

抗抑郁药已被广泛使用,但其疗效仅为适中,部分原因是重度抑郁症的临床诊断包含生物异质性条件。华南理工大学和斯坦福大学研究人员在Nature Biotechnology杂志发表文章,试图识别抗抑郁药治疗反应的神经生物学特征(与安慰剂相比)。本研究开发了一个适用于静息态EEG(rsEEG)的潜在空间机器学习算法(latent-space machine-learning algorithm),并将其应用到安慰剂-对照抗抑郁药研究的数据中(n=309)。抗抑郁药舍曲林rsEEG模型(与安慰剂相比)可以稳健预测症状改善,并且应用于不同的研究地点和EEG设备上。这种舍曲林-预测的EEG特征可推广到另外两个抑郁样本,它反映了普遍的抗抑郁药物反应,并与rTMS治疗结果有相关。此外,通过同步TMS和EEG测量,研究者发现舍曲林rsEEG特征表征前额叶的神经反应。该研究通过EEG计算模型促进了对抗抑郁药治疗的神经生物学理解,并为抑郁症的个性化治疗提供了临床手段。
文献导读
目前,重度抑郁症是根据临床标准定义,包括神经生物学表型的异质性组合。这种异质性解释抗抑郁药的中等优势(Cohen’s d = 0.3)。以往的研究发现,rsEEG(theta: 4-7Hz; alpha: 8-12Hz)能识别抑郁症治疗-预测的异质性。然而,由于缺乏交叉验证以及大样本,以往有的研究仅能识别出与安慰剂无区别的非特异性预测因子(如喙前扣带回theta电流密度),并且未能产生稳健的和可重复的神经信号。因此,目前仍缺乏一个稳健的抗抑郁反应表型的神经生物学特征,用以识别哪些患者将从药物中获得很大的好处。描述这些特征将促进神经生物学对治疗反应的理解,并产生重要的临床意义。为识别稳健的抗抑郁反应的抑郁表型,可以使用机器学习结合rsEEG数据中的复杂多变量关系。
然而,一个有效的计算模型面临三个关键挑战:
1.容积传导造成信号和噪音的无法区分;
2. 由于EEG数据具有较高的时空维度和噪音,模型存在过度拟合的风险;
3. 由于误差函数关于模型参数的非线性,在同时优化特征识别和预测回归模型拟合方面存在挑战。
为应对这些挑战,该研究开发了一种机器学习的算法: Sparse EEG Latent SpacE Regression (SELSER,稀疏脑电图潜在空间回归)。研究数据来源于4个研究:
1. 使用安慰剂-对照的随机临床研究的抑郁症数据:建立抗抑郁药物的调节因子和生物标记临床护理响应 EMBARC(Establishing Moderators and Biosignatures of Antidepressant Response in Clinic Care ; n = 309),通过训练SELSER建立rsEEG预测特征。
2. 使用另外3个研究数据集验证该模型。该研究旨在揭示抑郁症的治疗反应表型、分离药物和安慰剂反应、建立其机制意义,并为基于rsEEG特征的治疗选择提供初步证据。
方法
研究数据集:
1. EMBARC研究(训练SELSER建立rsEEG预测特征):4个站点的309名重度抑郁患者随机接受8周的舍曲林治疗或安慰剂治疗(补充图1; 补充表1)。收集4个2-min blocks(2个闭眼,2个睁眼)的基线rsEEG(Table S2),并在治疗前后收集HAMD(汉密尔顿抑郁等级量表)分数作为临床结果评估。
rsEEG预处理采用全自动的伪迹剔除流程:将数据降采样至250Hz;使用CleanLine消除60Hz AC线性噪音;用0.01Hz高通滤波器去除非生理慢波漂移;采用全脑平均进行重参考;采用波幅阈值方法删除坏段;删除坏通道,并通过球形插值对坏通道进行插值;使用ICA方法去除伪迹,使用从另一数据集训练的ICs模式分类器删除与肌电、眼电和ECG伪迹相关的ICs;对数据进行平均参考,并提取4个站点共有的54个EEG通道。最终228名被试的数据可用。

补充图1 参与治疗预测分析的患者的EMBARC CONSORT流程图
