

阿尔茨海默症是全世界痴呆症的主要病因,随着人口老龄化,患病负担不断增加,在未来可能会超出社会的诊断和管理能力。目前的诊断方法结合患者病史、神经心理学检测和MRI来识别可能的病例,然而有效的做法仍然应用不一,缺乏敏感性和特异性。在这里,本文报告了一种可解释的深度学习策略,该策略从MRI、年龄、性别和简易智力状况检查量表(mini-mental state examination ,MMSE) 得分等多模式输入中描绘出独特的阿尔茨海默病特征(signatures)。该框架连接了一个完全卷积网络,该网络从局部大脑结构到多层感知器构建了疾病概率的高分辨率图,并对个体阿尔茨海默病风险进行了精确、直观的可视化,以达到准确诊断的目的。该模型使用临床诊断的阿尔茨海默病患者和认知正常的受试者进行训练,这些受试者来自阿尔茨海默病神经影像学倡议(ADNI)数据集(n = 417),并在三个独立的数据集上进行验证:澳大利亚老龄化影像、生物标志物和生活方式研究(AIBL)(n = 382)、弗雷明汉心脏研究(FHS)(n = 102)和国家阿尔茨海默病协调中心(NACC)(n = 582)。使用多模态输入的模型的性能在各数据集中是一致的,ADNI研究、AIBL、FHS研究和NACC数据集的平均曲线下面积值分别为0.996、0.974、0.876和0.954。此外,本文的方法超过了多机构执业神经科医生团队(n = 11)的诊断性能,通过密切跟踪死后组织病理学的损伤脑组织验证了模型和医生团队的预测结果。该框架提供了一种可适应临床的策略,用于使用常规可用的成像技术(如MRI)来生成用于阿尔茨海默病诊断的细微神经成像特征;以及将深度学习与人类疾病的病理生理过程联系起来的通用方法。本研究发表在BRAIN杂志。
研究背景
全球仍有数百万人受到阿尔茨海默病的困扰,而开发有效的疾病修正疗法的尝试仍然停滞不前。尽管使用脑脊液(CSF)生物标志物以及PET淀粉样蛋白和tau成像来检测阿尔茨海默病病理已经取得了巨大的进展,但这些方式往往仍然局限于研究背景。目前的诊断标准依赖于高度熟练的神经科医生进行检查,包括询问患者病史,客观的认知评估,如简易智力状况检查量表(MMSE)或神经心理学测试,以及结构性MRI以排除某些疑似阿尔茨海默病的结果。临床病理研究表明,临床医生的诊断敏感性在70.9%~87.3%之间,特异性在44.3%~70.8%之间。虽然核磁共振揭示了阿尔茨海默病特有的大脑变化,如海马和顶叶萎缩,但这些特征被认为对基于影像学的阿尔茨海默病诊断缺乏特异性。鉴于这种相对不精确的诊断环境,以及CSF和PET诊断的侵入性以及缺乏具有足够阿尔茨海默病诊断专业知识的临床医生,先进的机器学习范式,如深度学习(LeCun等人,2015年;Hinton,2018年;Topol,2019年),提供了从神经科实践范围内收集的MRI数据中获得高精度预测的方法。
