

研究亮点
l 感知运动皮层加工发音运动轨迹(articulatory kinematic trajectories, AKTs)
l AKTs揭示了舌头、嘴唇、下巴和喉部的协调运动
l AKTs表现为声道发音器官的刻板轨迹
l AKT表征由于发音器官运动导致的上下文相关运动的编码
流利的语言表达需要精确的声道运动。Chartier等人研究声道运动在感觉运动皮层上的编码。该研究发现,单电极神经活动可以编码不同的运动轨迹,这些运动轨迹是产生自然语言的复杂运动轨迹基础。本文发表在Neuro杂志。
文献导读
人们在说话时,会动态协调下巴、舌头、嘴唇和喉部运动。为了研究发音的神经机制,研究者在参与者使用包含全部英语语音进行自然语言表达时,直接记录感觉运动皮层的神经信号。研究者们使用深层神经网络从产生的语音声学信号中推断出说话者的发音运动。单个电极编码不同的发音运动轨迹(AKTs),每一个都显示了特定声道形状的发音器官协调运动。AKTs能捕捉到多种不同的声带运动类型并且可以根据声带收缩的部位来区分。此外,AKTs还表现出与谐波动态变化相关运动前后的轨迹。虽然AKTs在不同句子中的功能具有一致特性,在同一音位产生过程中,上下文相关的动作前后的编码反映了协同发音的皮层表征。感觉运动皮层的发音运动编码产生了连续语音发音的复杂的运动轨迹基础。
研究背景
为了能够产生流利地表达,研究者们用近100块肌肉来完成一项运动控制任务,以快速塑造和重塑发声系统,产生连续的语音片段进而形成单词和短语。发音器官(嘴唇,颌骨,舌头和喉部)的运动是精确协调的,以产生特定的声道模式。先前的研究通过语言特征(例如,音位--成熟的声音研究单位)对这些动作进行编码,发现了腹侧感觉运动皮层(ventral sensorimotor cortex,vSMC)中的神经编码与假定的潜在发音运动有关。然而,完全理解vSMC神经群如何表征语音产生过程中的实际发音运动仍然存在两方面的挑战。
1)如何超越大多数研究中采用的实验上方便的方法?即,从在孤立的语音段中的研究vSMC,朝着研究自然、连续语音产生中的更丰富、更复杂的运动动力学方向发展。
2)如何超越范畴语言特征(如音位或音节),去描述运动的精确表征?即,研究真实的发音运动轨迹。
克服这些挑战对于理解流利表达至关重要。虽然语音通常被描述为在任何给定时间具有局部不变性的离散成分的组合(即音位或发音系统姿态,但是语音片段产生的发音运动仍可能受到先前和即将出现的语音片段(称为协同发音)的影响。例如,在“cool”中,在/k/后会出现/u/所需的圆形唇形,而在“keep”中,/k/则在预期出现/i/时被颚化。所以,研究的核心问题仍然是,大脑皮层控制是否调用这些原始运动模式组合来执行更复杂的任务?
为了解决这些问题,研究者们使用高密度颅内脑电图(ECoG)记录被试大声说出完整句子时的脑电信号。关注连续表达的句子有助于研究独立音节发音时无法获得的发音器官运动的动态协同功能。此外,由于自然语音中可能存在各种各样的发音运动,因此研究者使用的句子覆盖了美式英语中几乎所有的语音和发音环境。此方法能够根据声带运动来表征语音产生过程中的感觉运动皮层活动。
研究自然语言机制的一个主要障碍是,只能用高时空分辨率的跟踪舌运动的专用工具来监测内声带运动的持续时间,而这些工具大多与颅内记录不兼容,也不适合捕捉自然语言言语模式。为了克服这个障碍,研究者们开发了一种一种统计方法,可以从产生的声学信号推导声道运动。然后,使用推断出的发音运动轨迹来确定发音运动的神经编码,以一种与模型无关且不可知的方式来确定语音生成中使用的预定义发音和声学模式(例如音位和姿态)。并通过学习发音运动和电极神经活动如何组合,估计单个电极的发音运动轨迹(AKTs),并通过语音vSMC描绘发音运动的异质性。
研究方法
参与者
研究共招募5名女性参与者,在大脑侧面高密度硬膜下慢性植入电极阵列(2个左半球网格,3个右半球网格)作为癫痫临床治疗的一部分。在手术前签署书面知情同意。
实验任务
