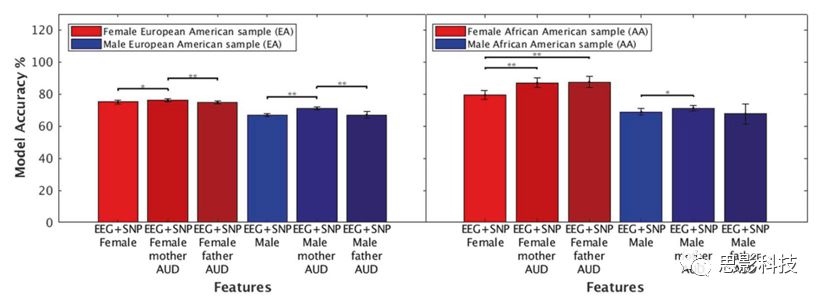
图4:根据血统、性别和家族史确定模型准确性。在性别的基础上再加上FH特征。结果表明:对AA和EA,男性和女性样本中,母亲的AUD特征提高了模型的准确性。父亲的AUD特征提高了AA女性样本组合模型的准确性。
表1总结了重要的预测模型在血统、性别、年龄特征下的结果分数,结果表明了AA样本的结果分数比EA样本更高(P<0.001),在AA和EA样本中,女性得分均高于男性,较年轻的年龄组得分高于其他两个年龄组。
从表1和图2可以看出,对于AA和EA样本,EEG和SNP联合模型都比EEG或者SNP单一模型精确度更高(EA; p (EEG vsEEG+SNP)<0.001, p(SNP vs EEG+SNP <0.001)(AA; p (EEG vs EEG+SNP)<0.001, p(SNP vs EEG+SNP) <0.001)。结果在EA和AA和随访分析中得到证实(AA: p (青春期早期EEG vs EEG+SNP) <0.001,p (青春期晚期 EEG vs EEG+SNP) <0.001, p (成年人 EEG vs EEG+SNP) <0.001)。EA年龄组的组合模型在青春期的早期和晚期达到显著水平,但没有超过基于EEG的模型准确性(表1,补充图1)。
性别分层分析显示,AA女性组比三种特征分类中男性(EEG、SNPs、EEG+SNP联合模型)的模型精确度更高(总样本:(男性EEG vs女性EEG)<0.001,AA:p (SNP男性 vs SNP女性)= 0.008,p(EEG + SNP男性 vs EEG+ SNP女性)< 0.001),EA: p (EEG + SNP男性 vs EEG+ SNP女性)< 0.001)(图3所示)。
总而言之,所有EEG+SNP(单核苷酸多态性)特征组合模型下,AA和EA女性组的精确度分别达到了79.33%(特异性=71.02%,敏感性=87.67%,AUC =0.99, F = 0.81) 和 78.91%(特异性=76.82%,敏感性=81%,AUC =0.9, F = 0.79),在AA和EA早期青春期年龄范围内精确度分别达到了79.54%(特异性为79.55%,敏感性= 79.52%,AUC =0.93, F = 0.79)和74.2%(特异性=68.43%,敏感性= 79.23%,AUC =0.89, F = 0.76)。
