

精神病学的不确定性限制了在表征和治疗精神健康疾病方面的进展。其中一个重要的问题是:“异质性问题”,即不同的因果机制可能与同一种疾病有关,并且一个人可能会产生多种感兴趣的结果。这篇文章集中讨论了如何解决在精神病学研究中出现的异质性问题,为研究人员检查人类认知和心理健康提供了考虑因素、概念和方法。
作者强调的一个重点在“维数诅咒”问题,本文强调了纯粹维数方法的困难,并且在计算上,考虑采用有监督和无监督的统计方法来识别总体中的假定亚型。但是,这里强调,亚型识别应与特定的结果或问题相关联。本文以新颖的混合方法得出结论,该方法可以识别与结果相关的亚型,并可能有助于提高治疗工具的诊断精确性。本文发表在Trends in Cognitive Sciences杂志。
心理健康问题的潜在机制多数未知
一百多年来,精神科医生、心理学家和心理健康提供者通过努力逐步发展并完善了精神病学,其中包括对世界卫生组织国际疾病分类(ICD)和美国精神病学协会精神疾病诊断和统计手册(DSM)(box 1 and 2)的一系列修订。但是,这些方法的有效性仍旧依赖于使用表型数据来识别临床决策所必需的假定临床类型。这严重依赖医务从业者的职业水平和主观判断。
面对大量的疾病患者,我们需要更有效的工具来发现病理生理学的需求,目前,已经有许多研究者开始寻求替代方案。
目前的DSM和ICD精神病学的主要关注点包括过度和不足的特异性,分别表现为:
(i)疾病之间存在严重的重叠,并且具有共同的生物学特征,表明缺乏明确的自然界线来定义疾病是否存在还是不存在(许多是连续存在);
(ii)每个条件下的实质异质性。异质性包括以下问题:不同的机制可能会推动对个体的不同子集(此处称为亚型)的诊断(box 1)。
因此,一种亚型的生物学指标可能有所不同,而另一种亚型的生物学指标却没有差异。对于给定的诊断,某些生物学标记可能仅在个体的一个子集内发现。虽然这些问题是众所周知的,但解决方案尚不明确。因此,针对以上问题,本文提供了有关此异质性问题的进一步解决方案(Box 1),并为研究人员检查人群的典型和非典型认知与心理健康提供了考虑因素、概念和方法。
Box 1 定义异质性问题
在目前的工作中,本文认为异质性问题是一个被广泛承认的和多方面的问题,一些专家认为它限制了心理健康和认知神经科学的研究。最终,需要一个适当的概念模型,它包含人类研究结果的自然异质性。为此目的,必须坚持两个原则。第一个原则是理解任何人类精神健康综合征或结果,从认知功能到临床疾病,不一定是由单一机制引起的;相反,因为这些条件是多重决定的,它们可以由不同的输入组合引起。重要的是,这种可能性不仅存在于临床人群中,也存在于典型人群中(例如,正常性状变异的研究)。虽然这一认识并不新鲜,但处理方法,特别是数学模型,这个问题仍在继续优化和发展,正如在本文中所讨论的。
第二个原则指的是一种理解,即与单个个体相关的结果是巨大的,并取决于兴趣领域(例如,情绪、教育和健康),因为这改变了该个体相关的异质性参数。换句话说,当我们试图识别与特定疾病或症状相关的机制,或特征模式时,有效的模式取决于所关注的问题的具体情况。例如,区分患有和不患有ADHD的一组人的大脑测量结果可能不同于那些预测随时间推移将持续存在ADHD症状的人的大脑测量结果,相对于以后几年的回归症状。
当然,这个特定问题与任何假定的病理生理特征有关,而不仅仅是脑成像。换句话说,当试图了解和解析典型和非典型人群的多个特征(大脑,环境,人口统计学等)之间的差异时,此类数据可能会出现许多不同的亚群。将它们分组的每种方式可能对不同的目的均有效。因此,没有一个有效的答案。给定的解决方案取决于:
(i)用于生成模型的特征;(ii)建模策略的偏见;(iii)即将达到的目标或问题。正如我们在这篇综述中所论证的那样,对亚型人群的有监督和无监督的方法在该领域中是有益的并且正在增长。但是,我们要强调的一个弱点是,这些方法的大多数应用都不能识别与(iii)感兴趣的问题有关的亚型。结果,这样的应用将成为异质性问题的这一方面的牺牲品——识别出的亚型可能与问题或感兴趣的结果无关。通过将亚型识别与感兴趣的问题联系起来,结合有监督和无监督特征的混合方法可能有助于建模或捕获异质问题的这一方面。
异质性问题挑战心理健康研究
尽管为精神疾病创建准确的疾病概念问题已经持续了数百年(Box 2),但是寻找对于这些精神疾病具有特异性的环境、心理健康状况(以及许多复杂的认知行为)、行为、生理和生物学指标的研究却难以获得令人振奋的突破。在DSM时代,模态研究通常涉及将一组具有由核心症状定义的疾病(例如,通过DSM标准)的被试与一组没有该疾病的对照组被试进行比较。基于环境影响、心理测量学、神经影像学或基因组学的统计组差异随后被用来告知疾病的(假定的)病理生理学或病因学模型。
例如,最近提出了在扣带回皮层(PCC)和眶外侧额叶皮层(OFC)之间增加功能连接是抑郁症及其缓解的机制。的确,从功能连接磁共振成像(fcMRI)观察到的未分离的大脑状态也被认为是自闭症谱系障碍(Autism spectrum disorder,ASD:普遍的发育障碍,其特征是社会交往改变和兴趣/重复行为受到限制)的病因。在注意力缺陷多动障碍(Attention deficit hyperactive disorder,ADHD:以注意力不集中和/或多动症状为特征的普遍发育障碍)中,已经提出全脑不成熟的功能性连接可能是该疾病的基础。其他人则提出了注意力缺陷多动症的认知和神经“轨迹”,其中任务控制系统的不同成熟度将注意力缺陷多动症的儿童与通常发育的儿童区分开来。同样,多基因风险评分和大规模基因组研究已被用于阐明各种精神疾病的病因。
