

概念知识是人类认知的基础。然而,它在多大程度上受到语言的影响还不清楚。对语义处理的研究表明,相同的概念以不同的方式呈现(例如,口语单词和图片或文本)会引发相似的神经模式。这表明概念表征是独立于模态的。然而,另一种可能性是,相似性反映了对常见口语表征的检索。事实上,在听口语使用者说话时,文本和口语是相互依存的,而图像是通过视觉和语言的途径来编码的。一项针对语义认知的平行研究表明,双语者在不同的语言中对相同的单词的感知是激活相似的模式的。这表明概念表征是独立于语言的。然而,这只在使用口语的双语者中测试过。如果不同的语言可能唤起不同的概念表示,那么在结构上有很大差异的语言应该是神经分离最明显的。父母使用手语的听人在手语和口语上都是双语的(就是我们常说的平衡双语者),且这两种语言以不同的方式传达(口语是听觉通道,而手语是视觉通道,他们经历的早期过程是不同的,在语言通达上可能也存在一些差异,但目前大部分研究仍旧停留在早期阶段)。
那么假如不同语言存在不同的概念表征,我们应该能从结构差异巨大的口语和手语对概念的通达上观察到某种差异。因此,来自伦敦大学学院的研究者通过比较早期听人口语-手语双语者(早期双语者指的是在语言关键期习得两种语言的人群)由听觉语言和手语语言引起的语义表征的差异,研究了通道(即听觉通道和视觉通道)和双语对概念表征的影响。
作者的研究证明了语义类别的表征在手语和口语中是共享的,但在单个口语单词和手语单词中则非如此,即作者在研究中发现:手语和口语存在重叠的神经基础能够拟合基于分类的概念表征模型(在词汇加工的重要脑区,颞上回后部),但在具体的语义特征模型和项目模型中存在口语和手语特异的神经基础。这为手语和口语共享部分概念表征提供了证据,同时还表明语言是一个“微妙”的“过滤器”,我们通过它理解世界并与世界互动。手语可能给我们提供了一种独特的对这个世界进行“观察”的视角。
研究方法
被试:
该实验得到了伦敦大学学院伦理委员会的批准,并获得了所有被试的知情同意。资料收集自18名右利手早期手语双语者,他们没有已知的神经、听力或语言学习障碍。由于偶然的发现,一名被试的数据被删除,最后留下17名被试的数据集(平均年龄= 33;范围20-52年;女= 12)。除了一个出生在澳大利亚,另一个出生在非英语国家,但在三岁时移居英国外,其他所有的被试都在英国出生和接受教育。