补充表1 EMBARC研究的基线社会人口学信息统计和临床变量

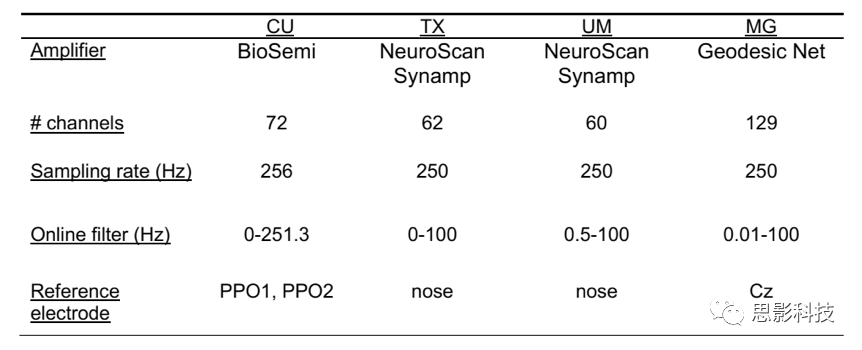
2.第二个抑郁研究数据集(验证rsEEG抗抑郁药物-预测特征):使用两个不同的EEG放大器采集72名患者的4个2-min blocks(2个闭眼,2个睁眼)基线rsEEG。同时,患者也完成Antidepressant Treatment Response Questionnaire (ATRQ,抗抑郁治疗反应问卷)。rsEEG预处理和分析与EMBARC相同。
3. 第三个抑郁研究数据集(评估治疗-预测的rsEEG特征的收敛效度和神经生物学意义;rsEEG抗抑郁药物-预测特征与fMRI特征、以及对探测刺激的TMS和EEG反应的相关):获得24名患者的rsEEG、spTMS以及EEG和任务态fMRI数据。
采集睁眼和闭眼rsEEG各3min,并用MATLAB脚本立即评估数据质量。rsEEG预处理与EMBARC相同。任务态fMRI要求患者执行情绪冲突任务(Emotional conflict task)(补充表3),并使用FSL对该数据进行处理。MRI数据采集之后,接受单脉冲TMS(脑区:V1, M1, pDLPFC, aDLPFC)。使用TMS兼容的64导BrainAmp DC放大器收集spTMS和EEG数据。
spTMS和EEG预处理(ARTIST):删除TMS后的10ms数据;数据降采样至1kHz;使用ICA识别并剔除伪迹;用陷波去除60Hz噪音;进行0.01-100Hz带通滤波;使用全脑平均对数据进行重参考,并进行分段(-500至1500ms);删除伪迹段和坏的通道;剩余伪迹采用ICA方法。使用模式分类器删除与肌肉伪迹、眼电伪迹、ECG伪迹相关的ICs。补充表3 MDD研究的结构MRI和fMRI获取扫描参数

4. 第四个抑郁研究数据集(rTMS治疗结果的预测,检验结果的推广性以及治疗选择的潜力):所有患者接受左侧DLPFC高频(10Hz)刺激(73名患者)或右侧DLPFC低频(1Hz)刺激(104名患者),同时接受心理治疗。采用BDI(Beck Depression Inventory贝克抑郁量表,主要结果)和DASS( Depression, Anxiety and Stress Scale,包括抑郁、焦虑和压力的自我评估量表)作为临床评估。采集:收集睁眼和闭眼rsEEG各3min。rsEEG预处理和临床结果指标与EMBARC相同。
机器学习:
1. 稀疏EEG潜在空间回归(Sparse EEG latent-space regression):为使用基线rsEEG数据预测治疗结果,本研究开发了end-to-end机器学习算法(SELSER)。该算法优化潜在空间模型,通过最小化预测误差,将rsEEG映射到治疗结果上,并受到潜在信号维数的约束。采用4个典型的频带功率作为特征(theta, 4–7 Hz; alpha, 8–12 Hz; beta, 13–30 Hz; gamma, 31–50 Hz)。SELSER优化了一系列空间滤波器降低容积传导对信号的影响,将感觉空间中的多通道EEG信号转换为低维潜在信号。然后建立线性回归模型,将潜在信号的频带功率与治疗结果相联系。
SELSER对第i个患者的治疗结果(yi)进行如下建模(i=1, ……, M):
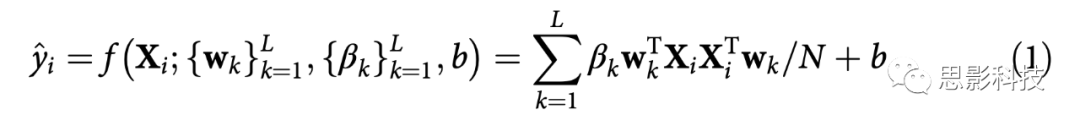
Xi∈RC×N是第i个被试的滤波EEG数据,C是通道的数量,N是采样点的数量。^yi指第i个被试的预测治疗结果。
Wk∈RC是k阶空间滤波(K=1, ……, L),βk是线性回归模型的K阶权重系数,b是线性回归模型的截距。预测分三个阶段进行(补充图10a):(1)使用空间滤波器
{Wk}Lk=1:sK=XTwk将多通道EEG信号转换为L潜在信号{sk}LK=l;(2)计算L潜在信号的频带功率{Wk}Lk=1;(3)结合潜在信号的频带功率,用线性回归模型