但是,此类研究仍旧难以真正解释这些精神疾病区别于其他拥有共变状态的疾病的特征是什么。并且,此类研究往往依赖于对同类病人的同质性假设,而对同质性的这种期望导致了两个可能不正确的假设:
(i)给定疾病人群代表一个具有同质性的患者人群
(ii)典型的人群代表了很大程度上是同质性的,并且很可能是更具适应性或最优的状态。
Box 2 现代精神病学的出现
精神障碍的分类可以追溯到古代。在西方,他们追溯了启蒙运动和现代气质、人格心理学和医学的发展。启发式的观点假定自然界中的自然种类,并试图将它们映射到其隐藏的、基于过程的结构来。在启蒙运动中占优势的观点避开了病因学的思索,而是强调可以聚在一起的可观察特征。贯穿这些观点是本体论的问题。在现代,基于这些对立的哲学方法,对立的精神病学分类在19世纪和20世纪被正式确立,并因第二次世界大战的需要而标准化。20世纪中叶,K统计量被重新发现并在临床心理学中大量应用,伴随而来的是,1960年代临床医生之间对诊断的共识不佳,这使得DSM-II的病因学幻想破灭。对描述性疾病学的强调,在很大程度上受到罗宾斯和Guze的影响,并且再次在DSM-III(1980)、DSM-IIIR(1987)和DSM-IV(1994)中优先并指导了症状表的创建。DSM-5(2013)并没有从根本上改变这一方法(尽管在DSM-IV和DSM-5中努力承认精神病理学中的交叉维度)。因此,可以说它也失败了,并且继续失败了。在精神病理的经验描述的进展,可以追溯到半个多世纪,但一个统一的诊断方法仍然缺乏。然而,从根本上讲,正如几个世纪以来所指出的那样,从病因学的角度来看,纯粹是描述性的疾病学不可避免地会混淆多个实体,而目前的病因学方法在精神病学中仍必须是推测性的。目前,尽管取得了一些进展,但对DSM疾病诊断与统计手册的过度具体化的担忧仍然突出,并且有证据表明,疾病诊断与统计手册无论其实际优势如何,都不能反映生物系统。所有这些都导致了至少出于发现病理生理学的目的而提出的替代方案的愿望,正如本文所证明的,尽管数学和经验方法并不能使我们摆脱哲学上的选择和假设,但仍希望从数学和经验方法中获得一些效果。
有一些证据表明主要的精神病存在异质性
尽管最近在DSM-5中提出了对给定精神病学表现的多种输入,并且在文献中提出了更长的时间,但是越来越多的证据和最新证据表明,尽管通过多种输入来评估精神疾病是有用的,但仍旧难以解决变异性问题。仅举一些例子,遗传和全基因组关联研究发现ASD存在严重的异质性;常见的变异有助于遗传,而罕见的变异则导致了症状类型的变异和严重性的差异。简而言之,ASD症状在特定个体中的表现可能来自于根本不同的机制。这种异质性与使用结构磁共振成像(sMRI)和功能磁共振成像(fMRI)数据的ASD预测模型的结果一致。
另一个例子是,在不同站点收集的独立数据集上,对个体未来重度抑郁发作或治疗结果的预测模型表现不佳。使用外部数据来减少有重度抑郁症(MDD)病史的个体之间的样本异质性,可能会提高此类预测模型的泛化性能。一项研究利用外部获得的fMRI数据改进了对抑郁症治疗结果的预测。首先,通过使用不同的fMRI数据识别计算上不同的MDD子组,然后通过将子组作为独立的总体来改进模型性能。其次,通过不同的fMRI连接模式来识别不同的MDD亚群,然后通过把这些亚群视作独立人群来提高模型性能。在这种情况下,胼胝体下扣带皮层与左脑岛、中脑背侧和左腹内侧前额叶皮层之间的连接性在两种假定的亚型之间呈现明显的分离。一种亚型表现出高度的连通性,最好的治疗方法是认知行为疗法,而不是药物治疗;另一种亚型表现出较低的连通性,最好的治疗方法是药物,而不是认知行为疗法。同样,基因组、行为和功能磁共振成像数据有望与更新的计算方法一起用于识别和/或帮助验证多动症亚群。此外,这种识别出的子类型可能无法直接推广到跨不同站点的独立数据集,因此需要进行额外的独立验证(Box 3)。
因此,从以往的研究证据看,主要的精神疾病存在明显的异质性问题,并且表现在多种方法获得的数据上。
Box 3 预测模型的解释性和有效性
有监督的、无监督的和混合的建模方法组成了强大的方法来识别可以更好地描述典型和非典型人群的亚型。这些模型依赖于评估性能的方法,称为交叉验证(cross validation, CV),以及选择用于构建模型的度量方法的方法,称为特征选择(feature selection, FS)。在CV中,参与数据集被均匀地划分为多个部分。在每次迭代中,每个部分都作为一个测试数据集分离出去,其余的部分形成训练数据集。通过将参与者划分为训练和测试数据集,测试与训练过程保持独立,从而防止过度拟合。但是,必须确定执行交叉验证的折数(folds)。一种常用的方法,称为留一交叉验证(LOOCV),是使每个被试成为一折分离出数据集。