最近的研究已经证明了深度学习方法的应用,如卷积神经网络用于MRI成像和基于多模态数据的认知状态分类。尽管取得了令人振奋的成果,但由于以下几个原因,这些模型尚未实现与临床实践的全面结合。首先,由于大多数模型都是在单一数据集上进行训练和测试,因此缺乏对深度学习算法的外部验证。其次,生物医学界越来越多的人认为深度学习模型是“黑箱”算法。换句话说,尽管深度学习模型在对许多疾病进行分类时精度非常高,但它们既没有阐明底层的诊断决策,也没有指出与输出的预测相关的输入特征。最后,考虑到阿尔茨海默病发病的不确定性和症状的异质性,阿尔茨海默病的在计算层面预测的个体水平特征仍未解决。考虑到这些因素,本文作者指出深度学习的临床潜力因缺乏单一数据集驱动模型的外部验证,以及越来越多地使用不透明的决策框架而被削弱。因此,克服这些挑战不仅对利用深度学习算法的潜力来改善患者护理至关重要,而且还为医学影像界可解释的循证机器学习铺平了道路。
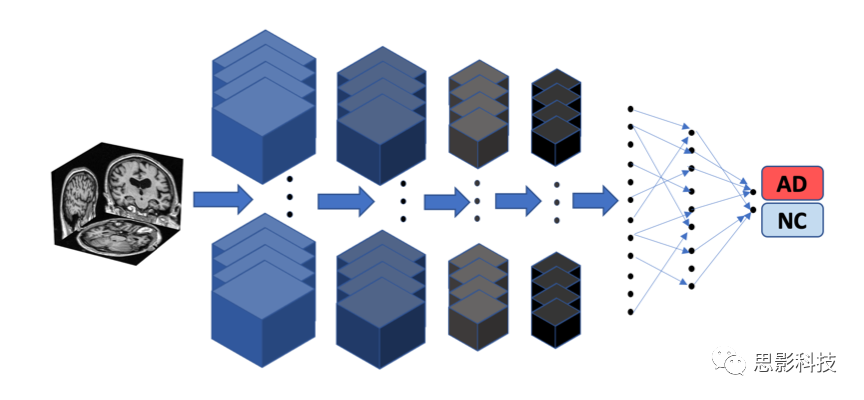
为了解决这些局限性,本文开发了一种新型的深度学习框架,将完全卷积网络(FCN)与传统的多层感知器(MLP)连接起来,对阿尔茨海默病风险进行高分辨率可视化,然后用于准确预测阿尔茨海默病状态(图1)。作者选择了四个不同的数据集进行模型开发和验证:阿尔茨海默病神经影像学倡议(ADNI)数据集、澳大利亚老龄化影像、生物标志物和生活方式研究(AIBL)、弗雷明汉心脏研究(FHS)和国家阿尔茨海默病协调中心(NACC)(表1和补充图1)。模型预测与神经病理学研究结果的关联,以及与神经学家团队对模型性能的正面(head-to-head comparison)比较,都显示了深度学习框架的有效性。
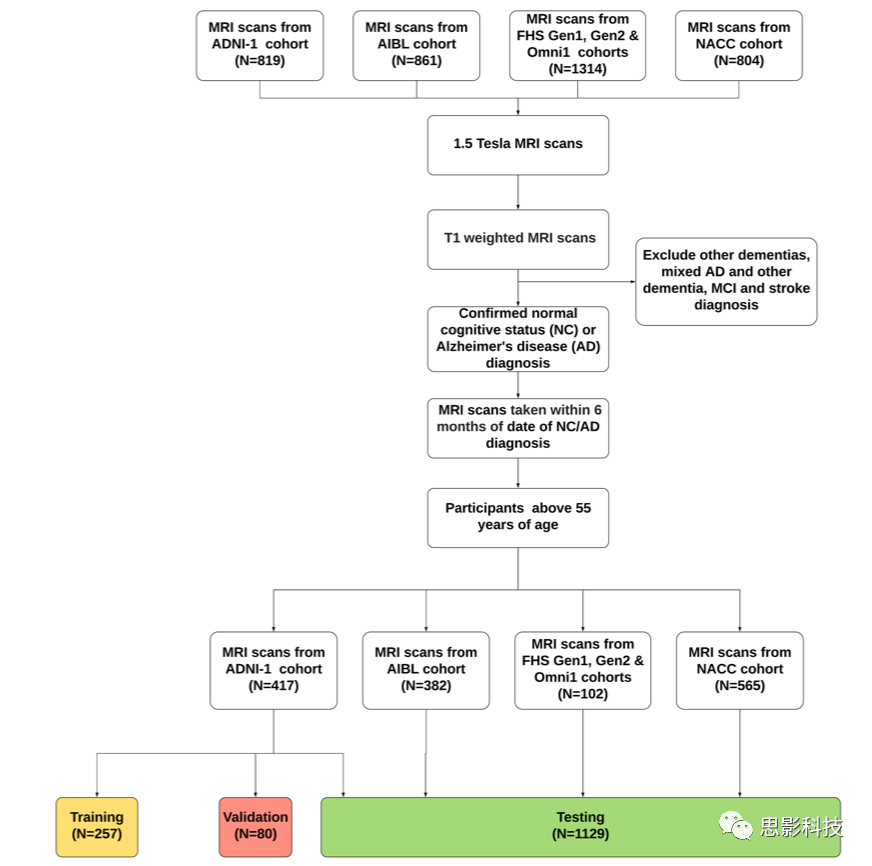
补充图1:受试者选择标准。在每个数据集中,从参与者中选择T1加权1.5T MRI(更多细节见方法)。只有在AD诊断或最后一次确诊的临床就诊(在NC参与者的情况下)6个月内收集的MRI被纳入分析。将ADNI数据以3:1:1的比例分割为训练、验证和测试集,并将完全训练好的模型应用于NACC、FHS和AIBL,以评估模型的泛化能力。
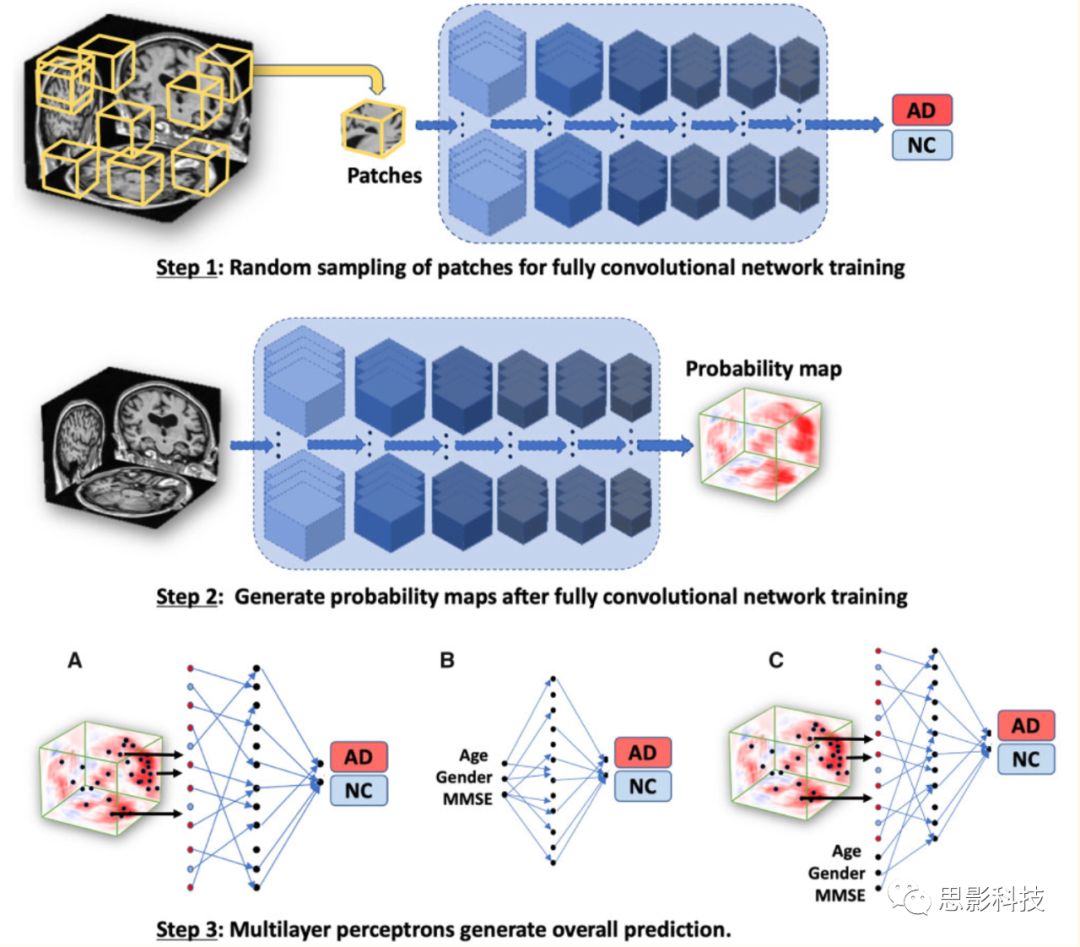
图1.深度学习框架示意图。