将母亲AUD和父亲AUD的FH特征与EEG+SNP联合模型相比较,发现了显著差异。在AA和EA的男性和女性样本中,母亲AUD特征增加了模型精度,父亲AUD特征仅增加了AA女性样本联合模型的准确性,在AA女性样本中,添加了父亲AUD特征或者母亲AUD特征的EEG+SNP联合模型分别达到了87.55%(父亲 AUD:特异性=85.71%, 敏感性=89.38%,AUC=0.99, F=0.89) 和87.11% (母亲AUD:特异性=81.3%, 敏感性=92.92%,AUC=0.99, F=0.88))的高精确度(见表1和图4)。
补充表7:EEG特征
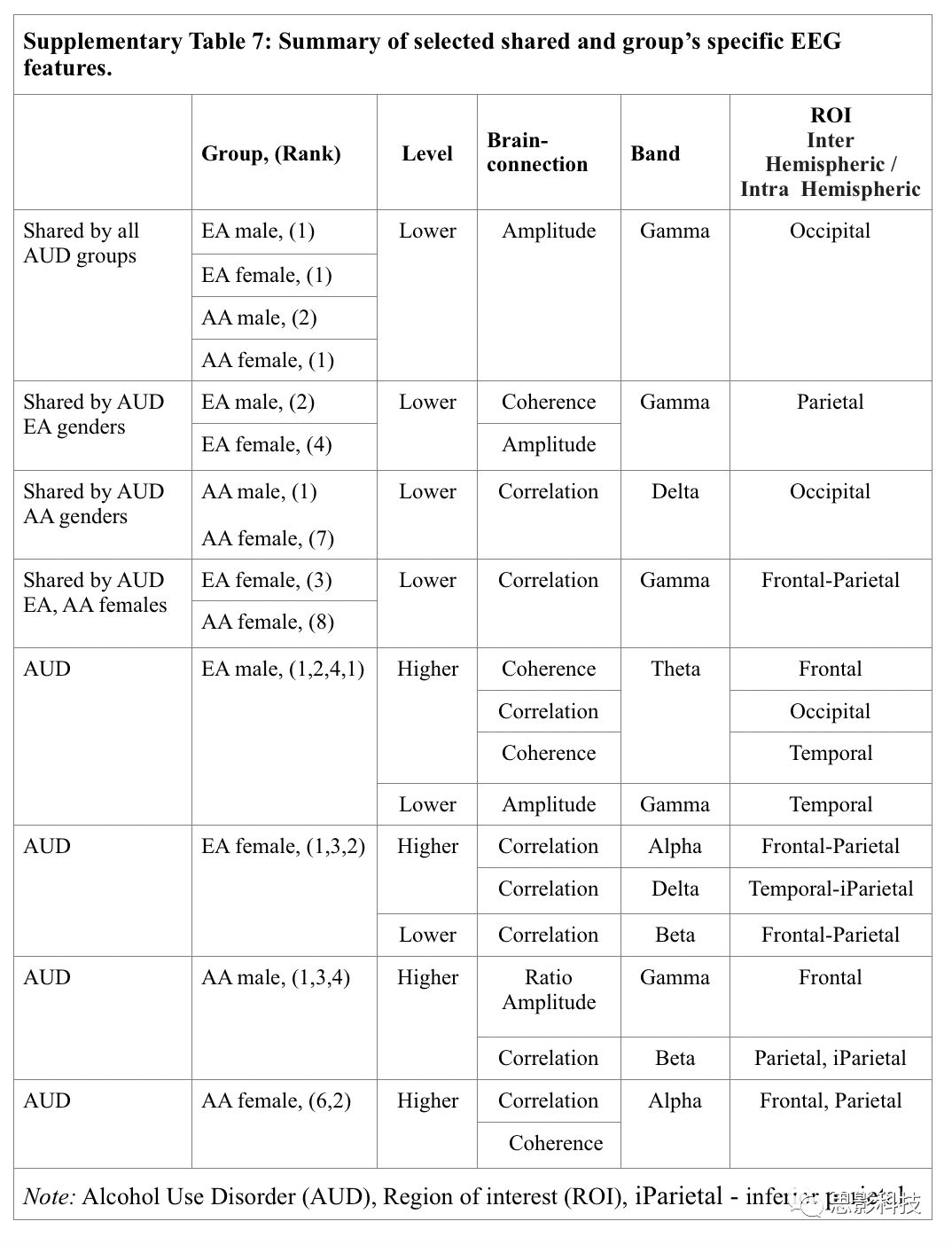
EEG特征:
补充表7总结了EEG+SNP多维模型中按血统和性别分层的特定的共有的组特异性特征,所有AUD组最一致的EEG预测以EEG+SNP模型为基础,从而与控制组的被试区分开,包括降低后脑区的gamma(如振幅、功能连接、相关)和在多个感兴趣区域的慢波高功能连接(delta, theta,alpha)。
与对照组相比,所有AUD组的枕部gamma振幅均较低(权重排名1-4)。EA-AUD性别组具有较低的顶叶gamma半球间功能连接(男性)和振幅(女性)(权重排名2,4),AA- AUD性别组具有较低的枕叶delta半球间相关性(权重排名1、7),EA和AA女性样本均具有较低的额顶叶gamma相关性(权重排名2,8)。另一方面,EA-AUD组男性的枕叶、额叶和颞叶的半球间功能连接显示出theta更高(权重排名1、4、5),而两组女性都在额顶叶(EA和AA组,权重排名排名2, 8)和颞顶叶(EA组,权重等级4)都显示较高的慢波半球内连接(delta,alpha)。两组的不同之处在于:顶叶区域(AA男性)具有较高的额叶右/左比率和较高的相关系数(权重排名第2),而顶叶区域(EA女性)具有较低的脑半球内相关系数(权重排名第5)。
补充表12:SNP特征