尽管在神经成像中是常规的,但LOOCV与使用五折或十折的模型相比,无法很好地评估模型性能。即使建模方法采用了良好的交叉验证策略,如果采用了不适当的FS(特征选择 )策略,也可能会发生过拟合。FS涉及选择要在给定模型中使用的特征子集,这有助于克服维数的诅咒。最优FS策略从训练数据而不是测试数据中确定合适的特征子集。使用从重叠的训练和测试数据集中选择的特征的模型通常显示出过高的性能,而不能推广到独立的数据集上。最后,来自模型的推论受到样本数量的限制。小样本将在模型性能中产生更大的可变性,但是表现良好的模型更有可能被忽略。通常,随着样本量增加,所给定疾病的已发布的预测模型的性能会下降。如果CV(交叉验证)和FS(特征选择)没有采用好的标准和实践,则模型在新情况下的性能可能会很差。
然而,即使采用了最佳的标准和实践,从模型中确定的亚型也需要独立的验证。当模型表现不佳时,独立的数据集可帮助验证模型并提高性能。次要措施有助于验证已识别的亚型,并完善关于临床诊断或生物学相关性的推论。可以组合使用这些技术来更好地验证假定的亚型。例如,假设ASD亚型是使用功能随机森林(FRF)从成像数据样本中识别出来的。为了验证此类亚型与ASD受影响的行为有关,可以从此类行为数据构建亚群的预测模型。然后可以将此行为预测模型应用于一组独立的ASD病例,以测试亚型的普遍性。
有证据表明典型人群是异质的
虽然精神疾病症候群的异质性是公认的(至少在理论上),但在精神病学文献中却很少考虑到对照组的异质性(尽管这在其他领域如人格和社会心理学中是众所周知的)。因此,异质性问题几乎肯定也适用于典型人群。当比较发育正常的个体和被诊断出患有某种特定疾病的个体时,研究人员往往不得不含蓄地假设——典型人群处于一种同质的最优状态。然而,典型样本在认知能力和智力、情绪应对风格、基因组成和社会生态位等方面存在巨大差异,更不用说心理健康状况。例如,具有相似的整体智商(IQ)的个体可能处于不同的认知亚群中,其中一个亚群在语言理解上的得分高于另一个亚群。然而,与第三组相比,两者都与颞叶形态的差异有关,并且没有适应不良的迹象。在工作记忆的情况下,很明显,尽管采用了不同的策略(可能与不同的神经通路有关),但个体仍可以优化这种经过充分研究的认知功能。在执行功能测量中发现的典型人群的这种变异可能是理解心理健康状况(如多动症)的至关重要的背景。换句话说,这些典型的变异可能构成或呈现出不同的精神病学状况的背景——也就是说,精神病学状况可能嵌套在典型的异质性中。
这种与典型和非典型人群相关的隐含设计假设可能有助于理解心理病理学研究中经常出现的小效应。在临床上,这些相同的假设可以解释为什么治疗研究可能显示出微弱的效果或有限的重现性。简而言之,在患病组和比较组之间的同质性的假设可能限制了在确定病因、生物标记和有效治疗选择方面的发现。有几个挑战使得在实践中很难克服这些假设,即使它们在理论上被认为是不正确的。
维数诅咒与异质性问题
几十年来,一种克服精神病学异质性问题的方法强调了疾病学的维度逻辑,即多维连续分布的极端尾部(即异常值)可能表明个体将从治疗中受益。在这种情况下,维度将测量连续或分类变量的任何组合,这些变量可能包括行为(在一个或多个任务中的表现)、生物(一个或多个遗传标记或大脑特征)、环境或其他特征。然而,虽然这种方法可能反映了与精神病学相关的自然特征变异,但它在实际临床应用方面有很大的局限性。要在这样的场景中检测离群值,必须首先在多维空间中生成这一群体的高维表征。虽然可以获得足够的样本量来度量单个维度,但是在不考虑亚型的情况下跨多个维度表征一个群体是一个挑战。原因与维度诅咒有关(注:维数诅咒也被称为维数灾难,是一个最早由理查德·贝尔曼(Richard E. Bellman)在考虑优化问题时首次提出来的术语,用来描述当(数学)空间维度增加时,分析和组织高维空间(通常有成百上千维),因体积指数增加而遇到各种问题场景)。
如果要测量人口中某一维度的连续性,例如身高(图1A),必须决定对该分布采用一些基本要求。假设高度的真实分布是高斯分布;分布呈钟形,均值为100,标准差为5。在这个简单的例子中,要正确地识别一个离群值,必须首先生成一个分布的估计值。这个估计基于你的研究样本。随着您的研究中采样的案例数量从10个增加到300个(图1A,最上面一行),对分布的估计更好地反映了真实的分布(蓝色箭头)。毫不奇怪,你的样本越能反映真实的分布,你就越能识别出真实的总体异常值。在本例中,在50个案例中,可以正确地检测到>70%的真实人群异常值(图1B,左面板)。然而,如果想要在两个维度上识别离群值,比如身高和体重,两个维度的交集产生的搜索空间比一维的例子更大(图1A,底部一行)。在这里,对50个参与者进行抽样不足以显示真实分布(红色箭头)(图1A;“ 50个样本”,底部面板),并且对于能够准确识别异常值的样本而言,效果不佳。话虽如此,对300个病例进行抽样可以更好地代表人群(蓝色箭头)(图1A;“ 300个样本”,底部)。在这种情况下,虽然正确的离群值检测仍然是高度可变的,但是平均70%的空间仍然可以检测到真实的种群离群值(图1B,中间面板)。然而,在三维空间中,比如身高、体重和教育水平,搜索空间呈指数级增长。即使有大量的被试,也不能正确地建模真实分布。事实上,即使抽样了1000个人,对人群中异常值的正确识别也低于二维情况(图1B,右面板)。
当应用示例并尝试准确检测异常值时(图1B),模型性能会随着维数的增加而呈指数下降。为了随着维数空间的增加而变得更加准确,需要成倍地增加更多数据以准确检测异常值。当然,大脑可能有比这更多的信号或维度。诚然,其他的心理学模型只能满足于少数几个维度,但困难依然存在。