FCN模型是使用基于patch的策略开发的,其中从T1加权全MRI体积中随机选择的样本(大小为47×47×47个体素的子体)被传递给模型进行训练(步骤1)。对应的个体的阿尔茨海默病状态作为分类模型的输出。鉴于FCNs的操作与输入数据大小无关,该模型最终生成特定于个体大脑的疾病概率图(步骤2)。从疾病概率图中选出高危体素,然后传递给MLP进行疾病状态的二元分类(步骤3中的模型A;MRI模型)。作为进一步的对照,只使用非影像学特征,包括年龄,性别和MMSE,并开发了一个MLP模型,以分类阿尔茨海默病和那些健康的参与者(步骤3中的模型B;非影像学模型)。
本文还开发了另一个模型,该模型集成了多模式输入数据,包括选定的高危疾病概率图的体素,以及年龄、性别和MMSE得分,以执行二元分类的阿尔茨海默氏病状态(步骤3中的模型C;融合模型)。AD=阿尔茨海默病;NC=正常认知。
材料和方法
参与者和数据收集
研究中使用了ADNI、AIBL、FHS和NACC数据集中的数据(表1和补充图1)。ADNI是一项纵向多中心研究,旨在开发临床、影像、基因和生化生物标志物,用于阿尔茨海默病的早期检测和追踪(Petersen等,2010)。AIBL于2006年启动,是澳大利亚同类研究中规模最大的,旨在发现影响症状性阿尔茨海默病发展的生物标志物、认知特征和生活方式因素(Ellis等,2010)。FHS是一项纵向的社区数据集研究,已经收集了三代人的广泛临床数据(Massaro等,2004)。自1976年以来,FHS扩展到评估导致认知衰退、痴呆和阿尔茨海默病的因素。最后,1999年成立的NACC,维护着一个大型关系数据库,该数据库包含了从美国各地阿尔茨海默病中心收集的标准化临床和神经病理研究数据(Beekly等,2004)。
模型训练、内部验证和测试都是在ADNI数据集上进行的。在对ADNI数据进行训练和内部测试后,验证了对AIBL、FHS和NACC的预测。选择的标准包括年龄≥55岁,自临床确诊阿尔茨海默病或认知正常之日起±6个月内拍摄的1.5T、T1加权MRI扫描的个体(补充图1)。排除了包括阿尔茨海默病合并混合性痴呆、非阿尔茨海默病痴呆、严重创伤性脑损伤史、严重抑郁症、脑卒中和脑肿瘤以及偶然发生的重大系统性疾病的病例。需要注意的是,这个纳入和排除标准是从ADNI研究(Petersen等,2010)制定的基线招募方案中调整而来的,为了保持一致性,同样的标准也适用于其他数据集。这导致从ADNI数据集中选择了417人,从AIBL中选择了382人,从FHS参与者中选择了102人,从NACC数据集中选择了565人。如果一个人在时间窗口内有多次MRI扫描,那么我们选择最接近临床诊断日期的扫描。对于这些选定的大多数病例,年龄、性别和MMSE评分都是可用的。
算法设计
