

近年来,基于神经成像的方法被广泛应用于精神疾病的研究,加深了我们对认知健康和大脑结构和功能紊乱的理解。机器学习技术的进步已在个性化预测和表征患者的精神障碍方面显示出很大的研究希望并取得了不少进展。
这些研究利用了各种神经成像模式的特征,包括结构、功能和扩散磁共振成像数据,以及多种模式的共同估计特征,来评估异质精神障碍患者,如精神分裂症和自闭症。在本文中,作者使用术语——“predictome”(预测组)来描述从一个或多个神经成像模式中使用多变量大脑网络特征来预测精神疾病的研究模式。在预测组中,基于大脑网络的多个特征(来自相同的模式或多个模式)被纳入预测模型中,以联合估计某一疾病特有的特征并相应地预测被试的个体特征。到目前为止,已经有超过650篇关于精神疾病的经受同行评议的预测研究发表。本文调查了大约250项研究,包括精神分裂症、抑郁症、躁郁症、自闭症谱系障碍、注意力缺陷多动障碍、强迫症、社交焦虑障碍、创伤后应激障碍和物质依赖。在这篇文章中,作者全面回顾了最近基于神经影像学的预测方法、目前的趋势和常见的缺点,并分享了他们对未来的展望的方向。本文发表在Human Brain Mapping杂志上。
重点介绍:
虽然读者们可能已经读过一些机器学习和神经影像学研究的文章,但是这篇文章带来的系统性视角绝对是以往文章所无法带来的。在背景部分和第一个部分,和其他类似综述相似的是,作者介绍了当下机器学习方法和神经影响学研究的“火热”,为了把这篇文章打造成你了解和入门机器学习和影像组学方法的重要文献,我们为您在每一种方法后面都准备了该方法的网络资源去进一步了解该方法,有的比较难以理解的方法,我们附带的链接中有相应的代码实现过程,可以通过代码的一步步实现来进一步理解该方法。
接下来,作者介绍了不同疾病的预测研究概括,这里是你快速了解某个精神疾病领域研究进展的部分,你可以结合原文中的表格详细了解你感兴趣的部分。第3部分作者从医生们最关注的的临床角度出发,提出了几个重要的科研成果向临床转化的条件,可以看做是此类研究希望提升商业产品能力的方向。第4部分从不同的研究路径入手,介绍了时下最时髦的预测和分类研究,包括多体素模式识别分析、多模态融合分析以及深度学习、复杂网络和FNC、dFNC等方面的研究趋势。第5部分则开始统一分析机器学习在脑影像数据分析中面临的通用困难和挑战,这些挑战是你在做研究时必须考虑的问题。第6部分,作者对未来该领域的研究方向给出了一些猜想,这其中包括你我都能想到的深度学习、动态模型以及大数据的构建,但是机器学习竞赛在脑成像领域的开展绝对算的上时下的一个新的特征和发展趋势。并且,作者对这些趋势性的内容给出了较为详尽的优劣预测,这是你在其他地方难以看到珍贵意见。
最后,我们对全文进行了总结,思影科技希望您能从这篇文章中学到更多东西。
研究背景:
随着建立现代精神病学的不断发展,在尝试将不同的精神现象和疾病分类方面,研究者希望通过诊断工具对精神疾病进行客观评估的需求已经浮出水面。目前的严重精神障碍的临床诊断、疾病评估和治疗计划完全基于横断面自我报告的临床症状,并有纵向过程和结果的信息支持。研究人员一直在积极寻找客观的、基于生物学的疾病指标或生物标记,经过几十年的实验和尝试,根据预定义的症状类别对精神疾病进行分类,目前我们正处于一个转折点,在这个时期,出现了一种新的需要,即确立研究领域标准。这种方法的目的是结合临床和遗传神经科学的最新发现,以特定的神经病理生理学为基础的形成系统的且客观可重复的鉴别精神疾病的多维方法。通过利用先进的神经成像技术,现在有可能研究特定疾病的结构和功能脑损伤。神经成像模式,如磁共振成像(MRI)、脑磁图(MEG)和脑电图(EEG),为非侵入性地研究精神疾病的神经结构提供了重要工具,它们在各自的成像领域具有极高的准确性。利用这些强大的技术,研究人员已经开始了解可能导致特定疾病的复杂神经功能和结构。
近年来,在设计基于神经影像的预后/诊断工具方面出现了越来越多的趋势。因此,人们一直致力于使用神经成像工具来自动区分脑疾病患者与健康对照(HC)或其他患者。许多类似研究报告了有希望的预测性能,声称复杂的精神疾病可以用一种自动的方式来诊断,并且可靠、准确和迅速。然而,直到现在,这些工具还没有被整合到临床领域。作者认为一个关键的原因是,许多这类的研究,尽管在一个特定的研究数据集上出现了很有希望的结果,却没有被设计成推广到其他数据集,特别是临床数据集的标准化工具。
在本文中,作者回顾了基于机器学习的技术在精神病学诊断集中预测分析中的应用的现有文献,并讨论了当前的趋势和未来的方向。以往的相关综述总是集中在某一种具体的机器学习方法或者某种精神疾病上,而本文的目标是提供一个全面的、系统的概述。本文是迄今为止在主要精神疾病领域中最大的调查,审阅了来自各个不同精神疾病的约250篇论文。此外,近年来,预测分析研究呈指数增长,因此,一个更新的调查是很有必要的。在本文中,将对基于大脑的精神病学预测组的当前趋势及其转译观点进行一般性讨论,并强调一些常见的挑战和未来方向的指导方针。此外,本文还讨论了神经影像学的新趋势,如数据共享、多模态脑成像和鉴别诊断。本文的主要目的包括:
(a)系统地回顾和比较大量的最近的精神障碍诊断/预测研究在:MDD(抑郁症),双相情感障碍、自闭症,多动症,强迫症(OCD),社交焦虑障碍(SAD),创伤后应激障碍(PTSD)和药物依赖(SD)等疾病类型中的发展;
(b)讨论现有的机器学习技术的实际应用能力和缺陷。
(c)讨论当前该类研究存在一些问题,并从未来发展方向的角度出发来解决一些挑战。
1. 发展性精神疾病预测的研究流程
预测组研究使用神经影像学数据的目的是从一个或多个神经影像学模式中提取多变量脑网络特征,以预测结果的方法,如特定的精神疾病诊断或者病程分析。通常情况下,在特征提取和选择之后,研究人员会选择某种分类器以监督或半监督的方式使用预定义的标签集进行训练。进一步的模型验证可以通过使用独立的测试数据集或合并交叉验证(CV)方案来执行。图1展示了使用神经影像学数据进行精神疾病预测的基于大脑的预测组管道的最常见组件。虽然特定的分析流程在不同的预处理和后处理阶段可能会有所不同,但传统的预测组分析通常包括以下步骤:
(a) 特征提取和选择/缩减;
(b) (b) 分类器训练;
(c) (c) 分类和CV;
(d) (d) 模型性能评估。
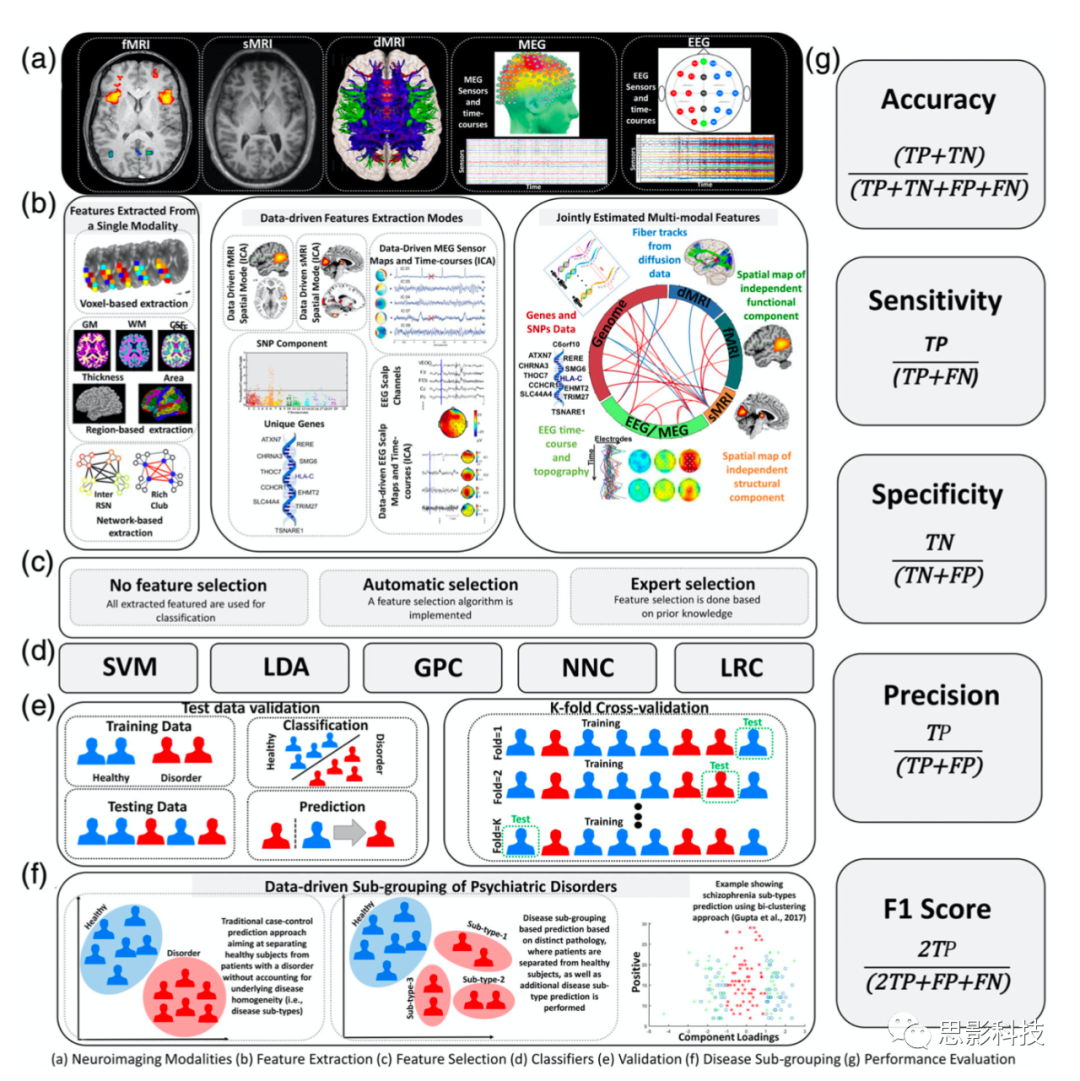
图1 一般的预测组分析的分析流程
注释:
(a) 通常用于精神疾病预测的神经影像学方法。