相反,如果假设群体由具有不同底层分布的多个亚群组成,那么我们的目的不是检测离群值,而是区分亚群之间的边界。为了划定这样的边界,需要定义边界,通过测量亚群之间的重叠空间来分隔它们。因此,合并亚型会限制需要度量的空间,从而减少了识别边界所需的案例数。在这里,相关的维度可以帮助识别和细化亚群。因为亚型可能只与几个相关的维度相关联,所以它使我们能够减少维度以及描述和分析所需的样本量。
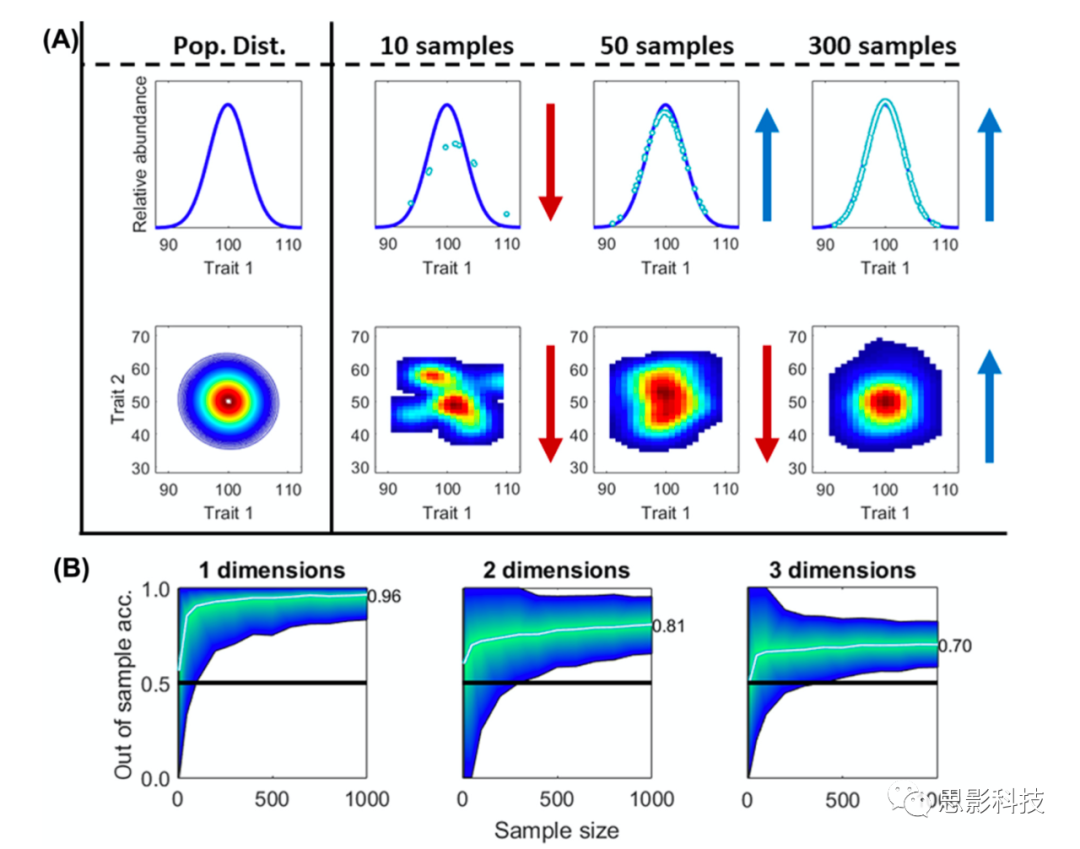
图1 数据模拟表现了维数的诅咒。使用纯粹的维度分析框架(不考虑子类型)来检查只考虑一个连续分布的精神健康障碍或认知行为是具有挑战性的。
(A)针对高斯分布中的相关性状对数据进行了模拟(Pop. Dist.)。性状1的度量(x轴)和频率(y轴)之间的函数关系在第一行中绘制出来。性状1(x轴)和性状2(y轴)之间的2维密度分布在第二行绘制出来。最左边的面板显示了这些性状的人群的统计分布。然后从分布中随机抽取样本。如图所示,随着维度数量从一个(上)增加到两个(下),需要接近分布的受试者数量从10个增加到300个。好的(蓝色箭头)和差的(红色箭头)人群分布表征。
(B)对1个维度(左)、2个维度(中)、3个维度(右)进行离群值检测。数据采用多元正态分布(均值为0,标准差为1)进行抽样,以满足所使用的方法。从一个大样本(n = 10,000)确定了真实异常值的阈值。为了测试离群值的准确性,较小的样本(n = 10-1000)被伪随机生成1000次,并使用已知阈值识别出真正的离群值。正确识别的异常值的计算方法是:识别的真实异常值的百分比除以真实异常值的总数。如图所示,随着维数的增加,识别真实异常值的准确性降低。可以在(http://github.com/dcan-labs)中找到重现这些图的代码。缩写:acc., 准确率;Pop. Dist.,人口分布。
几种可以识别研究中亚型的方法
虽然在20世纪后期,因子分析大量应用于异质性问题,但21世纪在计算科学和数学方面的最新发展,使模型的实现可能足够复杂,可以更好地处理前面提到的关于亚型的情况。这些方法可以经典地分为有监督的和无监督的。
监督方法
有监督的方法(无论是统计方法还是机器学习方法)都对亚型进行了明确的假设,然后强制数据符合这些假设。在这种情况下,如果我们知道什么维度可以描述亚型,我们可以开发一个模型以拟合给定维度的指标并预测亚型。这种方法是自顶向下的,并且具有理论上的动机。一种这样的方法是动态因果模型(Dynamic causal modeling, DCM: 一种将BOLD活动与神经活动联系起来的混合建模方法。研究者对模型进行了修改以识别多维空间内的亚群,并有助于克服维数诅咒)扩展而来的,类似于一些流行的方法,例如潜在类分析或有限元模型(在下面说明)。在这种方法中,必须为每个模型指定亚型的数量和特征。其他的模型包括混合模型,如潜在的轨迹增长混合模型来识别ADHD轨迹亚型和潜在类分析来检查ASD亚型。这些模型具有重要的优势。
特别是它们有助于确认假设驱动的疾病学,类似于确认因子模型。他们在预测诊断方面显示出一些希望。通过这种假设,可以很容易地从监督模型中得出推论,并检验有关精神病学的假设。这类方法在精神病学之外已经很成熟。
但是,有监督的方法对答案做出假设。监督模型会偏向于所做的假设,因此受先验知识所告知的假设数量的限制。举一个简单的真实世界的例子,如果我们试图识别美国各地“碳酸饮料”的方言,假设有两种方言(“soda”和“pop”),我们可能会忽略东南部大部分地区都说“coke”(图2A)这一事实。
无监督方法
无监督方法从数据本身的结构或形状来识别亚群。他们通常被认为是自下而上的。例如,精神病理学的层次分类(Hierarchical Taxonomy of Psychopathology,HiTOP:用于识别分层组织亚型的无监督学习方法,这可能有助于克服维数诅咒。与监督学习方法不同,亚型是基于大型数据集的相似性来识别的)是最近提出的新的精神病学分类方法。这种分类是自下而上构建的,由生物学和症状特征之间的关系驱动。它很少对数据或子类型的性质进行假设。相反,子类型是由基于模型中包含的数据定义的。社区检测方法使用类似的自底向上方法来识别多动症人群的新执行功能、气质和神经亚型。类似的方法也被用来通过日常生活数据中的时间模式来揭示人格亚型。频率模式挖掘是一种类似的方法,已用于从基因组数据识别ASD子类型。这种方法对要找到的亚型没有什么假设,因此在识别新的亚型时具有优势。
尽管如此,一些无监督的方法可以通过度量来测试亚群的强度(例如,关于亚群是否真实的统计学度量),但是它们的效用只在某些上下文中缺乏意义。如果使用了错误的或不完整的数据,可能会得到不寻常的分组。考虑一个真实世界的例子,如果使用2016年的投票数据作为算法的输入,农村和城市可能会得到类似于美国2016年总统选举地图的结果(图2B)。然而,如果试图回答的问题是为了识别碳酸饮料的方言,那么这种聚类虽然有效,但用处不大。它看起来一点也不像一个有用的方言图(图2A)。下一节将描述一个类似的临床示例。事实上,虽然监督和非监督的方法都显示出不同的成功方面,但都没有发现与研究者感兴趣的问题相关的新亚型。
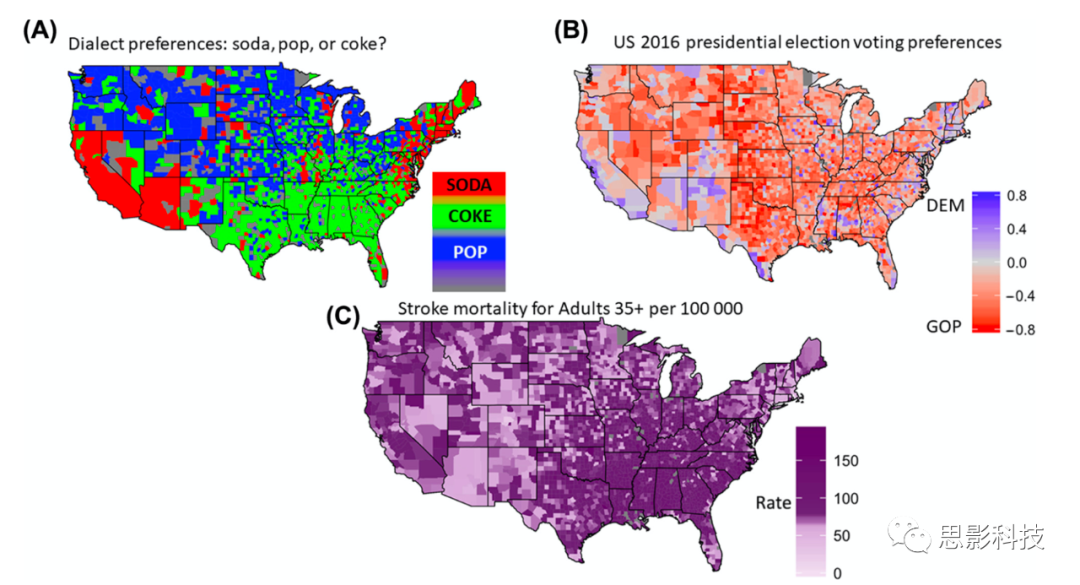