本文设计了一个FCN(完全卷积网络)模型,输入体素大小为181×217×181的配准好的voxel水平的MRI图像,并输出每个位置的阿尔茨海默病等级的概率。使用了一种新颖的、计算效率高的基于patch的训练策略来训练FCN模型(图1)。这个过程涉及从每个训练对象的MRI扫描中随机抽取3000个大小为47×47×47个体素的体积patch,并使用这些信息来预测感兴趣的输出(补充图2)。patch的大小与FCN的感受野(receptive field)大小相同。

补充图2:用于FCN训练的最佳patch数量的选择。图中显示了FCN模型性能作为用于训练的patch数量的函数。y轴表示在疾病概率图的所有体素上计算的平均验证精度。请注意,平均性能是在五个独立的模型运行上计算出来的。
FCN由六个卷积块组成(补充表1)。前四个卷积块由一个3D卷积层组成,后面紧跟:3D最大池化(3D max pooling)、3D批量归一化(3D batch-normalization)、Leaky Relu和Dropout。最后两个卷积层在分类任务方面起到了全连接层(dense layers)的作用,这两个层在提升模型效率方面起到了关键作用(Shelhamer等人,2017)。该网络是用随机初始化的权重从头进行训练的。我们使用了Adam优化器,学习率为0.0001,mini-batch大小为10。在训练过程中,当模型在ADNI验证数据集上取得最低的误差时,模型被保存。在FCN训练后,一幅MRI图像被完整处理并报告,以获得完整的疾病概率阵列,即疾病概率图。训练完成后,从测试样本中获取疾病概率图的过程在NVIDIA GTX Titan GPU(不错,很高端)上需要大约1s。

补充表1:针对以patch为基础的训练和体数据整体应用的FCN架构和超参数总结。FCN模型在大小为47x47x47的patch上进行训练,以便从随机采样的子体积数据中产生AD状态的标量(1x1x1)预测。在网络内的每个卷积步骤之后,在通过Leaky ReLU函数激活之前都要进行最大池化和批量归一化。通道深度、内核大小、填充和步长超参数与网络每一步的dropout概率一起显示。将相同的模型架构应用到全尺寸图像中,产生了尺寸为46x55x46的3D张量,该3D张量可以通过传递到softmax函数转化为疾病概率图。
【译者注:
Max-pooling:下采样,做了特征选择,选出了分类辨识度更好的特征,提供了非线性,更多的保留纹理信息。
Batch Normalization:批量归一化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法。