15名被试从聋哑父母那里学习英国手语(BSL), 2名从一位年长的聋哑兄弟姐妹那里学习。被试用自述量表(1差-7优)对自己的英国手语技能进行评价:均值= 6.3/7,SD =0.86,范围= 4-7。六名被试以前曾担任过英国手语口译员,或目前正在接受口译培训。其中一名是英国手语教师,另外三名曾担任或正在担任通信支持工作者(CSWs)。所有被试都报告说,他们以前曾以家庭成员的非正式身份担任口译。这说明,参与此次研究的所有早期口语手语双语者的手语水平都是很高的。
fMRI实验流程:
作者一共选择了三种类别的刺激物:水果、动物和交通工具,每种种类有三个概念物,水果类是:橘子、葡萄和苹果,动物类是:老鼠、狮子和猴子,交通工具是:火车、大巴和自行车(图1A)。呈现类型分为两种,一种为听觉呈现(口语的听觉通道),一种为手语视频呈现(手语的视觉通道)。
在核磁扫描仪中,被试被要求注意由手语视频呈现或者口语听觉呈现的目标物,当他们遇到来自水果、动物或交通工具类别以外的物品时,例如,目标填充物品,他们需要按下按钮(见图1B)。按按钮的左右手在被试之间是平衡的(即一半被试左手按,一半被试右手按,可以在被试间平衡利手按钮的问题)。平均97%的非类别目标项目被识别(平均正确35/36,SD = 1.45 , 最小 值 = 31日 max = 36 ) 和准确性显著大于机会概率 (mean d’score = 4.56 ),t (16) = 42.74 , p = 6.37*10 -18, 表明被试完全参与了实验。
每个被试共扫描6个run,在每个run里,这9个目标物会被使用听觉口语和视觉手语分别呈现两次(并且男性和女性打的手语或者念的口语都被会被呈现,因此每个物体会被呈现2*2*2,共八次),因此会有72个(8*9)有效刺激出现,除此以外,每个run里还会包含6个非目标刺激供被试反应(即不属于这三个类别的物体),并且有6个属于这三个类别但不是目标物体的刺激(比如pig,猪),最后还有7个空置的trail,只有白色的十字交叉注视点呈现,而没有听觉呈现或视觉呈现的刺激。因此,每个run里有91个刺激物体,使用混合设计,即block结合event方法进行呈现。
综上所述,每次试验包括91个试次(72次目标物体,6次目标填充,6次非目标填充物体,7次无效刺激,即白色的十字注视点)。试次(口语/手语)的呈现方式的顺序在成对的参与者之间是平衡的,即以手语呈现给参与者1的项目以口语呈现给参与者2,反之亦然。每个刺激都按自然持续时间呈现,然后在下一次试验开始前进行持续3秒的注视交叉。每个被试做6个run。使用the COGENT toolbox(MATLAB中的一个工具包)进行了刺激程序的设计和呈现。