图2 美国的人口地图表现出深刻的异质性。这里展示了几种有效的和重要的方法来对一个种群进行细分。每一个细分都适用于不同类型的问题,类似于分析临床和认知的异质性。(A)美国各地对soda、pop或coke的方言偏好的子类型。语言偏好来自艾伦·麦肯奇的“pop vs soda”调查(http://popvsoda.com/)。调查确定了三种亚型。东海岸/西海岸形成一个使用soda的子类型。东南地区的人喜欢使用coke,这或许反映出可口可乐的总部位于亚特兰大。中西部北部地区使用pop。(B)基于2016年总统选举的美国各地的子类型。数据来自托尼·麦戈文的资源库(https://github.com/tonmcg/County_Level_Election_Results_12-16)。民主党人(DEM;蓝色)和共和党(GOP;红色)按县划分的投票百分比。从投票偏好可以看到两个子类型。以城市为中心的城镇通常投票倾向民主党。农村地区通常更倾向共和党。(C)使用来自美国国家卫生统计中心(https://www.cdc.gov/nchs/data_access/vitalstatsonline.htm)的数据描绘亚型在全美的分布情况。按县绘制了≥35岁成年人的卒中死亡率。可以在东部各州看到一个cluster,不包括东北部和佛罗里达州的顶端,另一个cluster可以在西海岸看到。
人口在多个维度上具有明显的异质性
从概念上说,如上文所述,所有提到的研究的一个中心限制是缺乏对利益问题的考虑。换句话说,由于人类人口的巨大维度(基于环境、行为、生物学/生理学等),有多种方式可以将民众细分为有效的和真实的类别;然而,对于我们关心的问题,任何给定的亚群可能都不重要。例如,考虑图2中显示的每张地图。每张地图都按照语言(图2A)、政治(图2B)和健康(图2C)描绘了美国人口聚类的不同方式。美国沿海地区、北部地区和南部地区对碳酸饮料有不同的方言用语(图2A)。城乡县在2016年总统选举中表现出不同的投票模式(图2B)。与美国其他地区相比,美国东南部地区因中风导致的成人死亡率较高(图2C)。尽管在有效性方面进行了匹配,但每个地图都提出并回答了不同的问题。方言背后的因素可能对理解迁移模式很重要,可以通过媒体和公共广告来衡量。政治偏好可能会影响投票模式,而投票模式可以从民调中预测出来,而且不一定遵循每个洲的边界线。医疗服务、基因或生活方式的差异可能会影响死亡率,这可以通过生物学和/或社会经济数据来预测。换句话说,根据模型中使用的特征的数量和性质,可以用许多不同的方法来划分人口。这种划分的有效性或重要性在很大程度上取决于感兴趣的问题(Box 3)。例如,人们不会使用轮询模式来预测成人中风死亡率。在检查认知或心理健康时,情况可能也是如此。例如,可能有几种方法可以细分患有ADHD、ASD或重度抑郁症的个体,但任何一种可能性的有效性或重要性将取决于感兴趣的问题。
为了提供一个现实世界的例子来强调这些区别的重要性,这里以常见的中风脑血管疾病为例。卒中诊断是已知存在异质性问题的患者群体的一个极好的例子(图3,Key Figure),其中亚型取决于结果或感兴趣的问题。在中风中,可以观察到多种类型的症状,从面瘫到步态受损(图3A),这在出血性中风和缺血性中风中是相对一致的。事实上,在到达急救室时,两个人可能有相同的临床中风症状,但CT扫描可能显示一名病人有出血性中风,而另一名病人的中风是缺血性的(图3B,底部)。这一信息是至关重要的,因为尽管症状相同(类似于目前的精神病学),其机制却截然相反。CT扫描分组将患者分为不同的治疗方案(图3B,C,底部),其中一组患者可能会接受阿司匹林等抗凝药物进行二次卒中预防,而另一组患者接受同样的治疗会使病情严重得多。想象一下,如果每个有中风症状的人都接受干预治疗,那么需要多长时间才能确定抗凝剂是预防继发性中风的重要药物。话虽如此,如果我们对这个病例感兴趣的问题与谁可能对运动治疗康复有反应有关,那么谁有缺血性或出血性中风的分类可能就不那么重要了(图3B,C, top)。相反,运动疗法可能对步态受损的患者有益,但不会对语言生成受损的患者有益。因此,要识别与这个特定问题相关的亚型,需要不同的亚群。如果主要的精神疾病存在异质性问题,那么个体如何聚类在很大程度上取决于结果或兴趣问题(例如患病机制、治疗反应、环境影响等)。
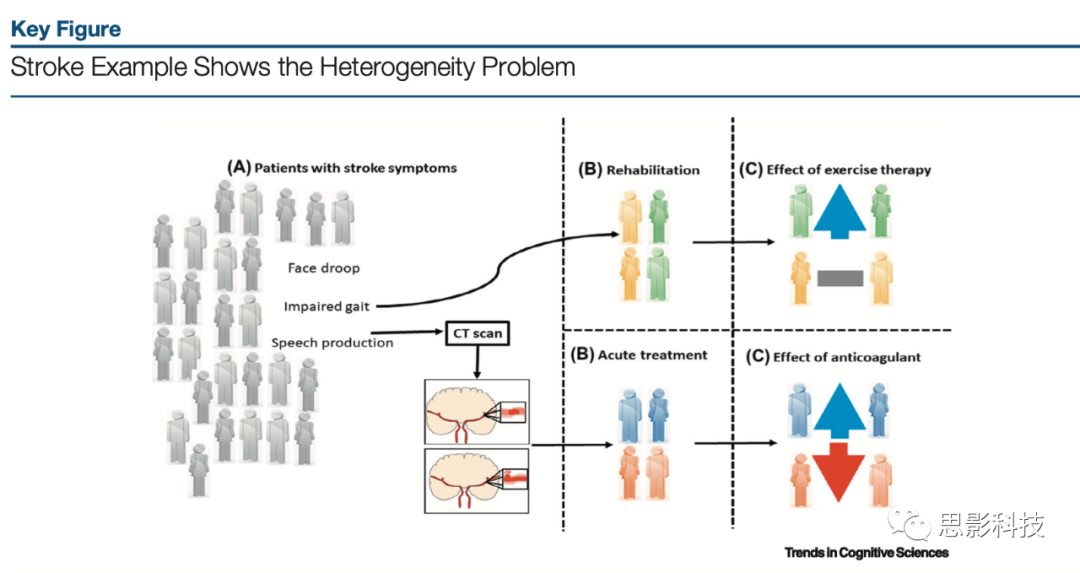
图3 (A)未标记病例(灰色)首先出现面部下垂、言语产生障碍或步态障碍等行为症状。然后对患者进行CT扫描,以确定中风的原因。
(B,底部)根据临床医生确定的结果(如使用抗凝剂华法林)对4例患者进行标记。根据CT扫描结果,患者可分为缺血性中风(蓝色)或出血性中风(红色)两组。
(C,底部)华法林治疗对预后的影响。抗凝剂在急性治疗中的作用,抗凝剂可能对出血性脑卒中患者造成伤害,但对缺血性脑卒中患者有利。在这种情况下,能够在症状和体征之外对个体进行分组是治疗的关键。(B,上)与(B,下)完全相同的情况;然而,现在根据中风症状确定的步态受损(绿色)或说话能力受损(黄色)来分类。(C, 上)康复期间的运动疗法的效果也依赖于不同的亚组(B, 上)。人口(例如中风人口)可以通过许多不同的方式细分为亚群。哪种可能性最重要,很大程度上取决于感兴趣的问题。
集成混合方法可能克服这些局限性