Dropout:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作(随机丢弃),这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
Leaky ReLU :ReLU函数为非线性激活函数,代表的的是“修正线性单元”,它是带有卷积图像的输入x的最大函数(x,o)。 ReLU是将所有的负值都设为零,相反,Leaky ReLU是给所有负值赋予一个非零斜率。】
FCN是通过重复应用于从一个完整体积的顺序MRI图像中随机采样的体素的立方体patches来训练的。由于卷积通过连续的网络层减小了输入尺寸(the convolutions decrease the size of the input),因此选择每个patch的大小使每个patch的最终输出的形状等于2×1×1×1(补充表1);即在训练期间,FCN对每个patch的处理产生了两个标量值的列表。这些值可以通过应用softmax函数转换为各自的阿尔茨海默病和正常识别概率,然后用这两个概率中较大的一个来进行疾病状态的分类。通过这种方式,该模型被训练成通过对大脑结构的局部状态来对整体疾病状态进行推测。
在生成所有受试者的疾病概率图后,利用一个MLP模型框架,通过从疾病概率图中选择阿尔茨海默病的概率值,进行二元分类来预测阿尔茨海默病状态。这种选择是基于通过对ADNI训练数据使用Matthew相关系数值分析进行估计,对FCN分类器整体性能表现的观察。具体来说,我们从200个固定的位置中选择了疾病概率图体素,这些位置被认为具有较高的Matthew相关系数值(补充表2)。从这些位置提取的特征作为MLP模型的输入,该模型对阿尔茨海默病状态进行二元分类(图1中的MRI模型,步骤3)。另外开发了两个MLP模型,其中一个模型使用年龄、性别和MMSE评分值作为输入来预测阿尔茨海默病状态(图1中的非影像学模型,步骤3),另一个MLP将200个特征与年龄、性别和MMSE评分一起作为输入来预测阿尔茨海默病状态(图1中的融合模型,步骤3)。所有的MLP模型都由一个隐藏层和一个输出层组成(补充表3)。MLP模型还包括ReLu和Dropout等非线性算子(non-linear operators)。
【译者注:
MLP模型:即多层感知机(MLP,Multilayer Perceptron),也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构。多层感知机层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。】
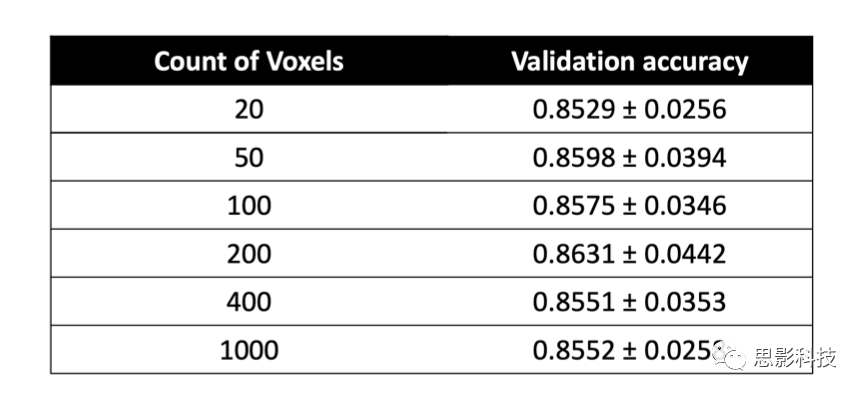