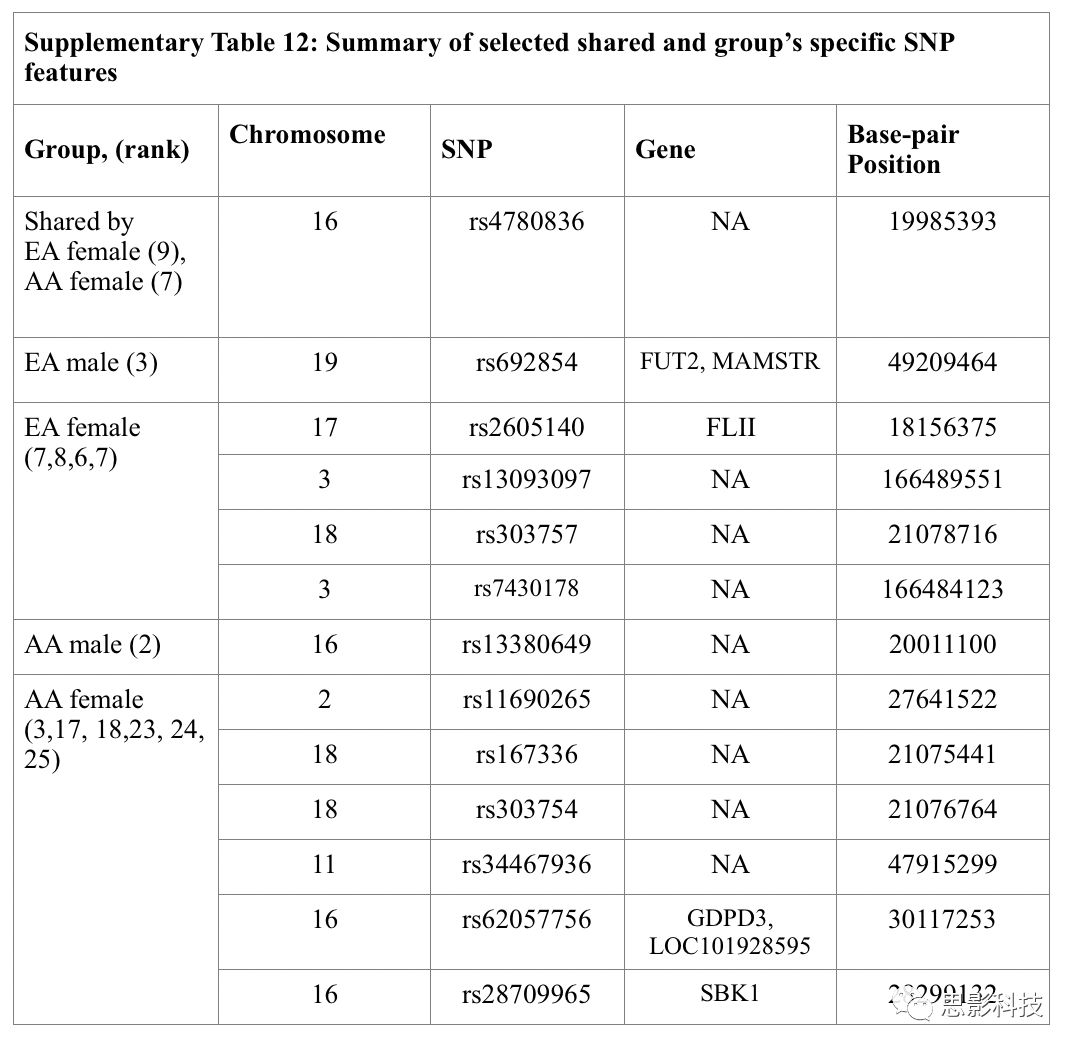
SNPs(单核苷酸多态性)特征:
补充表12总结了最稳定的的SNP预测器来预测AUD的易感性。
在16号染色体上(rs4780836,权重排名9,7)发现 EA和AA-AUD女性共享一个SNP,在17号染色体的基因FLII(RS2605140,体重排名7)和18号染色体(rs303757,权重排名18)、3号染色体上的2个位点(rs7430178,权重排名3)上发现了性别遗传特异性位点。
AA女性样本中,发现了2号染色体上有1个位点(rs11690265,权重排名2),18号染色体上有2个位点(rs167336和rs303754,权重排名18),11号染色体上有2个位点(rs34467936,权重排名11),16号染色体上有2个位点(rs62057756和rs28709965,权重排名18)。
在EA-AUD男性样本的19号染色体FUT2基因上 (rs692854,权重排名19)和AA-AUD男性样本的16号染色体上(rs13380649,权重排名16)分别发现一个位点。 总体而言,女性比男性具有更多的SNP特征(#SNP (AA女性)= 8,#SNP (AA男性)=1,#SNP
(EA女性)=5,#SNP (EA男性)=1)。
讨论:
机器学习的应用为建立基于纵向数据的创新疾病预测模型带来了希望。本研究使用了COGA丰富的EEG、遗传和FH数据集,这些数据来自在发生AUD之前的12岁之前的个体,并随后进行随访,数年后,他们要么被诊断为AUD,要么未受影响。这是第一个研究制定的预测模型,为那些谁是易于发展AUD使用ML多维特征,同时考虑性别和祖先。研究者发现了更高的准确性,AA模型的预测率高于EA模型。AA和EA样本中结合EEG和SNP特征的多模态模型比只基于EEG或单核苷酸多态性特征的单模态模型得到更高的准确性分数,这些研究结果在AA样本的不同年龄组(青春期早期,青春期后期,和成人)和EA样本青春期晚期组的后续分析(相同的数据集)中得到证实。性别分析显示出更高的模型精度趋势,三个特征类别(EEG、SNPs和EEG+SNP联合模型)模型中EA和AA样本女性组均高于男性组。