作者的刺激材料是包含两个通道的,一个是手语视觉通道,一个是口语听觉通道,同时手语视频由男女两个录制者录制,听觉语音由男女两个录制者录制,因此形成了两个模态(手语模型和口语模态),6个不同状态(手语男-手语女,口语男-口语女,手语男-口语男,手语男-口语女,手语女-口语女,手语女-口语男),为了方便陈述,在后续文中我们的陈述分为模态内和模态间,其中手语男-手语女,口语男-口语女为模态内,我们统一用手语-手语和口语-口语表示。手语男-口语男,手语男-口语女,手语女-口语女,手语女-口语男这四个状态为模态间,统一使用手语-口语或者口语-手语来表示。
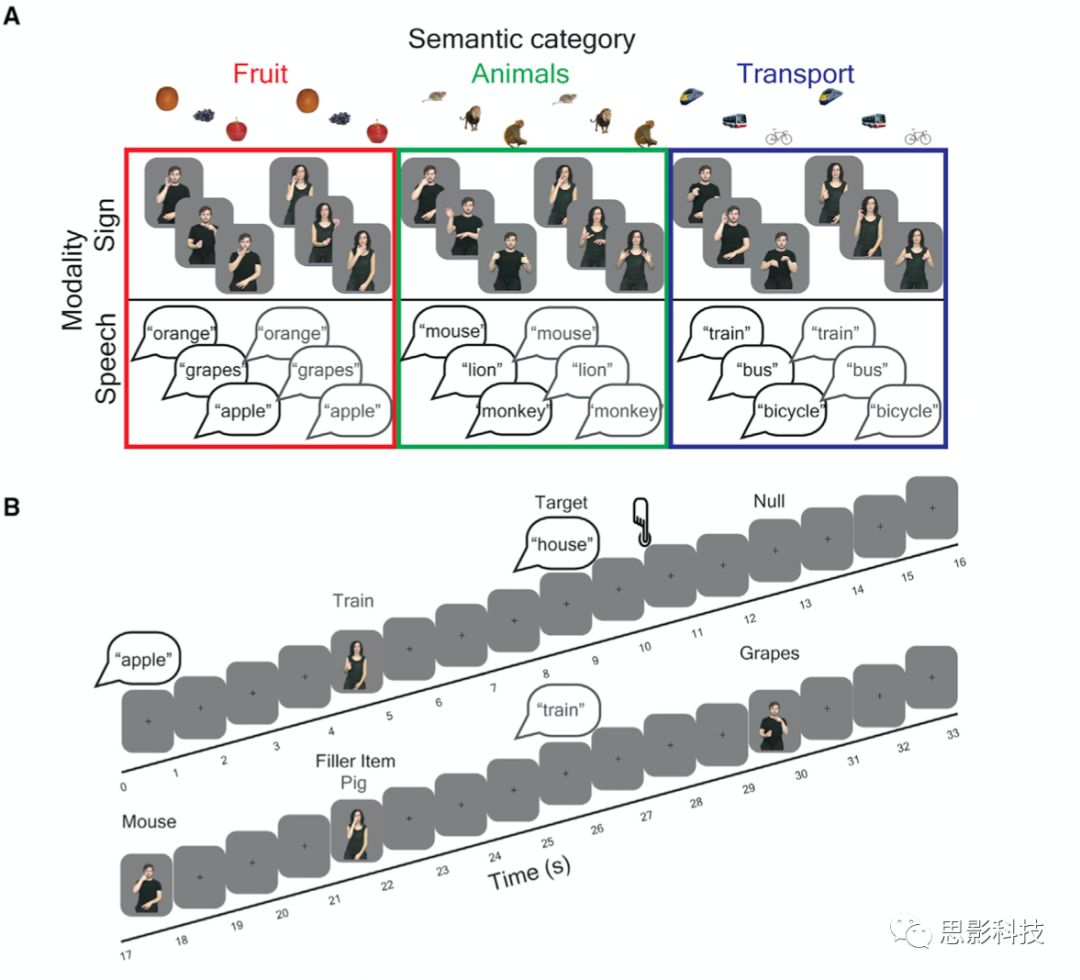
图1 实验材料展示和实验流程
在每个被试完成了fMRI扫描后,对他们看到的手语视频词汇进行了像似性评级(手语中很多词汇都很直观,比如说狗、牛等词汇都是直接模仿动物的特征来表示的,因此像似性是高于口语词汇的)。然后,这些被试参与了一个图片拖拽任务,他们被告知要根据图片之间是否是高度相关的对刚刚看过的核心词汇和填充词汇的图片进行拖拽,相关性高的拖到一起,低的拖到一起。作者发现,被试拖拽的结果和他们使用the CSLB concept property norms 筛选出的这些刺激词汇所表现出的欧式距离是高度相关的(r = 0.904, n = 36, p = 4.42 *10-14)(central of Speech Languege and Brain(CSLB),一篇关于语言中概念组织关系的文章提出的概念组织模型,感兴趣的请看The Centre for Speech, Language and the Brain (CSLB) concept property norms.这篇文章,可添加微信siyingyxf或19962074063获取),高相关说明作者筛选出的词汇间的概念关系和被试组中的真实概念表征是高度一致的。
数据采集:
数据采集使用3T西门子机器,32通道头线圈。功能磁共振数据采集参数如下:TR =2800ms, TA =2800ms, 翻转角度=90度,TE = 30ms, 矩阵大小 = 64x64, 体素大小为 3mm x 3mmx3mm, 层间间距1mm,40层).每个run采集136张全脑功能像,共采集6个run。在采集功能像后,采集了field map用于后续预处理场图校正,最后采集了T1结构像用于配准。