要求参与者朗读来自MOCHA-TIMIT数据库的460个句子。实验共包括9个block(其中8个包含50个句子,1个包含60个句子),在患者住院的几天内执行实验任务。每个block中,在屏幕上呈现句子,一次一个,让参与者朗读。句子的顺序是随机的。MOCHA-TIMIT是一个句子级别的数据库,是TIMIT语料库的一个子集,旨在覆盖美式英语中的所有语音文本。参与者将每句话读1-10遍。麦克风录音与ECoG记录是同步的。
数据采集和信号处理
使用Tucker Davis Technologies多通道放大器连接数字信号,记录皮层脑电。语音经过数字放大,并通过麦克风与皮层信号同时进行记录。ECoG电极排列成16*16,间距为4mm,放置由临床因素决定。记录时的采样率为以3052hz。对每个通道进行目测和定量检查,以确定是否存在伪迹或过度噪声(60Hz的工频干扰)。用Hilbert变换提取局部场电位(70~150hz)的high-gamma频段的振幅,并将其降采样到200hz。最后,将30 s窗口内的信号使用平均值和标准差进行z分数转化,以便对不同的数据进行标准化。研究使用high-gamma频段的振幅,因为它与多单元放电率(multi-unit firing rates)的相关性好,并且具有解决精细发音器官运动的高时间分辨率。
语音和音位记录
对于收集到的语音录音,在单词的层面进行人工校正,以反映参与者实际发出的声音。根据句子级别的录音和声学信息,为每个参与者建立了基于hidden Markov模型的声学模型,以实现亚语音(sub-phonetic)对齐。根据语音、音节和词的上下文产生语音上下文特征。
与说话者无关的声学-发音转换(acoustic-to-articularoty inversion, AAI)
为了对只有声学数据可用的参与者进行发音逆推,我研究者发明了与说话者无关的声学-发音转换(acoustic-to-articularoty inversion, AAI)法,模拟参与者的并行的EMA(electromagnetic midsagittal articulography)和语音数据。
小编注:EMA是一种可以清晰的看见参与者在发音时每个部位(唇、舌头、喉咙、下巴)的运动变化。
使用8名EMA参与者的声谱特征与想要推断声道运动轨迹的5名目标参与者进行匹配,对EMA参与者的声谱特征进行声音变换,以令每个EMA的声谱数据都与目标参与者的相匹配,来实现将所有声学数据应用到目标参与者的转换。该方法假设两个参与者的声学数据对应相同句子。
由于没有关于目标参与者的运动轨迹信息,研究者对8名EMA记录者的发音空间的平均值进行标准化。为了对运动数据能在参与者间使用利用,对于每个EMA数据上进行特定的发音z分数变换。确保目标参与者的发音运动轨迹在所有可用的EMA数据中是一个无偏的平均值。运动轨迹由13维特征向量描述(12维表示6个声道点的X、Y坐标,基频F0表示喉功能)。
使用24维mel-cepstral系数作为声谱特征。运动轨迹和声学的采样频率均为200hz(每个特征向量代表一段5ms的语音)。此外,每一帧语音对应的音位和语音信息被编码为一维有效编码(one-hot vector),并填充到声学特征上。这些特征包括音位同一性、音节位置、词性、当前及相邻音位和音节状态的位置特征。结果发现,前后背景数据为声学提供了补充信息,提高了逆推精度。
针对目标参与者创建并行语音数据集和EMA数据的模拟数据集,这两个数据集都是针对目标参与者定制的。为了训练逆推模型,使用基于深度递归神经网络的发音逆推技术来学习从声谱和语音背景到说话者通用发音空间的映射。本研究选择具有两个前馈层(200个隐藏节点)和两个双向LSTM(long short-term memory)层(100个LSTM cells)的4层深度递归网络的最优网络结构。然后将训练好的逆推模型应用于目标参与者的所有语音,以笛卡尔X坐标和Y坐标的形式推断出发音器官运动。该网络是使用Keras实现的,它是一个在Tensorflow后端运行的深度学习库。
电极选择
选择中央前回和中央后回的电极,因为它们在言语产生过程中具有明显的high-gamma活动。我们用一个给定电极的类间与类内的变化率(F统计量)来测量音位的可分性。选择F最大值大于或者等于8的电极。5名参与者中,总共有108个电极在语音产生过程中具有强大的活动性。