{βk,b}Lk=1预测治疗结果Ŷi=Σβkzk+b。
预期每个潜在信号都可以捕获治疗结果的某部分信息预测,用EEG频带功率来量化。研究者提出一种高效的算法,通过最小化平均-平方预测误差来优化所有模型参数,同时防止L过大而导致的过度拟合。
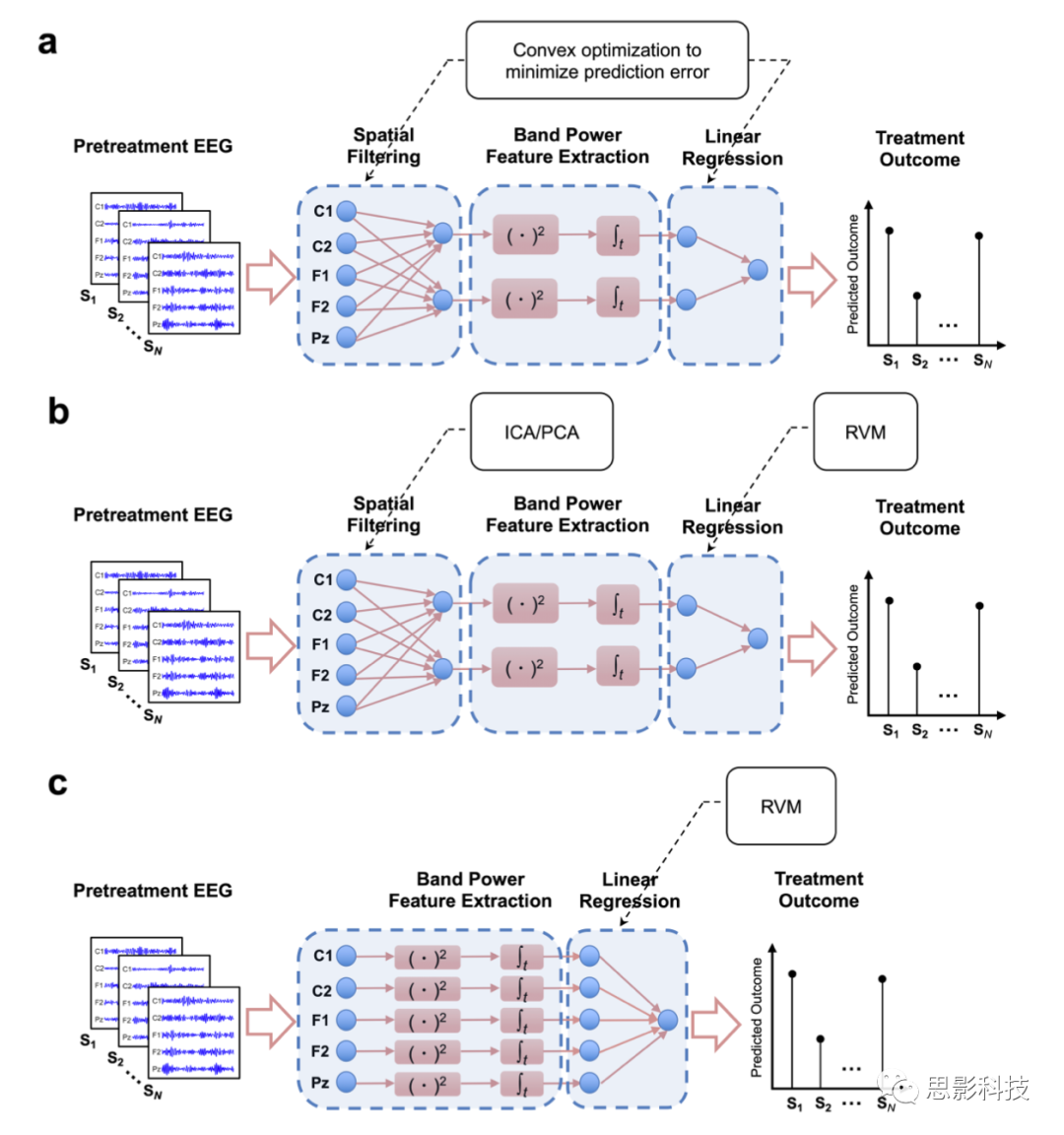
补充图10 不同的频带功率治疗预测方法的比较。a. SELSER的end-to-end预测。b. ICA/PCA预测。c. 通道水平上频带功率的预测。
2.SELSER的参数优化:Ci=XiXiT/N指EEG空间协方差矩阵。预测的治疗结果可表示为:

![]() 指矩阵的对角线元素之和。假设空间滤波器相互正交{Wk}Lk=1,{Wk}Lk=1和{βk}Lk=1是W的特征向量和特征值。通过执行W的特征分解获得{Wk}Lk=1and{βk}Lk=1,然后优化W。然而,在W和C(C + 1)/2中的未知参数明显多于训练样本,因此简单最小化预测误差容易导致模型过拟合。为解决此问题,除了最小化预期误差外,研究者将W秩(与L相同)作为惩罚项加入目标,以限制潜在信号的维数,从而产生以下优化问题:
指矩阵的对角线元素之和。假设空间滤波器相互正交{Wk}Lk=1,{Wk}Lk=1和{βk}Lk=1是W的特征向量和特征值。通过执行W的特征分解获得{Wk}Lk=1and{βk}Lk=1,然后优化W。然而,在W和C(C + 1)/2中的未知参数明显多于训练样本,因此简单最小化预测误差容易导致模型过拟合。为解决此问题,除了最小化预期误差外,研究者将W秩(与L相同)作为惩罚项加入目标,以限制潜在信号的维数,从而产生以下优化问题:

![]() 指W秩。然而,公式3要求非确定性多项式次数,并且秩惩罚不平滑。
指W秩。然而,公式3要求非确定性多项式次数,并且秩惩罚不平滑。

用作矩阵秩的凸代数,{δk}Lk=1指W的奇异值。使用W*代替W0,产生:

公式5是凸优化问题。用加速近端梯度法可以得到全局最小解。为消除由于整体功率变化而引起的被试间变异,对数据进行标准化:
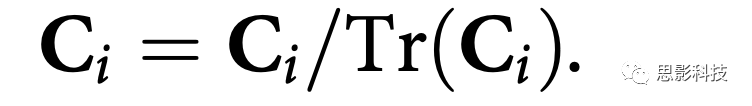
3. RVM(relevance vector machine,相关向量机):为了与SELSER进行比较,使用带有线性核的RVM建立稀疏线性回归模型,从non-SELSER优化特征进行治疗预测。RVM可以通过边际似然最大化自主选择预测相关特征,因此,RVM避免了需要额外的验证数据来确定超参数。4. 使用SELSER进行治疗预测:研究者将SELSER应用到每个EEG频带,以预测治疗结果。5. 潜在信号空间拓扑图的可视化:每个潜在信号都有一个空间拓扑图,可以在头皮和皮层可视化,以促进神经生理解释。计算头皮空间拓扑图:

As∈RC×L包含潜在信号的头皮空间拓扑图作为列,C=ΣCI∈RC×C是EEG信号的平均空间协方差矩阵,V=[W1,...,WL]∈Rĉ×LandCz=VTCV是潜在信号的平均协方差矩阵。为获得潜在信号的皮层空间拓扑图,基于FreeSurfer平均头模板,使用OpenMEEG计算三层边界头模型。共产生m个固定取向偶极子。通过边界元素模型获得lead-field矩阵B∈RM×C。通过sLORETA算法计算线性逆矩阵H∈RM×C(将EEG信号投射到皮层源)。
计算皮层空间拓扑图:
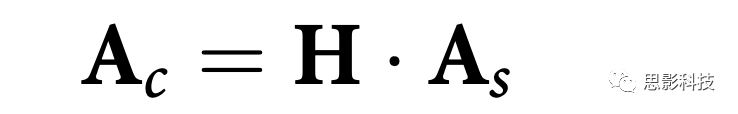
AC∈RM×L包含潜在信号的皮层空间拓扑图。EMBARC样本通过训练SELSER获得空间拓扑图的可视化。
6. 使用通道水平alpha功率或theta cordance特征进行治疗预测(cordance是QEEG一种新的应用,cordance结合EEG频谱的绝对和相对功率的互补信息,得到值,该值与局部脑区的相关性比单独测量的值更强):为了与基于通道水平测量的预测方法比较,研究者分别使用通道水平alpha频带和theta频带功率训练RVM。计算每个被试的theta cordance。Theta cordance被计算为空间标准化绝对和相对再分配theta功率。