统计分析:
fMRI数据处理
作者使用SPM12进行数据处理,首先剔除了每个run的前6张图像,然后使用SPM中的display功能对功能像和结构像的原点进行了校正,接着进行了时间层校正,然后使用fieldmap利用SPM中的unwarp realign功能依据场图对数据进行了头动和形变校正,使用两步配准法将利用结构像将功能像配准至标准空间(MNI),数据的体素大小被resample到了2*2*2mm。最后使用6mm的高斯平滑核进行了空间平滑。
然后对每个被试的数据进行一阶建模,使用广义线性模型对每个被试接受到的刺激按照刺激的onset时间和duration时间进行contrast定义,使用一个360s的高通滤波,把6个方向的头动作为协变量进行回归,将模型和一个正则化HRF函数(血流动力函数)卷积,得到每个被试的神经成像建模结果。作者共设置了口语刺激条件、手语刺激条件、目标填充条件和非目标填充条件,还有无效刺激条件(即七个白色注视点)作为隐形的基线条件,还区分了口语录音人男和口语录音人女以及手语录制人男和手语录制人女。作者使用口语刺激>基线条件和手语刺激>基线条件的contrast结果图像作为二阶分析的对象。
RSA(表征相似性分析)
作者使用了基于MATLAB的RSA工具包,基于一阶建模得到的每个条件的Beta值通过交叉验证的方法计算不同条件的马氏距离(马氏距离是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧式距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的),并且是尺度无关的(scale-invariant),即独立于测量尺度。)这种计算方法可以使用多元噪声归一化方法降低体素间的噪声相关性,从而提升统计效力。使用不同run进行交叉验证,以提升模型表现。
Searchlight RSA 分析
使用含有65个体素的8毫米球形探照灯进行了全脑的search-light分析,这与作者在之前语言处理研究中使用的参数一致。在RSA分析中,计算每个核心刺激与其他刺激之间的交叉距离,为每个体素及其周围邻居生成一个表征性差异矩阵(RDM)。由此产生的RDM反映了手语-手语、口语-口语或口语-手语之间的距离,这些距离构成了内部和跨模态的不同模式。