编码模型
为了揭示电极所代表的运动轨迹,我们使用线性编码模型来描述在每个电极上记录的high-gamma活动,作为一个随时间变化的发音器官运动轨迹加权和。在我们的模型中,使用了发音器X和Y坐标来代替声谱成分。该模型估计每个电极i的时间序列Xi(t)作为发音器官运动器A的卷积,包括运动轨迹参数K和滤波器H,我们将其称为电极的发音器官运动轨迹(AKT)编码。

将声学和音位编码模型与电极活动相匹配。用共振峰(F1、F2和F3)代替发音器的X和Y坐标来描述声学信息和句子中产生的音位。每一个特征的1或0分别表示一个特定的音位是否产生。
编码模型用ridge回归拟合,用交叉验证训练数据,70%的数据用于训练,10%的数据用于估计ridge参数,20%作为最终测试集。最后测试由完全独立于训练句子的录音中的句子组成。测试模型预测响应与最终测试集中测量的实际高high-gamma之间的相关性。
层级聚类
使用Ward的方法进行聚集层次聚类。对每个电极的编码运动轨迹的运动描述单独进行电极聚类。为了为每个运动轨迹开发简明的运动轨迹描述,提取了个发音器官的最大位移点。用主成分分析法对每一个发音器提取解释方差最大的发音器方向。然后,将滤波器权重映射到每个发音器官的第一主成分上,并选择最大值的点。根据每个电极的音位编码权重对音位进行聚类。对于给定的电极,在给定的电极的最大音位可辨别性点处,提取长度为100ms的时间窗中每个音位的最大编码权重。
皮层表面提取和电极可视化
为了观察参与者大脑皮层表面的电极,在SPM12进行配准并结合T1及CT显示电极位置。用Freesurfer重建软脑膜表面。为了在MNI空间观察参与者的电极,在Freesurfer中使用基于球面sulcal的对齐方式进行了非线性表面配准,并与mni152模板中的cvs avg35对齐。
解码模型
为了解码发音运动,研究者们训练了一个长短期记忆(LSTM,long short-term memory)递归神经网络来学习从high-gamma活动到发音运动的映射。LSTM特别适合学习具有时间相关信息的映射。LSTM使用500 ms时间窗的high-gamma活动,从所有vSMC电极中,以解码样本为中心,预测每个发音器官位置样本。解码器结构是一个4层的深度递归网络,具有两个前馈层(每个100个隐藏节点)和两个双向LSTM层(100个cell)。使用Adam优化和丢弃(dropout )(40%的节点),训练网络以减少解码和实际输出的均方误差。该网络是使用Keras实现的,它是一个在Tensorflow后端运行的深度学习库。
量化和统计分析
嵌套编码模型比较
使用嵌套回归模型来比较单个发音器官轨迹的神经编码与AKT模型。对于每一个电极,我们使用每个EMA传感器的X和Y方向拟合单个发音器官轨迹模型,并选择对保留数据具有最小残差平方和(RSS)的单个发音器官模型。根据完全(2)和嵌套(1)模型的RSS值,我们通过计算每个电极的F统计量来比较解释方差的显著性。

p和n分别是RSS计算中使用的模型参数和样本数。当F统计量大于由两个模型中参数个数和置信区间定义的临界值时,说明在考虑参数个数的差异后,全模型(AKT)在统计学上显著解释了比嵌套模型(单个发音器)更多的方差。
相关结构比较
为了测试语音响应电极在low-gamma活动期和high-gamma活动期之间,发音器的相关结构(EMA点)是否不同,基于给定电极的high-gamma活动z分数是否高于阈值(1.5),将推断出的发音器运动分成两个数据集。然后从每个数据集中随机抽取1000个发音器官运动点,构建两个发音器官间的交叉相关结构。为了量化相关结构之间的差异,计算两个结构之间的欧氏距离(Euclidean distances)。然后,从低于阈值的数据集中额外抽取1000个点,以量化亚阈值(sub-threshold )数据中相关结构之间的差异。我们对每个电极重复这一过程1000次,使用Wilcoxon秩和检验(经过Bonferroni检验)比较欧氏距离的两种分布,以确定发音器官的相关结构是否与电极的高或低频gamma活动有关。
轮廓分析