7. 使用由ICA或PCA提取的潜在信号的功率特征进行治疗预测:分别使用ICA和PCA评估的潜在信号频带功率特征检测SELSER。本研究使用信息最大化执行ICA(Infomax)。基于ICA和PCA的预测框架与SELSER的流程相同(补充图10b)。首先,除以总功率的平方根,对每个患者的EEG信号进行标准化。然后,通过将ICA或PCA应用到EEG信号来估计潜在信号。将所有潜在信号的频带功率计算为特征,然后用线性核的RVM将频带功率特征与HAMD分数变化进行联系。
8. 使用交叉验证方法进行性能评估:使用分层十折留一交叉验证法(tenfold leave-subject-out cross-validation)评估每种预测方法的预测性能(补充图2)。将数据随机分为10个子集,一个子集用作测试数据,并且剩下的九个数据用于训练数据。对于SELSER,对训练数据使用内部十折交叉验证方法确定正则化参数λ,该过程重复10次。结果,每个患者都有一个预测的HAMD分数变化。为提高预测的稳定性,对数据进行10次随机,并对随机数据进行分层十折交叉验证。以每个患者10次预测HAMD分数变化的中位数作为最后的预测。通过交叉验证预测的HAMD分数变化和真实的HAMD分数变化之间的皮尔逊相关系数。量化预测性能。在分层10×10交叉验证的每折中,将预测模型应用到其他治疗数据中检验预测的特异性,通过取100折交叉验证的中位数总结每个被试的预测模型。
9. 统计检验:使用非参置换检验评估治疗预测结果的统计显著性。观察到的HAMD分数变化被置换1000次,每次重复交叉验证的预测过程,就得到了皮尔逊相关系数的分布。将P值定义为大于未置换的交叉验证相关系数的交叉验证相关系数比例。
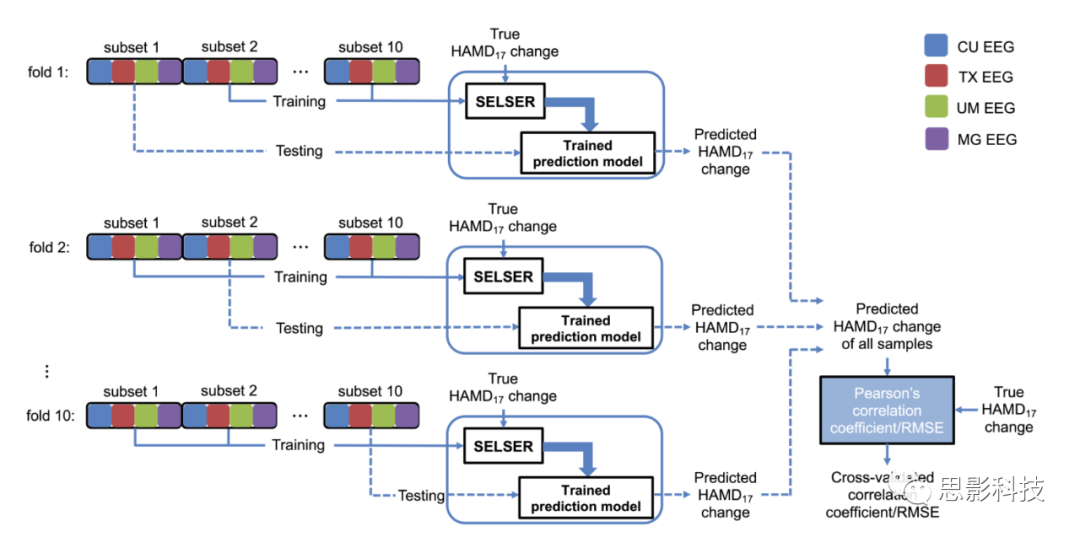
补充图2 使用10倍分层交叉验证的SELSER训练和评估说明
机器学习模型在重度抑郁患者数据中的应用:
1. 在第二个样本中计算rsEEG预测:研究者将采用第一个EMBARC舍曲林样本训练的alpha SELSER模型应用到第二个重度抑郁症样本中(72名重度抑郁症患者的rsEEG数据)。由于37名患者的EEG数据采用新的放大器记录,因此,在第二项研究中,对训练模型的EMBARC数据和37名患者的EEG数据进行了平均去除位点校正程序,如leave-study-site-out分析。将rsEEG数据输入公式(1)(见上文),产生EMBARC SELSER模型的预测。通过取100折交叉验证的中位数总结每个被试的预测模型。这在第二个样本中产生了对每个样本EMBARC SELSER模型表达强度的测量,表达为每个患者一个预测的HAMD变化。鉴于本研究的重点是测试EMBARC舍曲林-预测特征在独立样本中的推广性,研究者比较ATRQ治疗顽固患者和发作期内对抗抑郁药治疗有部分反应的患者的SELSER模型预测的HAMD变化分数进行比较。
2. 在第三个样本中计算rsEEG预测:研究者将采用第一个EMBARC舍曲林样本训练的alpha SELSER模型应用到第三个重度抑郁症样本中(24名重度抑郁症患者的rsEEG数据)。由于EEG数据采用新的放大器记录,因此,对数据进行了平均去除位点校正程序,如leave-study-site-out分析。由于该样本与EMBARC样本的通道排布不同,EMBARC SELSER模型不能直接应用于该样本。为解决该问题,研究者基于与EMBARC相似的线性逆矩阵对该样本rsEEG数据进行源定位,然后通过EMBARC的lead-field矩阵将源活动投射到EMBARC电极。接着,将在EMBARC电极投射的rsEEG输入公式(1),产生EMBARC SELSER模型的预测。通过取100折交叉验证的中位数总结每个被试的预测模型。