在RSA分析中,使用三种不同的RSA分析方法,将口语-口语、手语-手语或口语-手语距离的平均值(例如,模内组合距离)映射到到每个小球的中心体素。模内距离仅计算来自不同语言模型(例如,不同的说话者和打手语者,即男性和女性)的项之间的距离,以排除由低级感知属性驱动的相似性。每个被试的个体全脑search-light分析映射到MNI标准空间,然后使用一个概率的灰质mask(大于等于20%)限制统计范围,然后作者使用SPM进行了模态内的单样本T检验和口语-口语VS手语-手语的配对样本T检验。作者使用了FDR的团块校正(体素p为小于0.005,团块p为0.05),卡值后的团块大小为模态内距离(k = 172个体素)、口语>手语距离(k = 146个体素)和手语>口语距离(k = 116个体素)。
感兴趣分析
作者使用了search-light二阶分析中得到的团块结果作为感兴趣区,这么做的主要原因是测试当测试样本大小受到特殊人群限制时,可以利用有可靠结构表征的ROI分析来降低由于全脑分析没有可信的结构表征而造成的虚假相关。
由于每个团块(cluster)包含多个RDM,每次search-light的结果包含在一个团块中,因此对RDMs求平均值,为每个团块和每个参与者提供一个代表性的RDM。作者使用了非参数Tau-a相关方法,该方法比皮尔逊或斯皮尔曼相关在此处更合适,因为模型为秩和关系。将得到的相关系数的值转换为皮尔逊相关的R值,然后使用Fisher Z变化转换为Z值,以便于进行后续的参数检验。
RSA模型
作者使用三种不同的方法建立了刺激材料的表征模型,首先根据CSLB准则构建了刺激材料的词汇之间的表征模型(图2C),以此来表示不同刺激之间的语义相关关系和不同模态之间的语义相关关系。其次是基于物品的模型,该模型预测每一件物品都是独一无二的,例如,一个橙子与其他所有物品的不同之处大于其自身的不同之处,而且该模型不能预测物品之间的任何其他关联(图2D)。第三种模型不测试项目到项目的相似性,但预测类别结构(图2E),称为基于类别的模型。除此以外,作者还测试了口语录音人和手语录视频者不同时是否存在模型差异。
作者使用上述模型测试了模态内(口语-口语的距离和手语-手语的距离)的差异和模态间(口语-手语的距离或手语-口语的距离)的差异。RSA模型是在以统计无偏(unbaised,这里主要的意思是说是受数据驱动的,而不是受先验假设影响的)的定义的感兴趣的区域内进行评估的。作者测试了RSA模型的模态内距离和所有口语大于手语区域的模态间距离,反之亦然。作者为了验证所使用的ROI是独立的(文中使用的是正交一词,但实质是保证根据二阶结果筛选的ROI是独立于被试以及口语录音人和手语录视频者的),使用了留一交叉验证的置换检验方法,再次确定了ROI(见补充图1)。采用多维标度法(MDS),通过计算平均RDM(表征性差异矩阵)参与度,并应用非度量MDS,将RDM的相似结构可视化。