为了评估聚类的可分性,计算每个电极的轮廓指数,基于给定特征比较每个电极与它自身聚类的匹配程度。通过计算同一聚类内所有电极的平均不相似度与最近聚类内电极的平均不相似度之差,计算出电极的轮廓指数。然后,通过取两个度量中的最大值来规范化该值。轮廓指数接近1表明电极与其自身的聚类高度匹配。0表示聚类可能重叠,而-1表示电极可能分配给错误的聚类。
音位选择性指数(PSI)
为了确定每个电极的音位选择性,我们使用Mesgarani等人(2014)描述的统计框架,来测试在两个不同音位的产生过程中,电极的high-gamma活动是否存在显著差异。对于一组音位对和一个给定的电极,根据与每个音位对齐的数据创建了两个high-gamma活动分布。使用非参数统计假设检验(Wilcox秩和检验)来评估这些分布是否有不同的中位数(p<0.001)。PSI为0表示没有其他音位具有不同的(可区分)的high-gamma活动,PSI为40则表明其他所有音位都具有不同的(可区分的)high-gamma活动。
混合效应模型
为了研究high-gamma与联合发音运动轨迹之间的关系,使用具有多个交叉随机效应的混合效应模型。对于给定的电极,在目标音位产生期间,以该电极的F峰值为中心的50 ms窗口期间取high-gamma活动的中位数来计算“活动峰值”。然后,取每个唯一音位对(目标音音vs上下文音位,其中目标音位前面是上下文音位)的平均活动峰值。对于每个电极,只考虑PSI>25的音位对。在图6C、6D、6H和6I中,将/z/扩展为包含/z/和/s/,并将/p/扩展为包含/p/和/b/,因为从EMA的角度来看,发音几乎相同,它增加了可以分析的联合发音实例的数量,从而减少了来自其他上下文效果的偏差和来自噪声的可变性。并计算由AKT模型预测的high-gamma活动,以提供对特定音位对产生过程中的运动轨迹的洞察。为了确定模型的优度,使用方差分析将模型与保留交叉随机效应但去除固定效应的嵌套模型进行比较。混合效应模型使用R中的lme4包进行拟合。
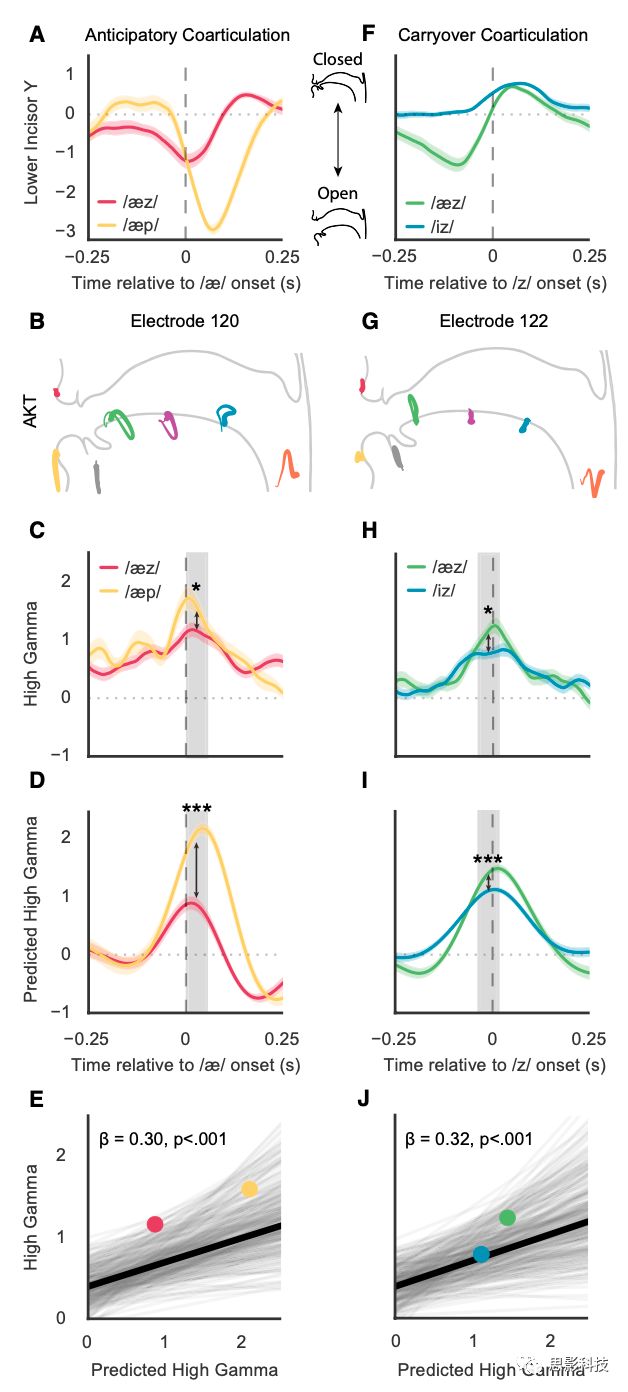
图6.发音器官运动轨迹的神经表征
(A)下门牙不同程度的预期发音器官发音的示例。显示了针对/æz/和/æp/的下切牙(y方向)的平均迹线,该平均迹线与/æ/的声学发作对齐。
(B)电极120密切相关地参与到元音AKT(下颌张开和喉咙控制)/æ/的产生,并且对/æ/具有高的语音选择性。
(C)在/æz/和/æp/的产生期间,电极120的平均high-gamma活动。
(D)由(B)中AKT预测的high-gamma活动平均预测。
(E)混合效应模型显示了high-gamma活动与运动变异性的关系,这是由于所有电极和音位的后续音位的预期联合发音效应(β=0.30,SE=0.04,ϰ2(1)=38.96,p=4e-10)。
(F)下门牙不同程度保留联合发音示例。显示了针对/æz/和/ iz /的下切牙(y方向)的平均迹线,该平均迹线与/ z /的声学起点对齐。
(G)电极122至关重要地参与了冠状AKT的/ z /的产生,并且对/ z /具有高的语音选择性。
(H)在/æz/和/ iz /的产生期间电极122的平均high-gamma活动。/æz/的中值高频γ值明显高于/ iz /(p <0.05,Wilcoxon符号秩检验)。
(I)在(G)中由AKT预测的high-gamma活动的平均预测。
(J)混合效应模型显示,由于所有电极和音位的先前音位的残留协同发音效应,high-gamma系数与运动轨迹变异性之间的关系(β = 0.32,SE = 0.04,ϰ2(1)= 42.58,p = 6e-11)。/æz/(绿色)和/ iz /(蓝色)从(H)和(I)的关系显示为点。
结果
发音运动轨迹推断结果
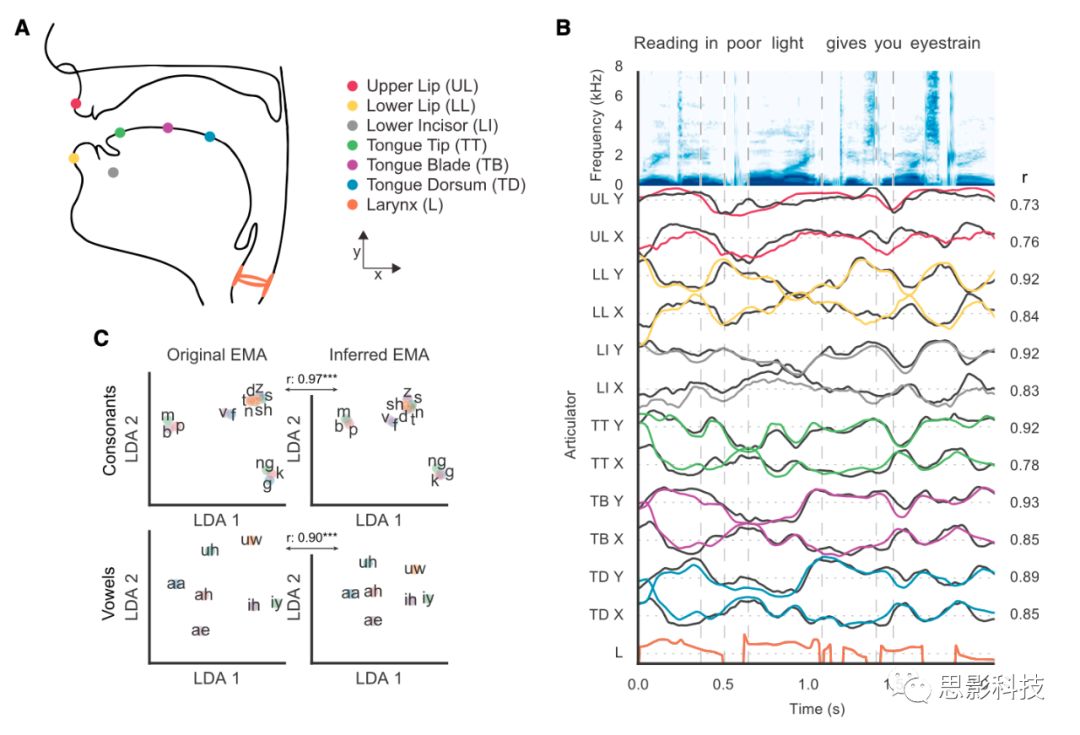
图1.推断的发音器官运动轨迹
A.EMA记录期间记录发音器官信号的传感器大概位置。中正矢状面运动以笛卡尔x和y坐标来表示。
(B)从声学和语音特征(彩色)推断出发音器中正矢状运动。每个参考传感器的轨迹以黑色显示。
(C)记录的发音器官运动(EMA)显示了投射在低维(LDA)空间上的辅音和元音。