3. 在第三个样本中计算任务相关fMRI预测:在第三个样本中计算任务相关fMRI预测:研究者将先前描述的RVM模型(由情绪冲突任务态EMBARC fMRI数据)应用到第三个重度抑郁症患者样本中。采用分离方法(局部梯度分析和全局信号相似性结合到独立的静息态fMRI队列上)对ROI区域进行提取。由于功能分离依赖于静息态连接模式,研究者从200、400和600个区域划分ROIs,以限制划分相关的特异性,基于ROI与网络间的空间重叠,ROI被映射到七个先前定义的功能网络。除了这些皮质ROIs外,皮质下ROIs还包括杏仁核、前、后海马和丘脑的纹状体和小脑旁。然后,研究者在RVM模型的每一次运行时,在训练集中使用多元线性回归对这些数据中的成像位点进行回归,然后利用剩余的脑信号预测HAMD评分变化,并在每次交叉验证中训练RVM模型。通过取100折交叉验证的中位数总结每个被试的预测模型。研究者第三个样本的fMRI数据采用相同的方式进行预处理,并将EMBARC权重向量应用于提取的ROI数据,以确定每个被试EMBARC fMRI RVM模型的强度。
4. 在第三个样本中计算spTMS和EEG与rsEEG预测的相关:为量化第三个样本中,spTMS和EEG反应与EMBARC定义的rsEEG表型之间的相关,研究者使用SELSER从spTMS和EEG数据学习预测模型,以进行rsEEG预测,并计算预期的rsEEG预测和真正的rsEEG预测的留一法交叉验证皮尔逊相关系数。分别对七个刺激位点进行SELSER分析(bilateral pDLPFC, bilateral aDLPFC, bilateral M1 and V1),使用与rsEEG预测分析中相同的频带(theta,alpha,beta和gamma)和相对于TMS脉冲的三个时间窗(0–200 ms, 200–400 ms and 400–600 ms)。对于每个SELSER分析,将spTMS和EEG数据串联起来。经过FDR校正后,对所有SELSER进行显著性评估(stimulation sites × frequency bins × time windows)。
5. 在第四个样本中检验rsEEG预测和治疗结果之间的关系:研究者使用平均位点移除程序计算每个患者EMBARC训练的SELSER rsEEG模型的表示(表示为预测的HAMD变化)。接下来在SELSER rsEEG产生的预测HAMD变化与BDI、DASS子量表之间计算线性混合模型。术语是时间,预测的HAMD变化,预测HAMD×时间变化,采用随机截距和固定斜率。然后采用Bonferroni矫正。
结果
SELSER的开发
研究者开发SELSER(图1),并识别一个可以预测抗抑郁药反应的EEG稳定特征:
(1)通过空间滤波器放大信噪比,进一步实现信号识别,并减少容积传导的影响。每个空间滤波器将多通道EEG数据转换为单个潜在信号,其功率作为机器学习算法的特征。
(2)模型拟合是在空间滤波器数目的稀疏约束下进行,有助于减少潜在信号的维度,从而减少过度拟合的可能。
(3)研究者提出结果预测框架,作为一个直接与治疗结果相关的EEG时间序列的凸问题求解,得到单一的全局最优解。研究者预测SELSER-建立的来源于theta和alpha频带的神经信号将是治疗结果的强预测因子。
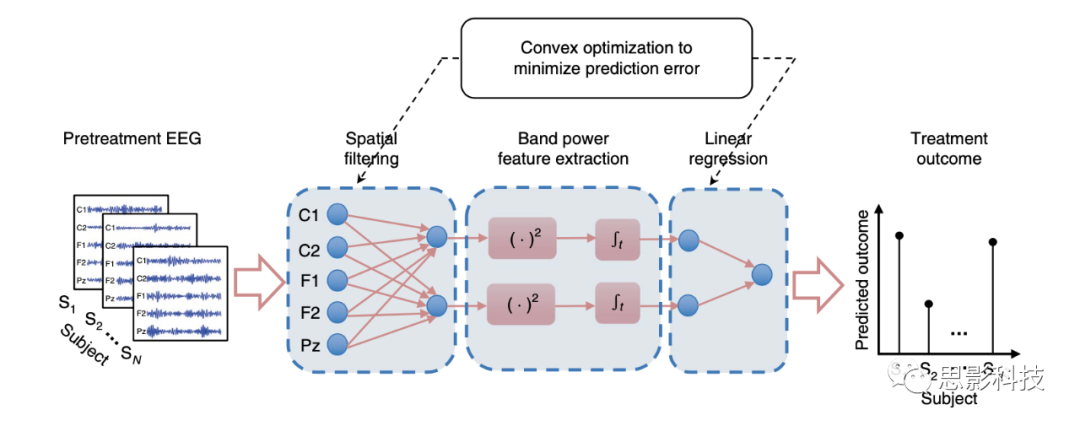
图1 使用潜在空间模型对治疗结果的end-to-end预测。
模型分为3步:空间滤波,将EEG信号线性转换为潜在信号;频带功率特征提取,计算每个潜在信号的频带功率;线性回归,使用频带功率预测治疗结果。
使用SELSER从治疗前rsEEG特征预测治疗结果:
研究者使用治疗前的rsEEG(两个2min睁眼blocks,和两个2min闭眼blocks),通过将SELSER应用到4个EEG频带(theta: 4-7Hz; alpha: 8-12Hz; beta: 13-30Hz; gamma: 31-50Hz),建立预测模型。通过治疗前、后的HAMD评分差异量化治疗结果。使用10折交叉验证检验模型性能(图1, 补充图2)。
对于舍曲林组,在交叉验证过程中,仅睁眼rsEEG(REO)的alpha信号对治疗评分变化有显著的预测作用(图2a; 使用Bonferroni矫正以及置换检验,置换次数为1000)。然而,当将舍曲林-训练模型应用到安慰剂组,则不能预测结果(图 2b),这证明该模型对舍曲林疗效预测的特异性。然而,将SELSER应用到alpha频带REO rsEEG信号,结果表明不能预测基线HAMD评分。因此,治疗-预测的模型与基线抑郁的严重程度无关。
由于SELSER算法对潜在信号实现的低维约束,因此在每个模型中只得到几个潜在的信号(补充图3)。对于舍曲林alpha REO模型,最正回归权重的潜在信号主要集中在右侧顶枕叶;相反,最负回归权重的潜在信号主要集中在外侧前额叶和枕旁脑区(图2c,d)。
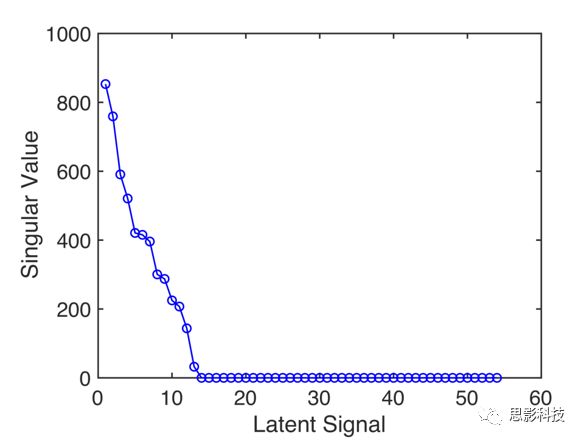
补充图3 EMBARC的曲舍林与alpha SELSER潜在信号相关的奇异值

图2 使用SELSER和REO alpha-频带数据对舍曲林组的结果预测。
a. 使用SELSER对舍曲林组的HAMD变化10×10折交叉验证预测。
b. 舍曲林训练模型未能预测安慰剂组的结果,证明了舍曲林预测模型的特异性。
c. SELSER潜在信号的头皮空间模式。
d. SELSER潜在信号的皮层空间模式。
e. rsEEG预测特征的效果的可视化。根据舍曲林组交叉验证预测的HAMD分数变化,将每组患者分为高低组。SER:舍曲林组;PBO:安慰剂组。
f. 使用alpha REO舍曲林模型和leave-study-site-out cross-validation方法的治疗预测。
研究检验数据量对模型拟合的影响,结果发现当每个患者使用少于1.5min的两个blocks时,模型性能降低(补充图4和补充图5)。
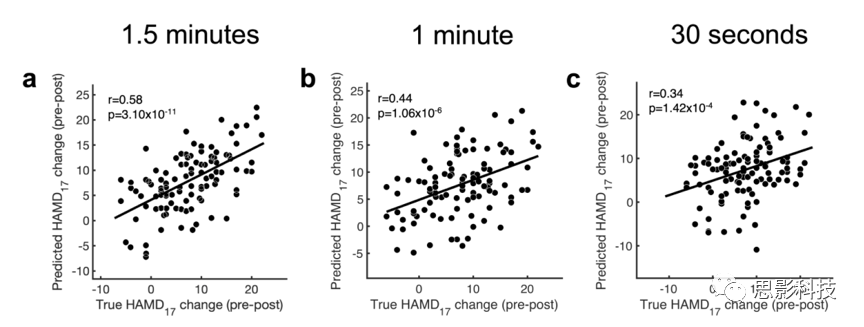
补充图4使用SELSER对静息睁眼不同长度的alpha频段数据进行训练,预测特定于曲舍林的结果(n = 109)

补充图5使用SELSER对静息闭眼不同长度的alpha频段数据进行训练,预测特定于曲舍林的结果(n = 109)
对于安慰剂组,alpha REO和REC信号显著预测HAMD评分变化(图3a, 3c)。对于REO条件,潜在信号主要集中在颞叶和枕叶脑区;而对于REC条件,主要集中在额-顶叶和额叶脑区(补充图6)。当将该模型应用到舍曲林组时,两个回归模型均未预测结果,这表明该模型对安慰剂结果预测的特异性,以及与上述舍曲林-预测模型的区别。

图3 使用SELSER和alpha-频带数据对安慰剂组的结果预测。
使用SELSER对安慰剂组的HAMD变化10×10折交叉验证预测,a. REO数据;c. REC数据。b. d., 将安慰剂模型应用于舍曲林组。SER:舍曲林组;PBO:安慰剂组。
补充图6 安慰剂(PBO) alpha SELSER潜在信号的头皮和皮层空间模式(n = 119)
为了将SELSER预测治疗结果(图2a)进行可视化,研究使用预测的HAMD分数变化(来源于舍曲林alpha REO模型)的中值将患者进行分组。然后,根据模型预测的HAMD评分变化计算高于中位数(high)和低于中位数(low)的患者的治疗反应率(症状上≥50%的减少)(图 2e)。对于舍曲林组,high组达到65%的反应率,显著高于low组(20%)和安慰剂组的反应率(high:35%;low:34%)。
跨研究站点的治疗预测
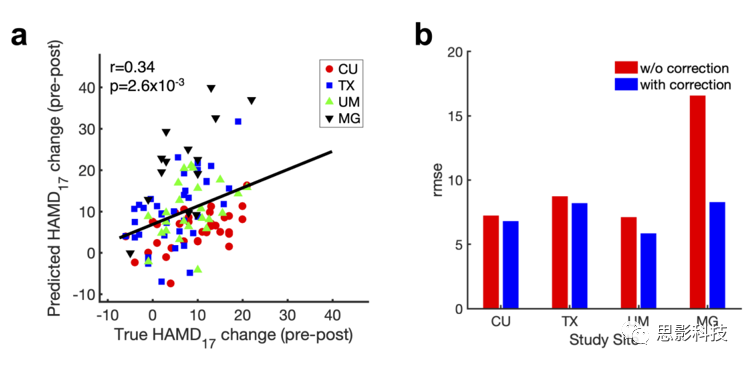