图2 刺激材料的表征模型
注:C图模型是根据CSLB模型中的语义特征关系根据非参的Tau-a相关方法表征其关系的语义特征模型。D图是一种基于项目的模型,它预测每个项目是唯一表示的,例如,一个苹果与其他项目的差异比与它自己的差异更大,并且不能预测项目之间更广泛的语义关联。E图是一种基于分类的模型,其中项目间的相似性由语义特征模型预测,而项目内的相似性则不进行测试。这个模型中的白色方块表示被排除的比较。
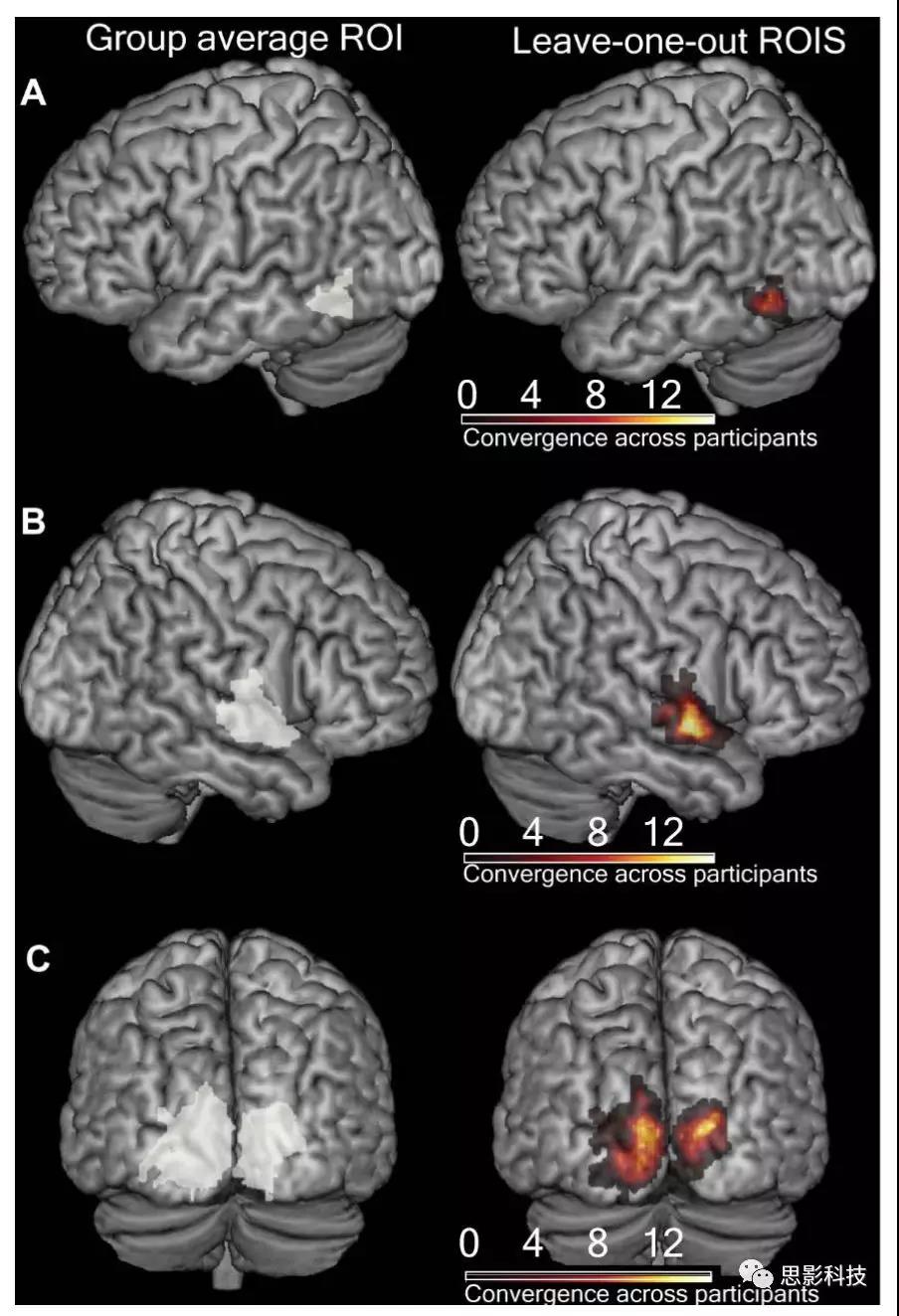
补充图1 组平均结果ROI和留一交叉验证的置换检验得到的ROI区域图
研究结果
1. 手语和口语共享的语义表征
利用search-light分析,作者首先确定了在模态项之间存在可靠正表示距离(可直接理解为正相关)的区域(例如,平均口语-口语距离和手语-手语距离)。作者只计算了来自不同语言模型(例如,不同的口语录音人和不同的手语视频录制者的)的项目(这里的项目指的是前文方法中作者所说的一阶分析的不同条件)之间的距离,以排除由低级感知属性驱动的相似性。在选定的ROI区域,作者使用以下模型测试了共享的语义表征:
(1)语义特征模型在模态内距离上的显著拟合;
(2)语义特征模型在跨模态(即模态间)距离上的显著拟合。
分析发现,能够对模态内距离可靠表征的大脑区域共有6个cluster(图3A),分别是双侧的V1-V3区域(视觉皮层)、右侧颞上回前部、左侧颞上回和颞中回、右侧颞中回近视觉皮层、右侧脑岛和左侧颞下回后中部(left pMTG/ITG)。其中三个cluster显示出语义特征模型的显著吻合(在六个cluster中将体素的alpha调整为p < 0.008之后)。这三个团块分别是右侧颞中回后部、双侧的V1-V3区域和左侧颞下回后中部。但是在后续分析中发现,只有左侧颞下回后中部是对口语模态内和手语模态内的表征相似性都敏感的区域,同时对跨模态(即模态间)距离也敏感的区域,这表明,口语和手语共同分享语义表征的区域可能就在左侧颞下回后中部。
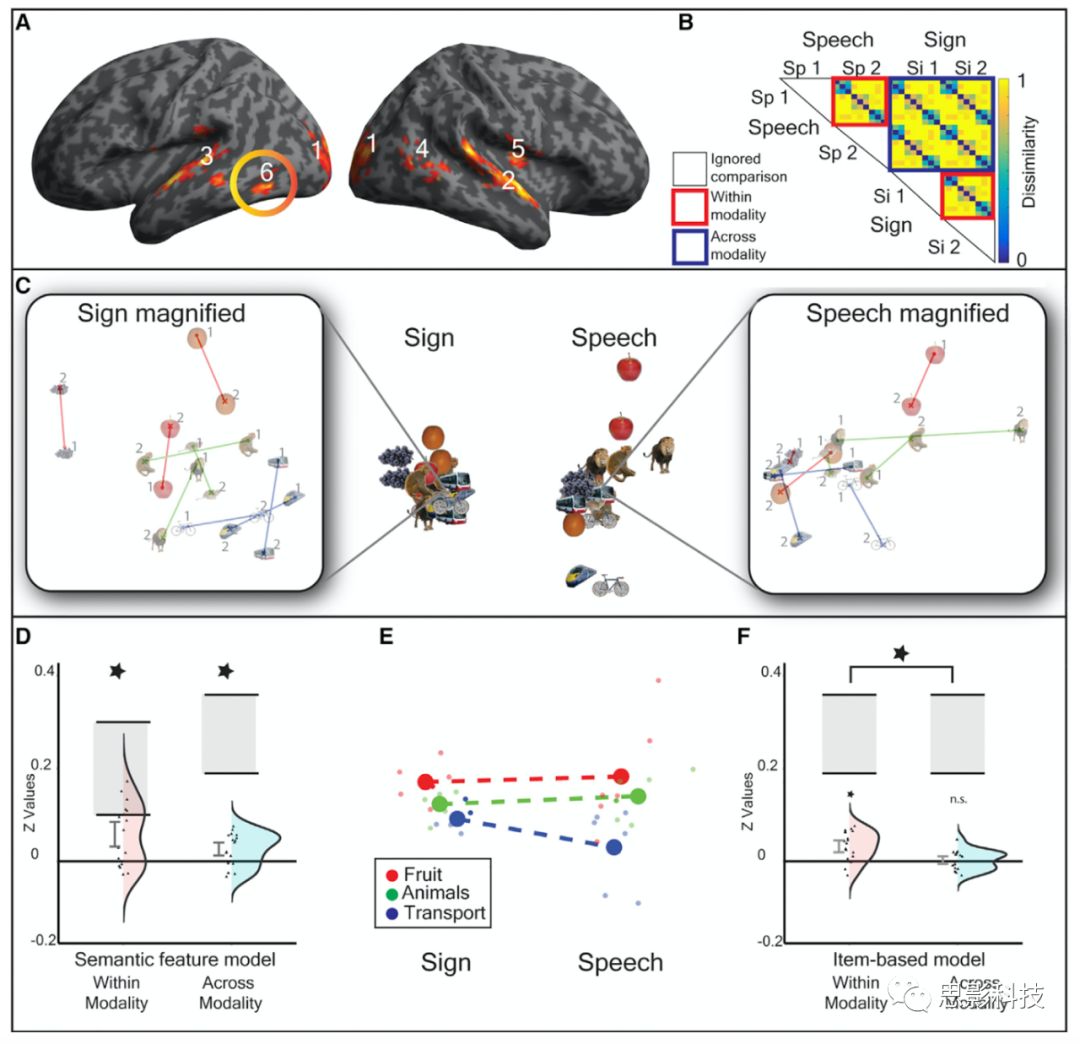
图3 手语和口语共享的语义表征