使用留一法(leave-one-out)交叉验证,测试参与者的推断轨迹与真实基线EMA的平均相关性,r为0.68±0.11。图1B显示了在一列看不见说话者的测试表达期间,每个发音器官的推测EMA轨迹和真实基线EMA轨迹。所有推断出的发音器官运动轨迹与真实的用来参考的发音器官运动轨迹之间都具有高度相关性。图S1A显示了12个发音器官的详细性能。

图S1 声学-发音逆推
为了测试AAI方法在推断声学信号相关的发音器官运动能力,对真实和推断的EMA,研究者们训练了相同的深度递归网络进行发音器官合成,比如从发音器官运动轨迹预测声谱(编码为24维mel-cepstral系数和能量)。结果表明,使用目标参与者真实EMA或通过AAI方法推断出来的EMA预测的隐藏语音声谱没有显着差异(p = 0.4;图S1B和S1C)。这表明,推断的和实际的EMA之间的差异可能在很大程度上由于运动偏移不具有明显的声学影响。也可能包括其他因素传感器位置,噪音收集和其他说话者/记录可能与声学信号不相关的特定伪迹差异。
为了进一步验证AAI方法,研究者检查了推断的运动轨迹保留语音结构的程度。分析了由真实和推断的音位运动轨迹产生的音标聚类。对于一个参与者的真实和推断的EMA,构建了一个音位运动轨迹起点200毫秒左右的分析窗口。然后,使用线性判别分析(linear discrimant analysis, LDA)从真实EMA数据中模拟音位之间的运动轨迹差异。并将音位的真实和推断EMA数据都放置在此二维LDA空间中,以观察真实和推断EMA之间的语音结构相对差异。结果发现,在推断的和实际的运动轨迹数据之间,音位重心之间的音位聚类和相对距离在很大程度上得到了保留(图1C)(辅音相关性r = 0.97,元音相关性r = 0.97;p <0.001)。总之,这些结果表明,使用运动轨迹与声学和语言学指标,从易于记录的声学信号中获得对声道运动的高分辨率描述是可能的。
vSMC单电极上的运动轨迹编码
AKT模型可以很好地解释语音过程中vSMC区域电极检测到的神经活动(5个参与者中有108个电极;平均r = 0.25±0.08,最高为0.5,p <0.001)。研究者们在各个发音器官上观察到一致的模式,每个发音器官都显示出一条轨迹,该轨迹在返回起点之前以有向的方式从起点出发。最大运动点描述了涉及多个发音器官协同工作的特定功能性声道形状。例如,图2A中电极的AKT(图2E)显示了下切牙和舌尖在牙槽嵴处收缩时的明显协调运动。此外,舌片和舌背向前移动,以便于舌尖的移动。上唇和下唇保持张开,喉部不发声。声道结构与齿槽收缩的典型特征相对应(例如,产生/t/,/d/,/s/,/z/,等等)。在图2D中,在产生/st/、/dɪs/、和/nz/期间,可以明显看到电极对这一特殊语音类别的调谐,测量和预测的high-gamma活动都增加,所有这些都需要声道的齿槽收缩。

图2.发音器官运动轨迹的神经编码
(A)单个参与者的大脑磁共振成像(MRI)重建,其中在腹侧感觉运动皮层(vSMC)中标记了一个示例电极。
(B)在“刺激性讨论”一词的产生过程中推断出的发音动作。动作方向按颜色区分(正x和y方向,紫色;负x和y方向,绿色)。
(C)通过拟合发音器官运动来解释示例电极的high-gamma的时空滤波器。时间0表示与预测的神经活动样本对齐。
(D)将时空滤波器与发音器官动态运动进行卷积可以解释high-gamma活动。
(E)映射到声道中正矢状视点的示例电极编码滤波器权重表现出与语音相关的运动轨迹运动轨迹(AKT)。轨迹的时间过程由细到粗的线表示。喉音(通过发声进行音高调制)沿y轴为一维,x轴为时程。
使用了交叉验证嵌套回归模型,将单个发音器官运动轨迹的神经编码与AKT模型进行了比较。将一个发音器官对应一个EMA传感器。用80%的数据对模型进行训练,并对其余20%的数据进行测试。对于每个电极,使用与其对应的估计EMA传感器的x和y两个方向来拟合单个发音器官轨迹模型,并选择一个在与AKT模型比较中表现最好的发音器官模型。在对训练数据进行测试发现,AKT模型描述的多发音器官模式比单发音器官轨迹模型解释的差异更大(F(280,1820)>1.31,108个电极中96个的p<0.001,平均F =6.68,p<0.001,Wilcoxon符号秩检验;)。这意味着,单电极的活动与涉及多个发音器官的声带运动模式的关联比与单个发音器官的关联更大。