补充表2:MCC热图上的最佳体素选择。MLP模型的平均性能作为所选体素数量的函数,以定义与AD状态最相关的区域。这个结果是在ADNI验证数据集上生成的。
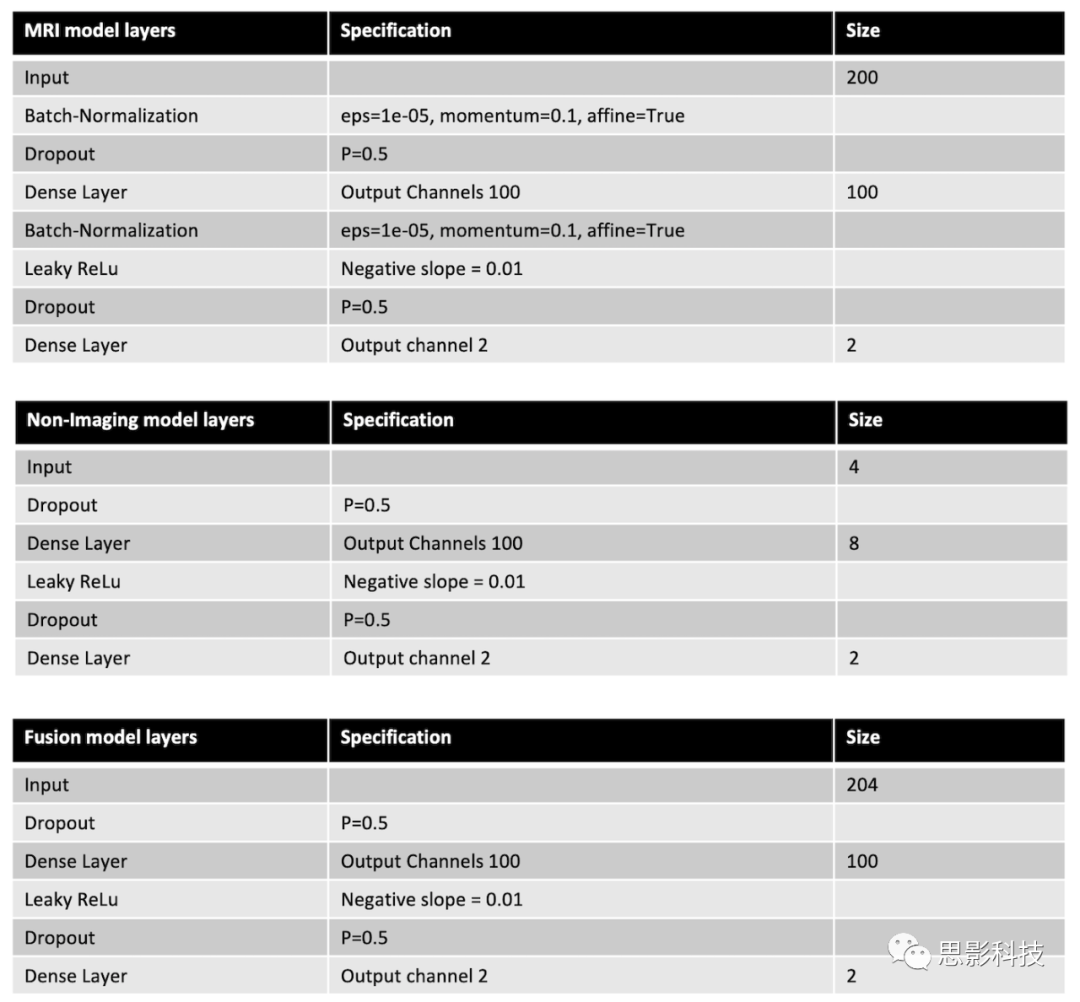
补充表3.仅使用MRI模型、非成像模型和融合模型所使用的MLP架构总结。每个MLP模型由两个全连接层组成。在每个全连接层之前,使用0.5的dropout值来正则化模型。在每个全连接层之后,使用Leaky ReLu激活。对于仅使用MRI的模型,还在每个全连接层之前加入了一个批次归一化层。
图像配准、强度归一化和MRI体积分割
从所有数据集的MRI扫描获得NIFTI格式。使用MNI152模板(ICBM 2009c非线性对称模板,麦吉尔大学,加拿大)配准所有扫描。我们使用FSL软件包(威康中心,牛津大学,英国)提供的FLIRT工具,将扫描图像与MNI152模板对齐。对配准的图像进行仔细的手动检查,发现自动配准在绝大多数ADNI、AIBL和NACC病例上做得相当好。对于没有配准好的病例(主要是FHS内),进行了仿射变换,以已知区域作为对照标准(landmark)进行人工配准。考虑到可能不存在适用于所有MRI扫描的配准方法,我们的两步过程产生了一组合理的配准图像。
图像配准后,对所有体素的强度进行归一化[平均值=0,标准差(SD)=1]。然后,通过将这些体素和其他异常值修正到以下范围来调整它们的强度:[-1,2.5],其中强度低于-1的任何体素的值都被指定为-1,强度高于2.5的体素的值被指定为2.5。然后,进行背景去除,其中颅骨外背景区域的所有体素都被设置为-1,以确保单一的背景强度。
来自FHS数据集的11个个体的体积MRI扫描的皮质和皮质下结构,以及大脑的解剖结构,使用Freesurfer进行了分割(Fischl,2012)。Freesurfer的内置功能,如 "recon-all","mri_annotation2label","tkregister2","mri_label2vol","mri_convert "和 "mris_calc "被用来获得分割的结构。
神经病理学验证
通过将预测的大脑区域与尸检结果重叠,验证了FCN模型识别阿尔茨海默病高风险区域的能力。对来自FHS数据集的11个尸检的大脑进行了组织病理学评估,11人中有4人确诊为阿尔茨海默病。在神经病理评价过程中,对所有人口学和临床信息进行了盲法评估。神经病理评估的详细描述之前已经报道过(Au等人,2012)。在这项研究中,检查了从皮质和皮质下区域内提取的石蜡包埋切片中的神经纤维缠结、弥漫性斑块、神经炎性老年斑或致密性老年斑。用Bielschowsky银染色法对切片进行染色。对磷酸化的tau蛋白(Innogenetics, AT8, 1:2000)和淀粉样蛋白b(Dako,