注释:A中是search-light方法根据模态内定义寻找的显著阳性区域,共有6个显著的cluster,使用团块层面的FDR校正方法,体素大小172。
B为根据语义特征模型,按照非参数的Tau-a相关方法构建的模态内和模态间的模型表征。红框说明的模态内的相似性,Sp1和Sp2指的男性录音人和女性录音人,Si1和Si2指的是男性手语录制者和女性手语录制者,口语-口语和手语-手语是模态内的。蓝色的框表示的是跨模态的,指的是口语-手语或者手语-口语的,白色的框是自己和自己,所以是被忽略的。
C-F是对B图中cluster6的具体分析结果,因为这个区域是在RSA分析中发现可以和模态内表征及模态间表征模型能够拟合的区域,这个cluster位于左侧颞下回后中部(-48,-62,-6)。其中,C图是对这一区域根据MDS方法图示化的模态内的距离表征,左边为手语模态内,右边为口语模态内,放大的图中的1和2代表的各自模态内的不同的录制者(即一个男的一个女的)。
D图是语义特征模型在模态内和模态间的拟合都显著。小提琴图显示了z转换值的分布和单独的数据点,包括90%的置信区间和噪声上限(灰色矩形)。
E图是MDS方法图示化的根据类别表征的不同对象在模态内和模态间的关系。
F图是根据基于物品的模型在这一个团块内的模态内的拟合情况和模态间的拟合情况,模态内拟合显著,模态间拟合不显著。
模态特异的表征
在上一个分析中,作者分析了手语模态和口语模态共享语义表征的区域,接着作者分析了对口语模态或手语模态具有特异表征的区域。首先来看对口语表征特异性的分析。
有四个团块被发现是口语相互间的表征差异大于手语表征的,分别是右侧颞上回前部延伸到颞极、左侧颞上回、右侧颞上沟后部和右侧壳核和脑岛区域(图4A)。进一步的分析发现,只有图4A中的第一个cluster,也就是右侧颞上回前部延申到颞极的区域能够显著的拟合语义特征模型和基于物体的项目模型。在图4中B是语义特征模型的表征,D是基于物体的项目模型的表征,C是基于类别的模型的表征。E图是对男声和女生两种不同声音刺激的表征,发现音色的差异在这一区域是显著的(H中可以看出)。
作者在右前STG中发现对口语形式的识别是出乎意料的,因为一般认为语言的处理主要在左侧,尤其是听觉语音中对语义概念的解码。作者认为,这可能反映了早期双语者在语言处理过程中右半球的更大的参与,或者,考虑到右半球在听人手语母语者手语处理过程中的更大的重要性,这一区域对口语中概念表征的敏感可能反映了一种手语对早期手语口语双语者更具体的影响。