发音相关结构的差异取决于high-gamma活动是高还是低(阈值为1.5sds)(108个电极p<0.001,Bonferroni校正),这表明,除了声带生物力学特性引起的协调外,各发音器官之间的协调性也反映在神经活动的变化上。vSMC上的发音运动组织结构存在与协调运动的肢体控制类似的皮质编码,在一个电极的神经活动编码多个发音器官特定协调运动轨迹。
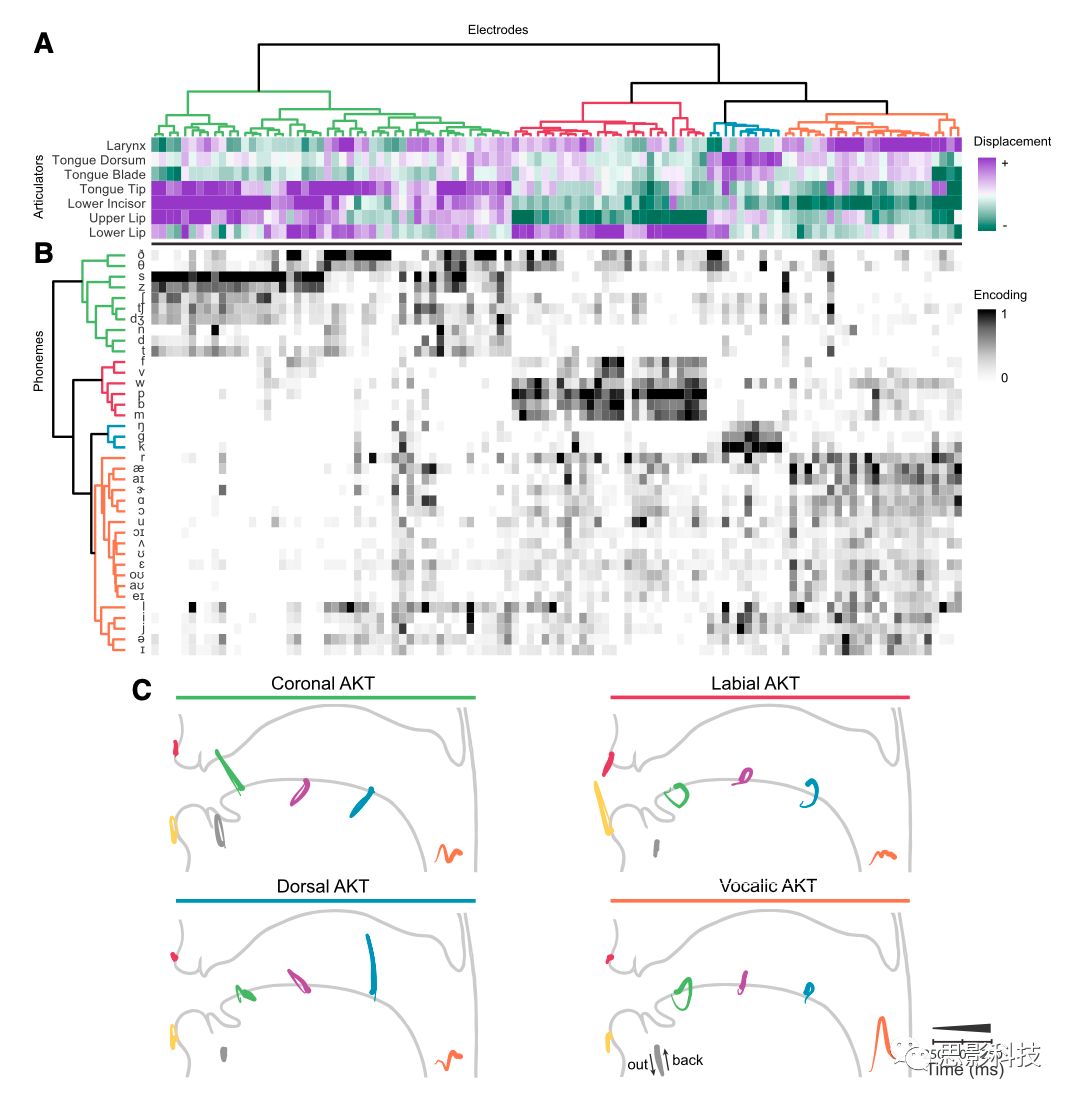
图3.发音运动轨迹聚类和语音结果
(A)5个参与者的所有108个电极的编码发音器官运动轨迹(AKT)的层次聚类。每一列代表一个电极。AKTS的动态运动被描述为沿着每个发音器官的主运动轴的最大位移点的七维向量。
(B)每个电极的音位编码模型。运动群集电极也编码四个编码的音位群集,这些音位由发音部位(齿槽、双唇、舌根后部和声道)区分。
(C)群集中所有电极的平均AKT。除声音控制外,四种截然不同的声道结构还包括冠状,唇侧和背侧收缩。
使用层次聚类法根据电极的发音运动描述来组织电极(图3A)。为了从语音学角度解释这些聚类,研究者为每个电极建立了一个音位编码模型。与AKT模型相似,电极活动被看作一个音位的加权和,其中每个音位的值要么是1,要么是0,这取决于它是否在给定的时间被发出。对于每个电极,提取每个音位的最大编码权重。每个电极的编码音位显示顺序与发音运动群电极相同(图3B)。
一个清晰的组织结构揭示了AKT之间的共同发音模式。第一级根据下颌运动的方向(下门牙上下)来组织AKTs。亚层为具有明显的协调发音模式的四个主要AKTs聚类。将每个聚类的AKT平均起来,得到每个聚类的代表性AKT(图3C)。其中三组描述了声道的收缩:冠状、唇状和舌背,广泛覆盖英语中所有辅音。另一组描述了一个元音(元音)AKT,涉及喉部活动和下颌张开运动。
研究者还发现电极对一组特定的音位表现出高度特异性,而不是分散式表征单个音位。每个AKT聚类内的电极也主要编码具有相同规范定义发音位置的音位。例如,冠状AKT聚类内的电极对/t/、/d/、/n/、/ʃ/、/s/和/z/更敏感,所有这些音位都具有相似的发音位置。然而,聚类的内部存在一定差异。例如,在冠状AKT群(图3A和3B,绿色)中,表现出相对较弱的舌尖运动(浅紫色)的电极,其语音结果较少局限于牙槽紧缩部位的音位(音位--绿色簇中的浅黑色)。
同时,对音位编码权重进行了层次聚类,以识别音位结构,以便与AKTs进行比较并帮助解释AKTs的聚类。这些结果证实研究者对vSMC语音结构的描述:由发音位置定义的语音特征占主导地位。
为了解每个AKT聚类在运动和语音上的相互区别,使用轮廓指数作为聚类强度的度量,量化了每个AKT聚类的类内相似度和聚类间相似度之间的关系。AKT类内在运动轨迹和语音描述上的聚类强度明显高于随机分布,说明聚类内具有相似的运动轨迹和语音结果(p<0.01,Wilcoxon符号秩检验)。
进一步研究每个参与者vSMC上AKTs的解剖聚类。冠状位和唇位AKTs的解剖聚类有显著性差异(p<0.01,Wilcoxon符号秩检验),背侧和元音AKTs的解剖聚类无显著性差异。为了进一步研究AKT聚类的解剖位置,将所有参与者的电极位置投射到一个标准脑上(图4)。发现AKTs存在根据运动功能和发音位置在空间上进行定位的粗大的体感组织。由于AKTs编码发音器官协调运动,本研究并没有发现单一发音器官的定位。例如,通过对发音运动的详细描述,我们发现下切牙的运动并不是局限于一个区域;相反,开闭运动是分开表现的,分别见于元音相关和冠状AKT。
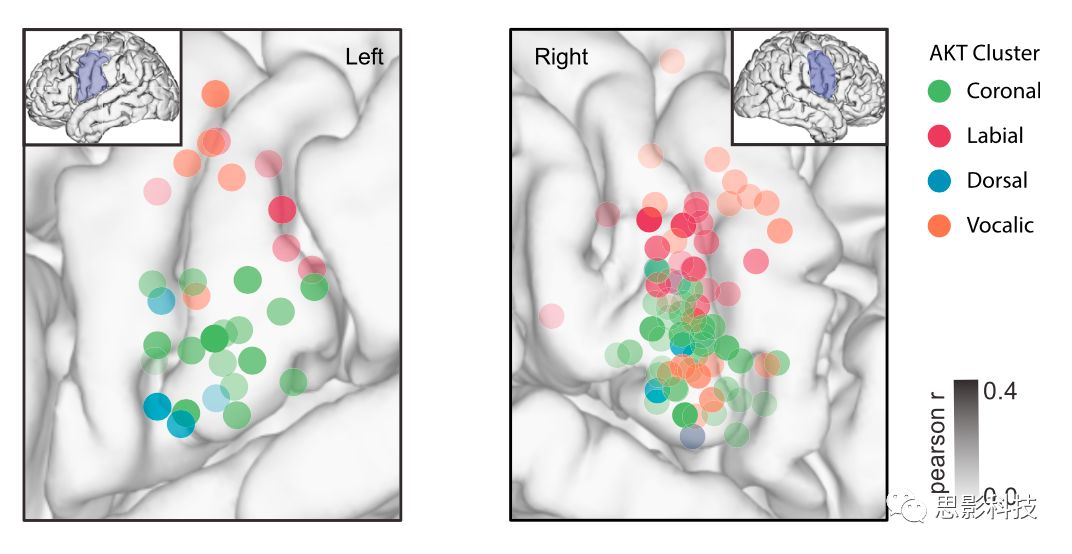
图4.声带运动的空间组织
来自五名参与者(2个左半球和3个右半球数据)的电极,不同颜色表征投射到通过MRI重建大脑的vSMC位置的不同运动轨迹。电极透明度随运动轨迹编码模型中的皮尔森相关系数而变化。
轨道阻尼振荡动力学