6F-3D, 1:500, 在90%for-mic acid中预处理2分钟)进行免疫细胞化学染色。半定量评估每200视野神经原纤维缠结的最大密度,并按1~4分进行评分(1+:1个神经纤维缠绕/视野;2+:2~5个神经纤维缠绕/视野;3+:6~9个神经纤维缠绕/视野;4+:510个神经纤维缠绕/视野)。同样,弥漫性老年斑、神经炎斑块和致密老年斑块在100显微镜视野下检查,并分别进行评分,评分范围在1和4之间(1+:1-9个斑块/视野;2+:10-19/视野,3+:20-32/视野,4+:432/视野)。最后通过3个显微镜场的平均数进行测定。将每个脑区的神经纤维缠结、弥漫性老年斑、神经性或致密性老年斑的密度与该区域的阿尔茨海默病概率进行定性比较。
神经科医生验证
9名美国委员会认证的执业神经科医生和2名非美国执业神经科医生(均称为神经科医生)被要求提供从ADNI数据集中随机选择的80例未用于模型训练的病例的诊断印象(阿尔茨海默病与正常认知)。对于每个病例,神经科医生都被提供了完整体积的T1加权MRI扫描、受试者的年龄、性别及其MMSE评分用于评估。同样的参数用于训练模型(图1中的融合模型)。为了获得深度学习模型与普通神经学家相比的估计,对单独评估每个测试案例的神经科医生的表现特征进行了平均。有关神经科医生对评级的更多细节可以在补充材料中找到。
卷积神经网络模型开发
创建了一个3D CNN来进行阿尔茨海默病和正常认知病例的分类,并将其结果与FCN模型进行了比较。CNN模型是在与FCN模型相同的数据分割上进行训练、验证和测试的。为了便于与FCN模型进行直接比较,仅使用MRI数据开发了一个CNN模型,以及一个额外的MLP(多层感知器),其中包括CNN模型衍生的特征以及年龄、性别和MMSE评分。与FCN-MLP模型类似,也合并了基于CNN的成像特征(即CNN第一全连接层后的特征向量)和非成像特征进行MLP训练。
CNN模型由四个卷积层组成,后面紧跟两个全连接层(补充图3和补充表4)。每个卷积层后面都有ReLu激活。卷积块之间的最大池化层被用来对特征图进行下采样。在每个卷积层之后应用了批量归一化、Leaky ReLu和dropout。Dropout和Leaky ReLu被应用在全连接层的特征向量上。在最后的全连接层上应用了Softmax。CNN模型是用与FCN模型相同的优化器和损失函数从头开始训练的。使用了0.0001的学习率,mini-batch为6。在ADNI验证数据集上性能最好的CNN模型被用于预测测试数据集上的阿尔茨海默病状态。
补充图3.三维卷积神经网络(CNN)示意图。CNN模型由4个卷积层组成,后面是2个全连接层,在整个MRI体积上进行训练,以预测AD状态。