为评估预测模型对不同EEG放大器收集数据的推广性,使用三个站点的数据训练模型,第四个站点数据测试模型来执行leave-study-site-out分析。由于4个站点的EEG数据使用不同的EEG放大器和/或通道排布模式,因此不同研究地点中模型的预测的性能不同(补充图8)。为减少由于放大器不同而带来的影响,在SELSER分析之前,从每个站点删除协方差矩阵的平均值。对于舍曲林组,当执行leave-study-site-out交叉验证时,alpha REO模型可显著预测治疗结果(图2f)。这表明使用不同的放大器不会影响数据的稳健性,所有站点的4折交叉验证模型仍具有很强的预测性。通过所有站点的2折交叉验证进一步限制样本大小,结果发现了较低但仍然显著的预测性能。对于安慰剂组,结果发现REO或REC模型无法预测治疗结果。舍曲林leave-study-site-out alpha REO预测模型在预测舍曲林反应时优于安慰剂组,仍然显示出显著更好的特异性。
补充图8 站点校正对交叉验证性能的影响(n = 109)
SELSER模型预测与以往方法的比较
为了将SELSER与不使用潜在空间模型的传统机器学习方法进行比较,研究通过使用关联向量机(relevance vector machine; RVM)和通道水平REO alpha频带功率、theta频带功率以及theta cordance特征,训练线性回归模型。然而,模型没有成功预测治疗结果。而且,为了证明SELSER相对于传统潜在空间模型方法的改进,研究使用潜在信号的alpha频带功率(用PCA或ICA提取)训练RVM,这是从EEG中提取空间滤波器的最流行的无监督方法之一(补充图10)。但是,两个模型都没有成功预测治疗结果。
症状的治疗预测
如果使用低成本的测量,如临床评分、人口学变量或儿童创伤等历史条件等进行预测,RVM的预测性仅达到中等水平,若仅使用Quick Inventory of Depressive Symptomatology分数(QIDS,抑郁症状的快速清查)进行预测,其表现将更加糟糕(补充图11)。加入临床测量的舍曲林结果预测也显著弱于上述的alpha rsEEG模型。
补充图11 机器学习从症状预测治疗结果
检验rsEEG舍曲林-预测特征的推广性
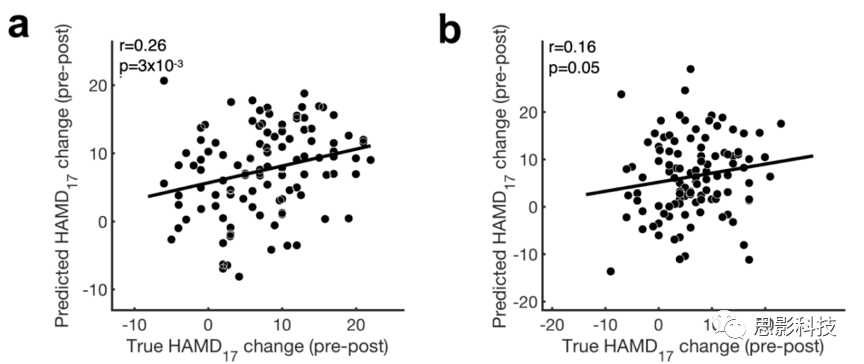
在第二个抑郁症样本中,检验从EMBARC得到的SELSER rsEEG舍曲林-预测特征的推广性。患者分为治疗顽固的(两个或者以上的失败抗抑郁药试验,n=21)或部分反应者(至少有一种有部分反应)。
首先,对rsEEG数据进行平均去除位点矫正,并对数据进行leave-study-site-out分析。接者,将EMBARC-训练舍曲林alpha-频带rsEEG模型应用到每个患者,结果发现了一个可预测的HAMD变化,这反映了舍曲林-预测rsEEG特征表征的强度。部分反应者的预测HAMD改变显著高于治疗顽固组(图4),这说明EMBARC rsEEG舍曲林特征对更广泛治疗反应的推广性。此外,45/72名患者获得了抑郁期间失败的抗抑郁药物试验的数量信息,发现失败试验数量与rsEEG舍曲林特征预测HAMD提高的幅度具有负相关。
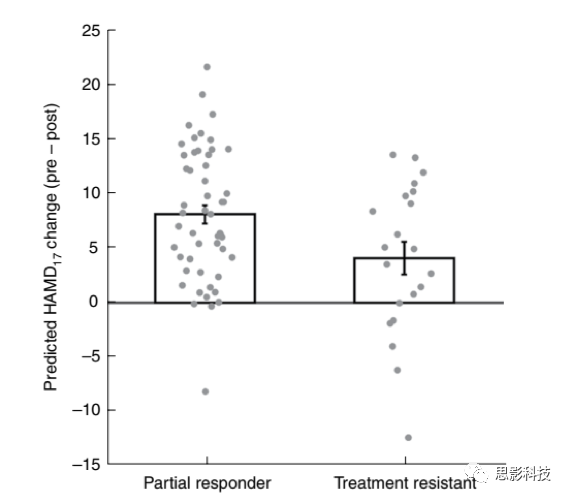
图4 将EMBARC训练的舍曲林rsEEG模型应用到第二个样本中,预测治疗结果。
rsEEG-和任务态-fMRI的机器学习预测的收敛性
为检验EMBARC舍曲林rsEEG模型的收敛性,对24个抑郁患者的rsEEG和情绪冲突任务过程中的任务态fMRI数据,验证其基于EMBARC训练的舍曲林rsEEG模型预测的HAMD变化是否与任务态fMRI机器学习模型预测的HAMD变化相关。
首先,进行平均移除位点矫正。rsEEG与任务态fMRI的预测显著相关(图5a),这一发现为抑郁症存在治疗反应的神经生物学表型提供了跨人群和跨评估模式的收敛性。