为了进一步研究每个AKT的轨迹动力学,我们分析了每个发音器官的相位图(速度和位移关系)。在图5A中,对于四个示例电极的AKT,分别显示了每个发音器官沿其位移主轴的轨迹的编码位置和速度,每个电极代表一个主AKT聚类。每个发音器官的运动轨迹由每个AKT的编码权重决定。所有的轨迹都向外移动,然后回到与起点相同的位置,速度相应地增加和减少,形成一个循环。即使是只做相对较小的动作的发音器官也是这样。图5B显示了来自所有108个AKT的每个发音器官的轨迹,这些轨迹再次说明了前后运动轨迹模式。给定发音器官的运动轨迹并没有显示出相同的位移程度,这表明了特定聚类内AKTs的特异性水平。位移较大的轨迹也倾向于高速运动。
虽然每个AKT都指定了随时间变化的发音器官运动,但决定各个发音器官运动方式的动态控制可能不随时间变化。在发音运动研究中,用阻尼振荡动力学描述声道姿态的时间不变特性。就像钟摆一样,运动的描述元素(即速度和位置)相互关联,而不依赖于时间。本研究发现,AKTs所描述的每个发音器官的峰值速度和位移之间存在线性关系(图5C;r分别为0.85、0.77、0.83、0.69、0.79和0.83;p<0.001),表明AKTs也表现出阻尼振荡动力学。此外,与每个发音器官相关的斜率显示了该发音器官的相对速度。下切牙和上唇移动最慢(斜率分别为0.65和0.65),舌头速度随舌体舌尖位置而变化,舌尖移动最快(斜率分别为0.66、0.78和0.99)。这些动态特征表明AKT形成一个定型化轨迹,以形成单个声道配置,即次音节语音成分,充当生成单个音节所需的多个声道配置的基础。虽然我们无法区分单个发音器官的动力学特性是集中规划的还是由声道的生物力学特性决定的,但速度-位置关系强烈地表明,AKT模型对每个发音器官的运动进行编码,该编码对应于连续语音产生的内在动力学。
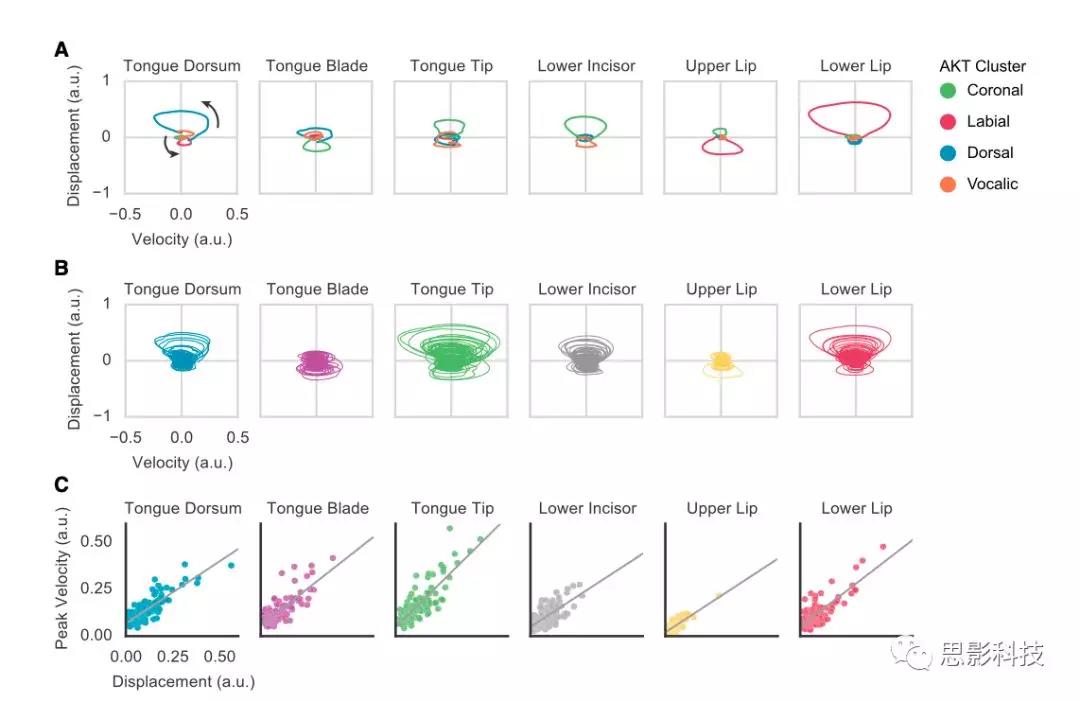
图5.运动轨迹的阻尼振荡动力学
(A)来自每个运动轨迹聚类的事例电极的编码AKT沿主运动轴的发音运动轨迹。正值表示向上运动和向前运动的组合。
(B)5位参与者的所有108条运动轨迹的发音器官运动轨迹。
(C)峰值速度与发音器官位移之间的线性关系(r分别为0.85、0.77、0.83、0.69、0.79和0.83;p <0.001)。
联合发音器官运动轨迹
在预期联合发音过程中,在当前音位的产生过程中,可以观察到即将到来的音位的运动效应。例如,思考在/z/(如“has”)和/p/(如“tap”)的发音过程中下颌张开度(下切牙向下)的差异(图6A)。/æ/发音需要下巴张开,但张开的程度由即将到来的音位来调节。由于/z/的产生需要下颌闭合,因此在发出/æz/时下颌张开的较少,以补偿/z/的要求。而/p/不需要下颌闭合,因此/æp/发音时下颌张开较多。在每一种情况下,下颌在/æ/期间打开,但根据即将到来的运动的兼容性而不同程度地打开。
为了研究预期性联合发音是否有神经上的表征,研究者们关注在联合发音程度不同的两种情况下,产生/æz/和/æp/时神经活动的变化。图6B中,电极120上AKT描述了下颌开口和喉声带结构。/æ/声音起点的时间点上,/æp/诱发电极120的high-gamma的活动高于/æz/(图6C)。为了量化这种差异,研究者以所有音位的分辨峰值点为中心,比较了50 ms期间的中位high-gamma活动,发现显著差异(p<0.05,Wilcoxon符号秩检验)。并且,在/æp/期间,AKT预测的high-gamma值同样较高于/æz/(p<0.001,Wilcoxon符号秩检验)(图6D)。在这个电极上,high-gamma活动反映了发音运动的变化,源于预期的联合发音效应。
为了确定每个音位的所有预期情境中,联合发音效应是否在所有vSMC电极都存在。使用混合效果模型来研究给定电极的high-gamma在具有不同后续音位的音位发音过程中如何变化。该模型使用交叉随机效应来控制电极与电极和音位与音位的差异,并使用从AKT预测的high-gamma的固定效应来描述每个电极的运动变异敏感性。在图6E中,每行显示了在至少25个实例中的所有后续语音环境中,给定音位和电极的high-gamma值与发音器官运动轨迹变异性之间的关系。结果发现,与特定发音运动相关的神经活动受后续发音环境的运动轨迹约束的调节(β=0.30,SE=0.04,p<0,05)。这些特定声道结构的电极活动反映了由于预期性和携带性联合发音而引起的运动变异性。