诸如功能随机森林(functional random forest, FRF:一套整合进一个包的方法,以识别与关注问题相关的子类型。克服有监督和无监督方法的局限性。)和代理变量分析(Surrogate variable analysis,SVA:Leek等人开发的方法,来识别与感兴趣的问题无关的子类型。克服了监督和非监督方法的局限性。)之类的混合方法可以通过结合监督和非监督方法的优点来克服这些限制。
FRF将有监督的随机森林(random forest, RF: 包含许多决策树的集成分类方法。FRF的关键部分之一)与无监督的社区检测算法Infomap结合起来,以描述与感兴趣的问题相关的异质性。SVA将无监督主成分分析(Principal component analysis,PCA:将多维数据分解为正交分量的方法)和有监督学习方法结合起来,来描述与兴趣问题相关的异质性(注:结合监督学习和无监督学习的方法有的也称为半监督学习,半监督学习在算法运行过程中分别使用一部分有标签的数据和一部分没有标签的数据。这里推荐发表在Brain上的利用半监督学习方法识别两种精神分裂症亚型的paper:Chand G B, Dwyer D B, Erus G, et al. Two distinct neuroanatomical
subtypes of schizophrenia revealed using machine learning[J]. 链接为思影科技之前的解读:
FRF(功能随机森林)表征生物学上的异质性并鉴定亚型
FRF将机器学习(在本例中为RF)和图论分析(在本例中为群落检测)结合起来,以表征人群内相关的异质性和亚型。FRF结合了有监督的方法和无监督的方法来表征关于问题的未知异质性。可以识别与临床或认知结果相关的亚型(图4)。
首先,数据(称为特征;图4,红色框)通过RF模型(图4,绿色框)与结果拟合,并使用交叉验证评估模型性能。RF模型是一些列决策树的集成(图4,红色框)。决策树是一种通过由一系列二进制规则(成对的分支)组成的路径来分割案例(节点)的模型。案例根据结点上的规则向左或向右流动,多个路径可能会导致相同的结果。输入特征可以包括非结构化的临床记录、临床评估或任务度量,甚至包括高维生物数据。例如,可以形成一个决策树来确定孩子在学校是否需要教育支持。其中一个分支可能会根据智商来划分孩子,而智商低于70的孩子需要支持。另一种可能是通过自闭症诊断来分离儿童,那些确诊的儿童需要支持。关键是,每棵树都是随机生长的。数据的随机子集用于生成伪随机数据集来训练每棵树。在每棵树中,每个规则都是通过从随机选择的特征子集中选择具有最佳划分的规则来确定的。与上面的无监督方法不同,这种随机集成将忽略噪音特征。
RF(随机森林)算法产生一个相似度矩阵(图4,相似度矩阵框),表示成对个体之间的相似度,通过一个分数表示预测结果的概率。然后将来自给定RF的接近矩阵重新构造为一个图,其中节点表示参与者,连边则由参与者-参与者之间的接近度加权。社区检测是一种图论方法(图4,浅蓝色框),迭代地用于识别子组(图4,底部框)。目前使用的社区检测算法是Infomap。Infomap使用随机游走的算法遍历所构建的图来识别社区,社区中个体的子集比社区外的子集包含更多的相互连接的边,而不是不连接的边(注:Infomap是一类很常规的社区发现算法,此外常用的还有Louvain、Label Propagation等等算法。Infomap算法基于最小熵原理:第一步将网络中的每个点当作一个独立社区;第二步则是对网络中的结点随机采样出一个序列,按顺序依次尝试将每个节点赋给邻居节点所在的社区,取平均比特下降最大时的社区赋给该节点,如果没有下降,该节点的社区不变;第三步则是重复第二步直到平均每步编码长度收敛为止)。该技术在许多情况下都很有效。因为Infomap很少对亚群的数量或亚群的组成进行假设,所以用户不需要指定有多少个亚群,这与上面的监督方法不同。这些工具一起代表了FRF。
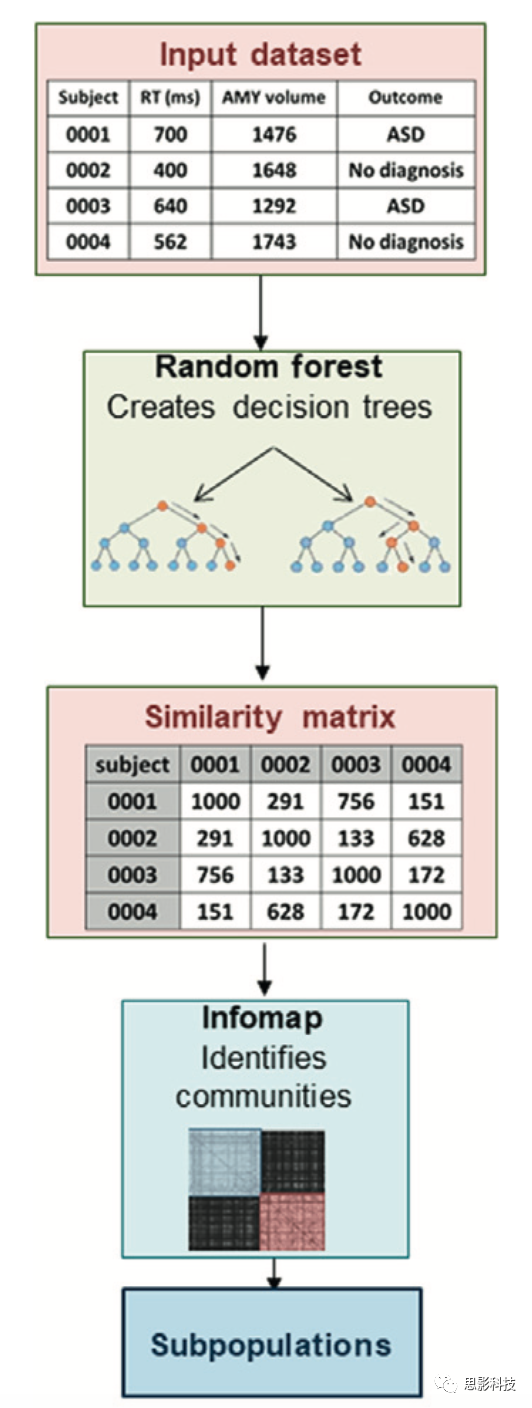
图4 功能随机森林(FRF)识别与感兴趣的问题相关的子类型。FRF试图识别与特定结果或度量相关的亚型。输入数据集(顶部红色面板)被输入到一个RF算法中。输入数据可以包含任意分布的度量,甚至可以是离散的。结果可能是连续的或离散的变量。输入数据被分割成测试和训练数据集,最好是通过5折或10折交叉验证(Box 1)。RF(绿色面板)包括一组决策树。每棵树,对训练数据的子集进行自举重新采样,并用于构建决策树。对于每个分支,选择度量的随机子集。根据结果选择能够最好地拆分数据的度量形成给定分支的规则。当将数据充分划分为适当的分区(称为终端节点)时,决策树将停止生长,从而反映相同或相似的结果度量。对每棵树的测试数据进行评估,对数据进行投票,并通过对投票进行平均来计算预测的结果。个体可能会选择不同的路径(橙色线)来预测相同的结果。通过计算这些路径,可以为输入或独立的数据集形成一个相似矩阵(红色下方的面板),这个矩阵反映了参与者在森林中通过相同路径的总次数。这个矩阵被重新转换为一个图,并输入到一个Infomap算法(浅蓝色面板)中,该算法使用一个随机游走方法来识别子类型(底部面板)。缩写:AMY,杏仁核;ASD:自闭症谱系障碍;RT:反应时间。