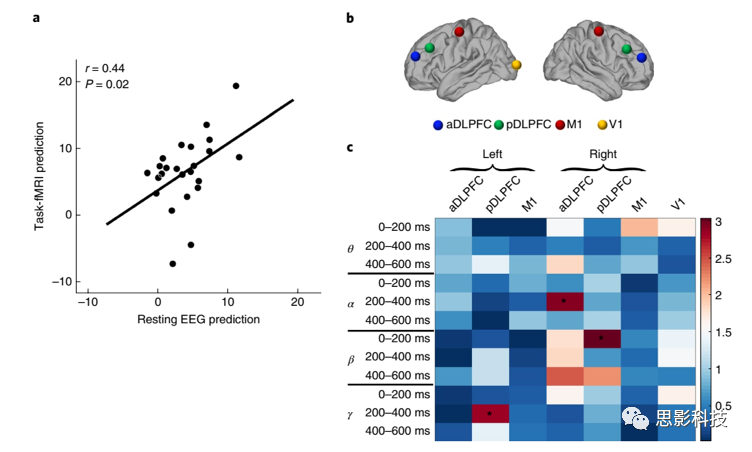
图5 rsEEG模型预测的HAMD变化和任务态fMRI机器学习模型预测的HAMD变化,并通过同步spTMS和EEG评估神经反应
a. rsEEG模型预测的HAMD变化和任务态fMRI机器学习模型预测的HAMD变化的比较。
b. rsEEG表型相关的同步spTMS和EEG。
c. 同步spTMS和EEG反应与舍曲林预测的rsEEG SELSER特征的相关。
rsEEG表型的TMS和EEG相关性
为进一步证明舍曲林-预测rsEEG-识别表型的神经信号,研究分析第三个样本的同步单脉冲TMS和EEG数据(spTMS和EEG)。研究检验皮质响应是否能诱发与rsEEG-识别的治疗预测表型相关的神经反应。
刺激脑区有:双侧后部背外侧前额叶皮层(pDLPFC)、前部DLPFC(aDLPFC);对照脑区有:初级视觉皮层(V1)、双侧初级运动皮层(M1)(图5b)。为量化spTMS和EEG反应与舍曲林-预测rsEEG表型之间的相关,使用SELSER将spTMS和EEG数据与舍曲林rsEEG特征联系起来(图5c)。舍曲林rsEEG表型与3/4个前额皮层脑区的spTMS和EEG刺激反应之间的关系经过了多重比较矫正,脑区包括:右侧aDLPFC刺激(alpha频带,200-400ms)、左侧pDLPFC刺激(gamma频带,200-400ms)、右侧pDLPFC刺激(beta频带,0-200ms)。然而,初级运动皮层或初级视觉皮层的刺激反应的相关没有经过矫正。
rTMS和心理治疗结合研究中的舍曲林特征评估
为检验舍曲林rsEEG表型的强度是否可以预测抑郁症rTMS治疗的结果。首先,使用平均位点移除方法计算EMBARC训练舍曲林rsEEG模型对每个患者的表征(预测的HAMD改变)。结果发现,舍曲林rsEEG-预测HAMD变化与DASS测量1Hz rTMS反应呈负相关(图6)。这表明无法对舍曲林作出反应的患者更容易接受1Hz右侧DLPFC rTMS,这为抑郁症提供了一种潜在的基于证据的治疗方法。由于当将组别纳入线性回归模型中时,研究者发现治疗方案×预测HAMD改变×时间的交互作用显著,因此,这种关系特异于1Hz右侧DLPFC rTMS。
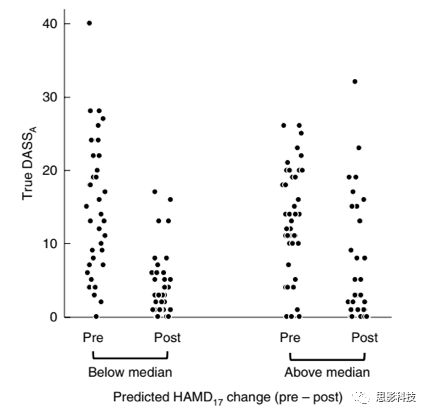
图6 使用EMBARC-训练的舍曲林rsEEG模型对右侧DLPFC 1Hz rTMS治疗结果的预测
结论:
此研究发展了一个rsEEG优化的潜在空间计算机模型(SELSER),该模型在一个大型安慰剂对照研究中能够稳健预测抗抑郁药结果以及其和安慰剂的区别。使用SELSER方法和alpha频带睁眼rsEEG数据识别的抗抑郁药-预测特征优于传统的机器学习模型或潜在模型方法(ICA和PCA)。这一特征的预测性能不受研究地点以及EEG放大器、通道排布的影响。SELSER模型的属性支持其在临床护理和未来抑郁症研究中(基于个体预期的抗抑郁药物特异性治疗结果)的潜在作用。总的来说,SELSER模型能够稳健地预测抗抑郁药舍曲林的治疗结果,并在单个患者水平上区分舍曲林和安慰剂的反应,这可能进一步支持药物和rTMS之间的治疗选择。
原文:An electroencephalographic signature predicts antidepressant response in major depression

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
更新通知:第十届脑影像机器学习班(已确定)
磁共振脑影像结构班(预报名)
弥散磁共振成像数据处理提高班(预报名)
小动物磁共振脑影像数据处理班(预报名)
更新通知:第二十届脑电数据处理中级班(已确定)
脑电信号数据处理提高班(预报名)
眼动数据处理班(预报名)
近红外脑功能数据处理班(预报名)
数据处理业务介绍:
招聘及产品:
招聘:脑影像数据处理工程师(重庆&南京)