与其他编码模型的比较
为了评估AKT在vSMC中的编码情况,我们比较了(1)AKT模型相对于其他皮层区域的编码性能和(2)其他语音表型的vSMC编码模型
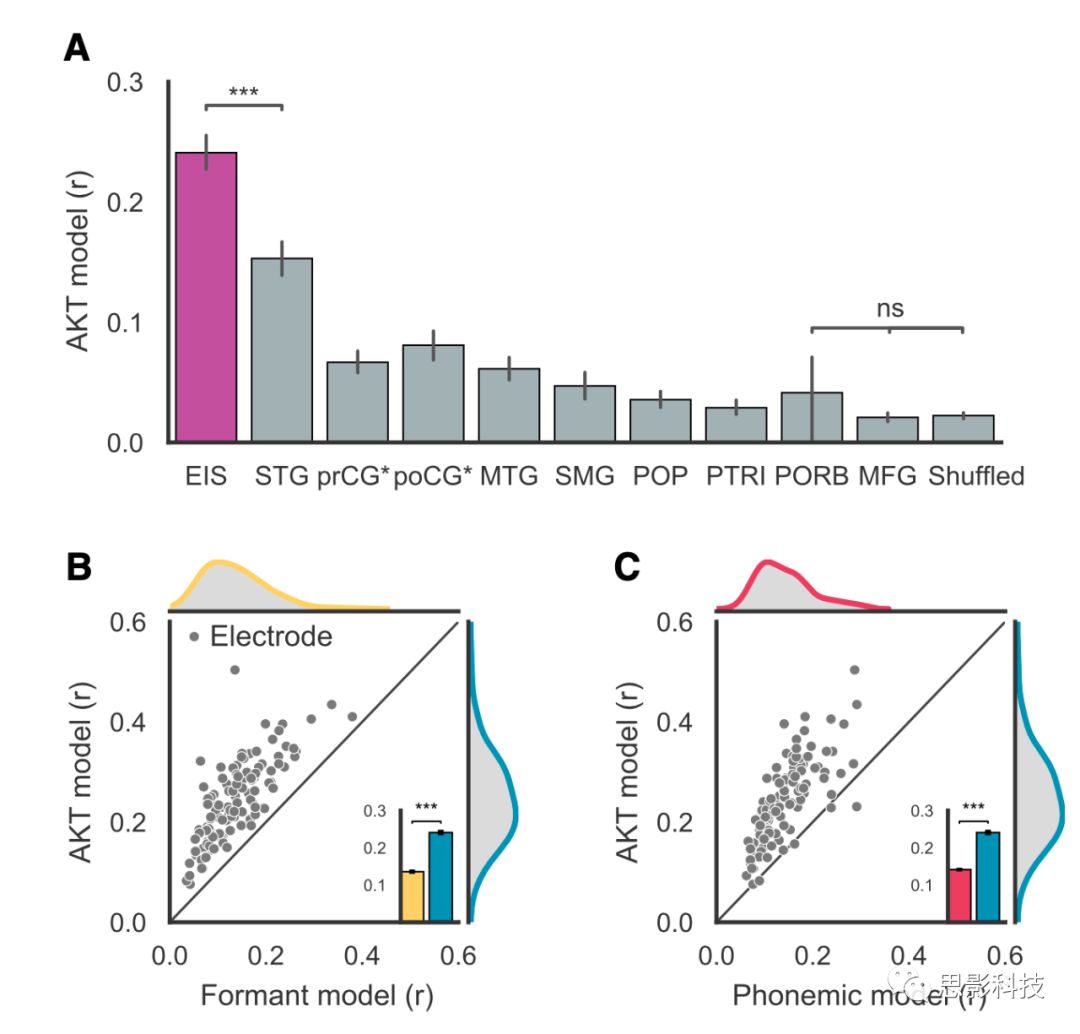
图7.神经编码模型评估
(A)在不同解剖区域中跨电极的AKT编码性能的比较。
(B)电极的AKT和共振峰编码模型的比较。使用F1,F2和F3,以与AKT模型相同的方式拟合共振峰编码模型。每个点代表一个电极的两个模型的性能。
(C)AKT和音位编码模型的比较。音位模型以与AKT模型相同的方式进行拟合,不同之处在于音位被描述为一维有效编码(one-hot vector)。
为了确定AKT对vSMC的特异性,我们比较了受试者每个皮质区域记录的AKT模型表现(Pearson's r )(图7A)。除了额叶中回(MFG)和眶部(n=4)的电极外,AKT模型显著解释了所有记录到的皮层区域高于偶然水平的差异(p<0.001,Wilcoxon秩和检验)。然而,对于本研究中所考虑的电极(EIS),即vSMC中的语音激活的电极,AKT模型对神经活动的解释明显优于其他皮质区域(p<1e-15,Wilcoxon秩和检验)。我们检查的其他皮质区域之前都被证明参与语音处理的不同方面--声学信号和语音加工(颞上回[STG]和颞中回[MTG])。因此,预计这些区域的皮质活动与产生的运动轨迹有一定的相关性。AKT模型在EIS中的较高性能表明,研究运动轨迹的神经相关关系可能主要集中在vSMC。
虽然在vSMC中AKTs编码最好,但可能有其他的语音表示方式可以更好地解释vSMC的活动。我们根据AKT模型评估了声学(这里使用前三个共振峰:F1、F2和F3)和音位的vSMC编码。每一个模型都以与AKT模型相同的方式进行了拟合,并对训练数据进行比较。我们发现,尽管AKT模型存在有局限性,发音运动的编码明显优于声学和音位编码模型(图7B和7C;p<1e-20,Wilcoxon秩和检验)。
解码发音运动
使用长-短期记忆递归神经网络(LSTM)对句子产生过程中的发音运动进行解码。图8A表面,来自解码器的预测发音运动与来自声学的预测发音运动紧密匹配。对所有发音器的运动都进行了很好的预测,涵盖了100个以上的句子,大大超过了随机结果(平均r=0.43,p<0.001)。图8B表明,可以使用自动语音识别技术对ECoG录音中的音位进行解码,进而对完整句子进行解码。本研究表明,可以直接从神经信号解码发音运动。
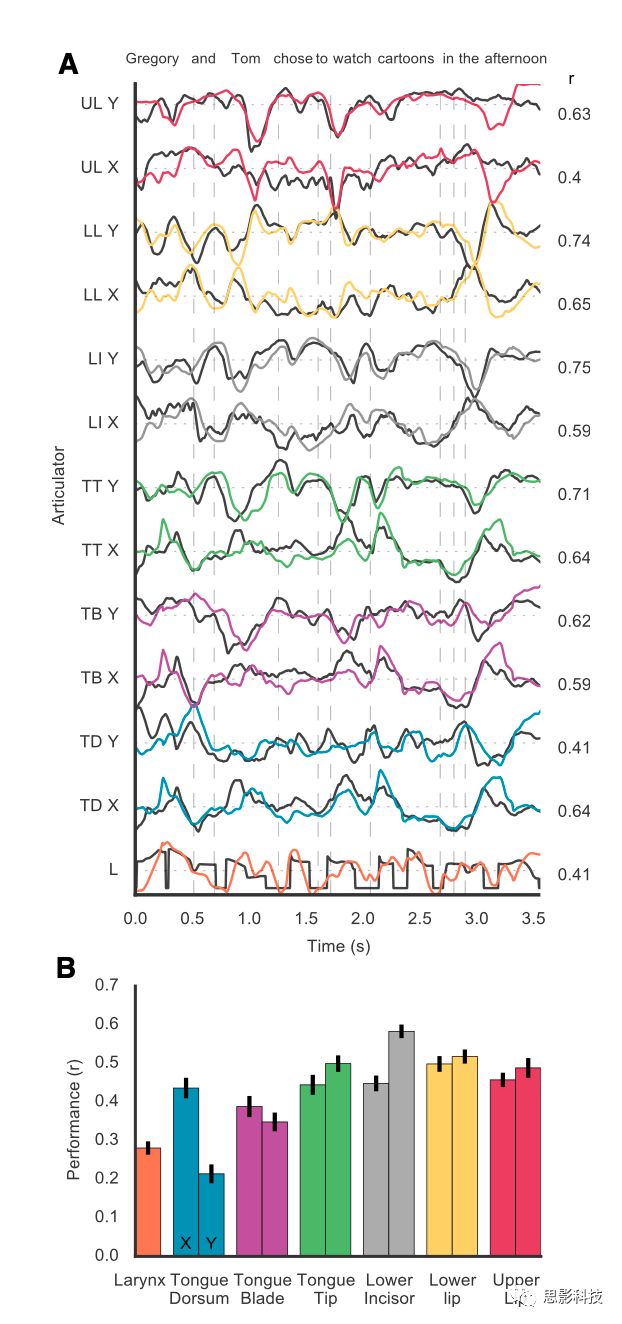
图8. vSMC活动中解码的发音器动作
(A)保留数据集中的一个例子。在产生句子的过程中,发音器官运动的原始(黑色)和预测(彩色)x和y坐标。每个发音器官轨迹的皮尔逊相关系数(r)。
(B)从训练集中得出的每个句子的100个句子的平均表现(相关性)。
总结
本研究描述了在连续语音产生的中的更丰富、更复杂的动力学的运动皮层编码。这些发现描绘了一幅关于发音的大脑皮层基础和其他可能的连续运动任务的新图景。协调的发音器官轨迹在局部进行编码并流畅地组合在一起,同时考虑到周围的运动环境,以产生我们需要传达的广泛的声道运动。
原文:Encoding of Articulatory Kinematic
Trajectories in Human Speech Sensorimotor Cortex

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
更新通知:第十届脑影像机器学习班(已确定)
磁共振脑影像结构班(预报名)
弥散磁共振成像数据处理提高班(预报名)
小动物磁共振脑影像数据处理班(预报名)
更新通知:第二十届脑电数据处理中级班(已确定)
脑电信号数据处理提高班(预报名)
眼动数据处理班(预报名)
近红外脑功能数据处理班(预报名)
数据处理业务介绍:
招聘及产品:
招聘:脑影像数据处理工程师(重庆&南京)