研究者进一步发现,在性别不同的模型中添加父母的AUD特征,EA和AA样本均显示母性AUD病史作为鉴别特征,增加了基于EEG + SNP联合模型的准确性。父亲AUD病史仅在AA女性患者中比基于EEG+SNP的联合模型提高了模型的准确性。在这两个样本中,较年轻的组比较年长的组获得了更高的准确性评分。每个模型的EEG和SNP特征都有区别,揭示了性别和血统特异性成为AUD易感性标记物。
准确的预测模型依赖于给定群体的特征集的最优子集。当前研究中给定的特征集更好地预测了AUD女性比男性多,AA-AUD比EA-AUD多,这意味着需要继续寻找与每个群体相关的具有重要性或“强度”的特定群体变量。例如,两个男性群体的低预测分数可能与模型有限的遗传鉴别力有关(即在所有的男性模型中只涉及一个SNP,而在女性模型中涉及4-5个SNP)。
该研究发现,在性别和血统中,对AUD(酒精使用障碍)易感的个体(如枕部、顶叶)的gamma活性较低。这些发现与最近对许多精神疾病(如抑郁症、双相情感障碍、焦虑症和AUD)的神经生理学关联的综述相一致,在各种精神障碍类型中,最主要的变化模式是功率随频率的升高而降低。
一方面,研究者在EA中发现了较低的顶叶gamma(振幅和功能连接),在EA和AA中发现了较低的额顶叶gamma功能连接,这说明较低的后部gamma不仅是一种疾病的生物标记,还是一种疾病增加AUD易感性的因素。gamma活动已被提出,以促进前馈或“自下而上”的信息流动从较低的大脑区域到较高的皮层迭代重复活动。gamma频带功率和功能连接的降低可能是后皮层自下而上交流的中断,导致感觉和执行功能障碍,这可能反映皮质整合改变。
另一方面,研究者发现EA样本中男性和女性之间较慢波段(delta、theta、alpha)的功能连接都有所增强。这些结果表明,高连接度的酒精易感个体减少了外界的注意力,而不是内省的注意力。
未来研究方向:
1:SNP被认为是预测AUD易感性的显著特征。
2:该研究结果证明了血统、性别和年龄在预测AUD发展的模型中的重要性。
总结:
总的来说,研究者发现广泛的多维特征产生了更高的模型精度,确定组相关的特定特征将产生更好的预测模型。基于遗传数据和EEG数据相结合的ML模型比单独使用任何一种方法都能获得更好的分类精度。这些结果表明,这两种模式可能反映了AUD(酒精使用障碍)病因学的不同方面,在描述疾病方面不能相互替代,使用多个维度对疾病进行分类的ML模型具有一定的优势。这些结果为更个性化的疾病预测方法打开了大门。基于不同模式的模型可以包括随时间变化的特征(大脑的结构和功能)以及人的生长发育(行为和心理)使得关注特定的群体(如按年龄、性别、血统、FH、文化和行为进行分类)从而创建具有真正价值的个性化预测模型来推进患者个性化护理。
原文:
Predicting risk for Alcohol Use Disorder using longitudinal data with multimodal biomarkers and family history: a machine learning study
S Kinreich, JL Meyers, A Maron-Katz…-Molecular…, 2019 - nature.com

微信扫码或者长按选择识别关注思影
第十四届磁共振脑网络数据处理班(重庆,7.26-31)
第三十届磁共振脑影像基础班(南京,7.31-8.5)
第十届脑影像机器学习班(南京,6.30-7.5)
第十二届磁共振弥散张量成像数据处理班(南京,6.18-23)
第二十届脑电数据处理中级班(重庆,8.9-14)
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
小动物磁共振脑影像数据处理班(预报名,南京)
第二十一届脑电数据处理中级班(南京,9.7-12)
第七届眼动数据处理班(南京,7.26-30)
脑电信号数据处理提高班(预报名)
脑磁图(MEG)数据处理学习班(预报名)
思影科技功能磁共振(fMRI)数据处理业务
思影科技弥散加权成像(DWI/dMRI)数据处理
思影科技脑结构磁共振成像数据处理业务(T1)
思影数据处理业务三:ASL数据处理
思影科技脑电机器学习数据处理业务
思影数据处理服务五:近红外脑功能数据处理
思影数据处理服务六:脑磁图(MEG)数据处理
招聘:脑影像数据处理工程师(重庆&南京)
BIOSEMI脑电系统介绍
目镜式功能磁共振刺激系统介绍