补充表4. 卷积神经网络(CNN)架构和超参数的总结。CNN模型内的每一个卷积层都是在最大池化、批量归一化、Leaky ReLu和dropout激活之后进行的。显示了每层的具体设置,即通道深度,内核大小,填充,步长,dropout率和动量。
随机森林模型
从ADNI数据集中,基于体素的MRI 形态测量分析表中获得的MRI测量(n = 117)作为输入,构建随机森林(RF)分类器来预测阿尔茨海默病状态。使用不同的随机种子重复构建随机森林模型10次,并报告模型的平均性能。
性能矩阵
在ADNI数据集上构建模型,将其随机分为三组,分别进行训练、验证和测试。在每一次训练和验证的拆分上建立模型,并对测试数据集(ADNI测试、AIBL、FHS和NACC)的性能进行评估,这个过程重复5次。性能以模型运行的平均值和标准差的形式呈现。来自ADNI测试数据集的扫描用于与神经学家进行比较(head-to-head comparison)。
基于对ADNI测试数据以及其他独立数据集(AIBL、FHS和NACC)的模型预测,生成了灵敏度-特异性和精确度-召回率曲线。对于每条灵敏度-特异性和精确度-召回率曲线,还计算了曲线下面积(AUC)值。此外,还计算了每组模型预测的灵敏度、特异性、F1-得分和Matthews相关系数。F1-得分同时考虑了测试的精确度和召回率,定义为:
F1 = 2 × TP/(2 × TP + FP + FN) (1)
这里,TP表示真阳性值,FP和FN分别表示假阳性和假阴性情况。马太相关系数(MCC)是衡量二元分类器对不同大小的数据集分类质量的一个平衡指标,定义如下:
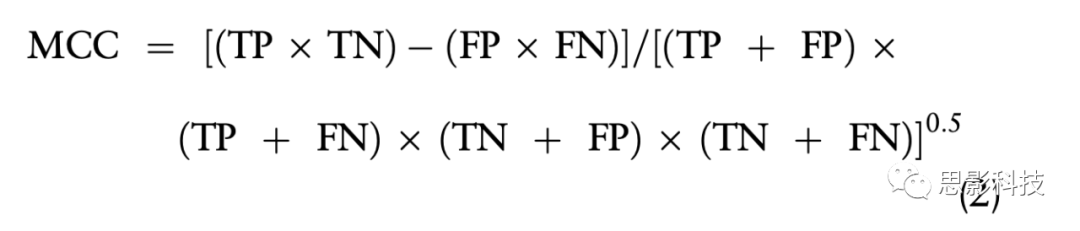
TN表示真负值。我们还使用Cohen’s kappa值计算了解释者之间(inter-annotator)的一致性,即两个解释者同意诊断的次数之比。统计量衡量分类项目的评分者(inter-rater)之间的一致性。分数(Cohen’s kappa-score)为1表示注释者之间完全一致(perfect agreement between the annotators)。
【译者注:Cohen’s kappa值:用于评价多个医生诊断结果一致性。Cohen’s kappa统计量,是分类变量X和Y之间一致性的度量。例如,kappa可用于比较不同待评估者将受试者分类到若干组之中某个类别的能力。当新技术正在研究中时,Kappa还可用于评估替代分类的评估方法之间的一致性。】
统计分析
为了评估正常认知组和阿尔茨海默病组之间的总体差异显著水平,对连续变量和分类变量分别采用两样本t检验和