FRF的结果反映了研究分析所提出的问题。换句话说,用于识别子类型是否存在的邻近矩阵是专门为预测结果变量构建的。如果模型运行良好,则识别出的亚型可能与结果相关。例如,研究者可以使用相同的数据,根据几个临床变量和人口统计学变量定义诊断亚型。使用相同的输入特征,可能会从与未来学业成绩相关的结果中得出不同的亚型,这将对这些特征产生不同的加权。至关重要的是,FRF对数据输入几乎没有任何假设,并且可以隐式处理同一模型中的分类数据和连续数据。
这种方法的潜在应用可能适用于我们在图3中提到的中风示例。举个例子,一组研究人员对建立一个模型很感兴趣,这个模型可以预测谁将从华法令阻凝剂(注:一种可以预防中风的血液稀释剂)中受益,从而预防随后的中风。在这个假设的例子中,研究人员不知道中风行为后遗症的真正机制,但知道在出现时,在人口统计学、健康史、环境暴露、症状和CT发现方面存在差异。他们还知道,并非所有中风患者都能从抗凝治疗中获益。他们有一个庞大的中风患者群体,他们的所有模型输入特征(即、人口统计、症状等)及其长期结果(即,预防或不预防新中风)。这种情况类似于关于精神健康状况的临床研究的当前状况。如果研究人员使用当前的有监督或无监督方法,而未利用感兴趣的结果(即二级预防)来分析所有特征的变异性,则他们可能会根据给定方法的约束和偏见来识别不同类型的聚类。例如,由于数据集中这一特性的精确性,一种将数据强制分为两组的监督方法可能主要适合于男性和女性。此子分组是有效的,但对感兴趣的结果的影响有限。当然,根据实际使用的模型类型和指定的模型参数,结果的数量几乎是无限的;然而,这种监督的方法限制了我们识别特定于我们感兴趣的结果的模型的机会。无监督模型虽然不需要像亚群的数量这样的显式参数,但也不能保证给出对我们的问题或结果很重要的最优分组决策。
在这种情况下,类似FRF的方法具有优势。使用FRF的研究人员将利用所有相同的特征来生成模型;然而,建模的第一阶段将首先确定输入的特征是否能够预测感兴趣的结果,然后确定哪些特征对于预测是重要的(即,它会过滤掉与二级预防有关的“不感兴趣”的特征)。就我们而言,人口统计和环境措施与二级预防和华法令的使用无关。因此,它们对预测的贡献有限,因此在确定亚群时不会被高度加权[例如,邻近矩阵和社区检测亚组将由CT扫描驱动,因为CT测量最有助于预测感兴趣的结果(图3B,C,底部)]。重要的是,简单地改变感兴趣的结果(例如,运动疗法的有效性)将导致模型以不同的方式对输入特征进行加权(图3B,C, top)。反过来,根据新的结果衡量标准,这些差异将形成不同的亚群。
FRF最近已用于原理证明研究中,以识别推定的ASD和与ASD诊断相关的典型亚型。利用反映多个认知领域的任务的行为数据预测自闭症谱系障碍的诊断和典型样本。FRF确定了3个假定的ASD和4个假定的典型亚群。两组亚组在认知水平上均表现出相似的变异,提示ASD异质性可能嵌套在典型异质性内。ASD亚组之间的功能脑组织差异与ASD和典型样本之间的差异具有一定程度的重叠,表明这些亚组具有生物学相关性(图5)。

图5 功能连接模式因功能随机森林(FRF)标识的子类型而异。此图是从将FRF应用于行为数据的地方修改而来的。获得了三个自闭症谱系障碍(ASD SG1、ASD SG2和ASD SG3)亚型和一个典型亚型(CON SG1)的充分的功能连接磁共振成像(fcMRI)数据。使用先前研究中描述的系统进行χ2分析,以确定网络系统内部或网络系统之间在这些组中存在非典型的差异。χ2分析测试两个社区内部或之间的显着变化的连接数量是否大于偶然观察到的数量。 在这里,分析揭示了亚群的系统内和系统间效应。结果发现,与对照组相比,ASD组有7种不同程度的影响。这里显示四个。(AUD-CIP)ASD分组1显示听觉(AUD)和cingulo–parietal(CIP)系统之间的连通性增强。(CIO-DEF) ASD的第2组和第3组显示了带状盖(cingulo–opercular,CiO)和默认(DEF)系统之间的连通性增加。(DEF-DEF) 所有三个ASD子组在默认系统(DEF)中都显示连接性下降。(DEF-SMH) ASD子组3显示了默认(DEF)和躯体运动(somatomotor–hand,SMH)系统之间的连接性增强,而ASD子组2显示了连接性降低。综上所述,这些发现强调了不同的连通性模式,即使从行为数据中识别出了这些亚组,也无法反映出简单的严重程度。
SVA(代理变量分析)表征生物学上不相关的异质性以发现亚型
SVA是一种用于异质性的混合集成方法,最初是为了消除基因组数据中的批次效应(batch effect)而开发的。该方法不同于但类似于FRF。简而言之,在基因组研究中获得的数据通常会由于样本采集方法,测序日期以及与真实基因组变异无关的其他原因而发生分组或聚类。批处理效应类似于异质性问题(Box 1),其中可以在样本中识别的子类型可能由多种机制驱动;但是,在这种情况下,子分组的驱动程序与所问的特定问题无关。关于特定批处理效果的原因的细节可能是未知的,研究者也无法对其进行建模。SVA通过首先生成一个与研究中提出的问题相关的模型来解决这个问题。换句话说,模型的选择取决于用户提出的问题。然后提取拟合数据的残差,这些残差与问题或结果无关。因此,在残差中可以确定的任何潜在集群都很可能是批处理效应。SVA没有尝试直接测量此类集群;相反,使用PCA在数据的残差中识别出代表这些子组的潜在变量,其中这些变量的组合等价于总体上的批处理效果的组合。残差数据现在被分解成一系列独立的线性分量,每个分量由数据特征的加权和组成。在对数据进行建模时,可以控制这些分量,从而避免与感兴趣的问题无关的样本中的异质性。关键的是,因为批处理效果没有明确地建模,所以SVA可以揭示和控制与兴趣问题无关的未知异质性。