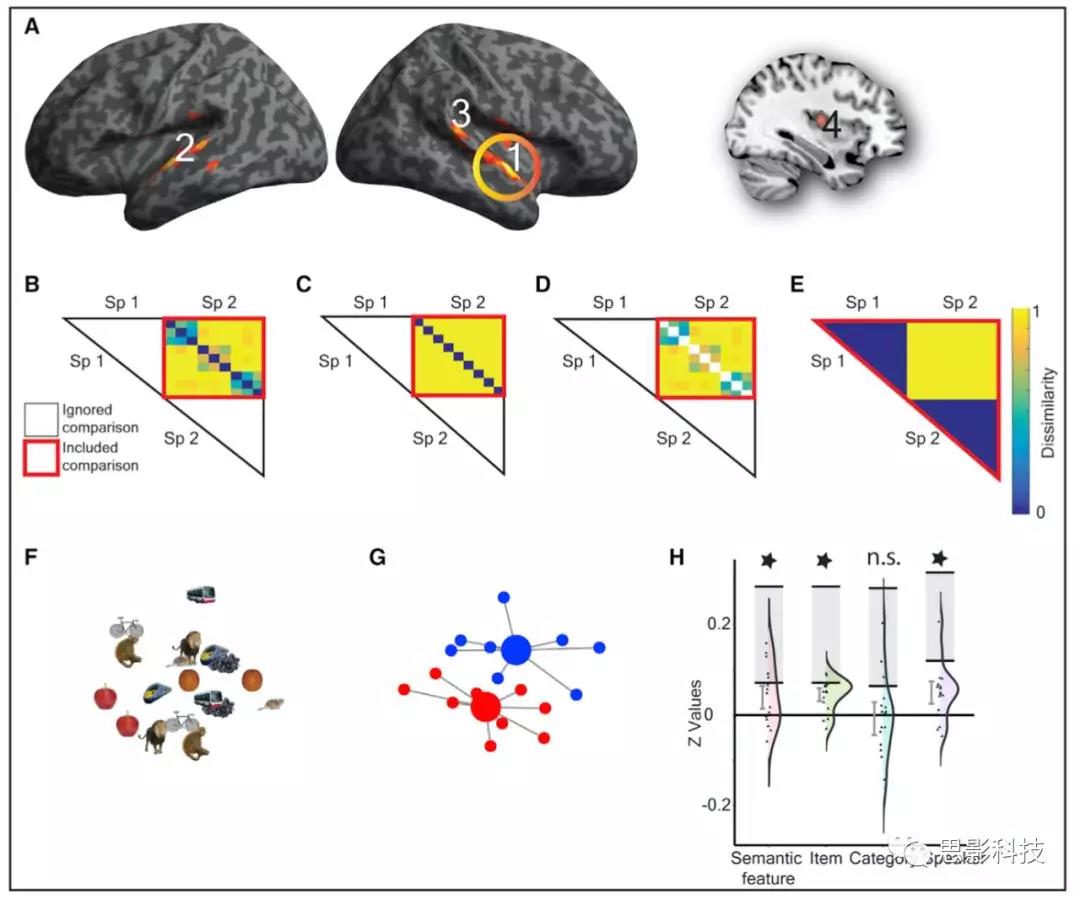
图4 口语表征特异性分析结果
接着来看手语表征特异性分析
作者的初步分析(search-light实现)发现,相对于口语的表征而言共有五个团块的手语表征模式相互间差异更大,分别是左侧V1-V3区域、右侧V1-V3区域、左侧舌回区域近V5区域、左侧枕上回和顶上回区域以及左侧舌回近小脑区域(见图5A)。这四个区域中没有一个区域能够拟合基于类别的表征模型(图5D),仅有图5A的1号cluster也就是左侧V1-V3能够拟合基于语义特征的表征模型(图5B)和基于物体驱动的项目表征模型(图5C)。并且对男、女的录制人敏感(图5E)。这可能表明,这一区域对于视觉通道的手语刺激是敏感性的,其形式化的差异在早期调节了手语的输入。
图5F同样显示了在这个区域的通过MDS方法图示化的男录制人和女录制人的不同对象之间的表征距离。图5H表明了各检验的显著性。

图5 手语表征特异性分析
总结:
本文使用功能磁共振成像(fMRI)比较了在早期口语手语的双语者中,英国英语口语和英国手语所表达的相同概念所引发的神经模式的相似性。概念表征只是部分共享的,手语和口语表征存在特异的概念表征基础,在视觉区域和听觉区域存在特异的不同模态的敏感脑区。
这可能表明,我们用来交流的语言就像一个微妙的过滤器,我们通过它来理解这个世界,并与之互动。这一发现是出乎意料的。先前的脑成像研究显示,手语和语言的激活存在显著的单变量重叠,这使得包括研究者在内的研究人员提出,手语和口语背后的神经过程存在广泛的相似性。但是当前的研究结果表明,有必要重新思考这一假设,并强调手语在更广泛的语言处理和语义表达方面所能提供的独特视角。
原文:Sign and Speech Share Partially Overlapping Conceptual Representations

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
更新通知:第十届脑影像机器学习班(已确定)
磁共振脑影像结构班(预报名)
弥散磁共振成像数据处理提高班(预报名)
小动物磁共振脑影像数据处理班(预报名)
更新通知:第二十届脑电数据处理中级班(已确定)
脑电信号数据处理提高班(预报名)
眼动数据处理班(预报名)
近红外脑功能数据处理班(预报名)
数据处理业务介绍:
招聘及产品:
招聘:脑影像数据处理工程师(重庆&南京)