使用上面相同的中风例子,SVA首先将所有的特征建模为感兴趣问题的函数——再次,使用华法令后的中风二级预防。在这种情况下,原模型与CT扫描相关结果具有较强的对应关系。然后从拟合数据中提取残差,同样,残差与问题或结果无关。使用PCA在残差数据中识别的潜在变量将代表数据中与特定结果无关的分组变量(如性别、社会经济状况、行为症状等)。在对数据进行建模时,可以控制这些成分,从而避免在使用华法林后与卒中预防无关的样本中的异质性。
由于SVA所描述的异质性与问题无关,因此仅使用该方法无法识别有意义的亚群。然而,通过去除批处理效应,SVA与后续的无监督方法相结合,可以更好地识别与临床结果相关的亚群。例如,在髓细胞性白血病的背景下,SVA使后续的亚型分析方法能够正确识别先前验证的亚型。通过SVA消除批次效应还有助于后续的无监督方法,以发现炎症标志物与许多疾病中所涉及的常见途径之间的重叠,并鉴定引起肿瘤的途径的功能成分。
SVA有一些局限性。不幸的是,由于SVA试图消除不需要的异质性,如果没有其他方法的帮助,该方法就无法识别亚型。此外,如果就问题建立了错误的或不完整的生物变量模型,则SVA可能具有误导性。生物异质性可能被移除,导致无效甚至人为的结果。尽管有这些限制,但SVA是表征数据集中未知异质性的强大工具,因为它会尝试针对感兴趣的问题表征异质性。
异质性问题的解决需要对混合方法进行进一步研究
虽然异质性问题并不是一个新的问题,但是很少有集成混合方法被用来克服异质性问题。上述方法是横断面和探索性的,不是纵向的也不是验证性的(参见Box 4,了解FRF如何应用于纵向数据和确定亚群的方法)。此外,这里展示的两种集成技术都有局限性。SVA可能不适合纵向数据,如果考虑了错误的变量,可能会消除生物异质性。与一个问题相关的批处理效果可能会通过FRF污染已识别的亚型,而去除批处理效果的方法实际上可能会混淆FRF。此外,处理丢失数据的方法仍在开发中。
Box 4 纵向研究方法可能有助于完善精神病学
在表征典型或非典型人群的异质性时,在许多情况下,应考虑纵向发育的差异(Box 2)。将来的工作可能将纵向方法与用于此目的的有监督和无监督方法结合在一起。例如,功能数据分析可用于扩展FRF并根据纵向轨迹表征异质性。功能数据分析(FDA)是最近推出的一种方法,该方法使用一组基本函数来识别每个人的轨迹。在第一阶段,使用分段多项式函数拟合每个个体的每种症状的轨迹,并产生一组系数。在以下情况下,四阶B样条曲线用于拟合各个轨迹,并受到二阶B样条曲线的惩罚。每个测得的时间点都拟合了一个锚点(锚点是用来拟合B样条曲线的关键点)。虽然样条拟合可以处理不定期收集的数据,但估计轨迹至少需要四个时间点。
为了描述来自纵向数据的轨迹的异质性,可以利用来自FDA的单个轨迹的信息。可以使用两种方法(图I)。(I)从轨迹(如被试与被试之间的相关)上可以形成一个相似矩阵,并迭代使用Infomap来识别亚群(蓝色无监督路径);或(ii)每个个体的基函数参数可能被输入到随后的邻近矩阵(red hybrid pathway)上进行的RF和群落检测中。每个个体的基本函数的参数可以输入到RF中,并在随后的邻近矩阵上执行社区检测(红色混合路径)。
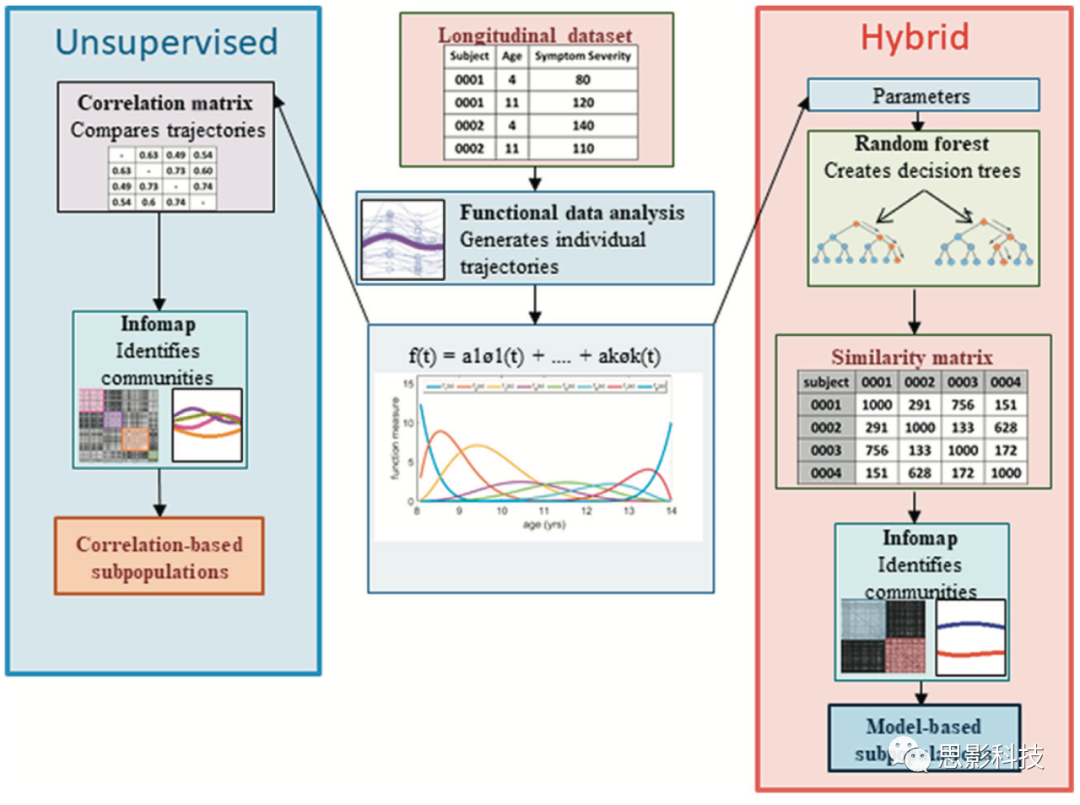
图I.功能随机森林(FRF)可以从纵向数据中识别亚型。在输入数据集(中间红色面板)每个案例至少包含四个时间点的数据。在模型中可以看到第一个时间点和最后一个时间点的数据同时出现在模型的最右拟合区域(中间下面板)。b样条基本函数拟合到每个case的每个时间序列上(混合红色面板)。根据情况,从拟合函数中提取参数并将其输入FRF(请参见正文中的图4)。通过这种方法识别的基于模型的亚型可以与一个问题联系起来。亚型也可以通过无监督的方法来识别(无监督的蓝色面板)。首先,通过计算每种情况下预测轨迹之间的相关性,得到相关矩阵。然后将相关矩阵输入到Infomap中,Infomap识别基于相关性的亚型。
总结
对于试图了解典型认知和心理健康的生理和生物学联系的研究者来说,异质性问题是一个严峻的挑战。本文强调的混合方法代表了在大规模基础科学和复杂人类行为的临床研究中表征异质性的早期但关键的进展,可以作为解决异质性问题的指导性文献来阅读。当然,这项工作仍处于初期阶段,在用于研究大脑和认知的各种数据类型中,需要未来的发展和各种方法的比较。绘制人类大脑在结构和功能上跨越发展和衰老的过程,表征典型和非典型人群的异质性可能将成为这些努力的主要组成部分。
原文:The Heterogeneity Problem: Approaches
to Identify Psychiatric Subtypes

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
第十四届磁共振脑网络数据处理班(重庆,7.26-31)
第三十届磁共振脑影像基础班(南京,7.31-8.5)
第十届脑影像机器学习班(南京,6.30-7.5)
第十二届磁共振弥散张量成像数据处理班(南京,6.18-23)
第二十届脑电数据处理中级班(重庆,8.9-14)