(b)目前的特征选择方法。特征提取可以包括:(i)基于体素的(ii)基于网络的,(iii)基于数据的方法(例如,独立成分分析,ICA),或(iv)从多种模式(例如,fMRI和基因组学)联合估计特征。
(c)特征选择的类型可以包括自动选择或专家选择方法(即顶级智能人工选取,往往基于强先验假设)。
(d)分类器的选择可以包括支持向量机(SVM)、线性判别分析(LDA)、高斯过程分类器(GPC)、神经网络分类器(NNC)或逻辑回归分类器(LRC)。
(e)可以使用测试验证设置或k-fold交叉验证方案进行模型验证。
(f)同质性疾病也可以进行数据驱动的亚型鉴定(如k-mean聚类等方法)。
(g)各种模型性能评估措施,如准确性、敏感性、特异性、预测精度和F1-score。FN,假阴性;FP,假阳性;TN,真阴性;TP,真阳性;
1.1特征提取、选择/减少
预测组分析的第一步是将神经成像数据转换为特征(即,预测组的特征,决定使用什么作为特性并从数据中提取这些特性值)。神经影像学特征是指任何包含有价值信息的派生变量,这些信息可以从数据中提取出来。在本次调查中,回顾并强调了基于用于分类目的的特征类型的预测组研究,包括基于体素、基于区域和基于脑网络的特征选择方法。
例如,特征可以是特定脑网络内的一组脑体素,或者是感兴趣区域(ROI),或者多元数据驱动(例如,使用独立成分分析[ICA])提取的脑网络,或者是联合估计多模态特征,如图1b所示。基于体素的方法在脑体素水平上进行特征提取,而基于区域的方法则根据脑图谱(功能性或结构性)识别和提取预定义的兴趣区域(roi)。基于网络的特征提取方法,如ICA,旨在跨脑网络结合多个体素的功能连接特性。
除了特征提取外,在进行模型训练之前,从高维神经成像数据中减少特征的数量也很重要。在神经成像的背景下,特征选择可以帮助实现更高的准确率,并允许更具体地关注于解释组间差异的潜在大脑区域。事实上,神经成像数据中特征的数量是很大的,许多不相关的特征对模型的预测能力没有贡献,而且并不是所有的疾病都以同样的方式影响每个大脑网络。因此,一些基于大脑的特性可能不会有助于诊断标签,而一些特性可能会捕获其他特性已经发现的冗余信息。
计算时间和模型泛化也可以通过排除冗余和不相关的特征来得到提升。特征选择方法(如主成分分析[PCA])将高维神经影像数据投影到低维空间中,目的是保持模型的识别能力。虽然不是必不可少的步骤,但为了提高预测算法的强度,选择最优和有意义的特征是很重要的。在有监督学习方法中,大多数鉴别特征被选择用来放大信号和降低噪声。通常,先验信息用于处理神经成像数据的维度问题。根据特征的特点和学习问题的类型,采用一种特定的特征选择方法。
常见的特征选择方法包括:
(a) 专家特征选择(基于先验知识)
(b) 自动特征选择(基于特征选择算法)。
这两种方法的组合也可以用于特性选择。例如,一个专家特征选择方法可以首先通过选择一个已知的特定于疾病的ROI来实现,然后一个自动的特征选择算法可以用来在预定义的ROI范围内选择有区别的特征。注意,为了避免模型性能偏差,特征选择和提取方法应该仅限于训练数据集。
1.2 分类训练器(即不同的分类算法)
分类器是一个将特征作为输入并生成类标签预测的函数。基于学习函数和基本假设,可以开发不同类型的分类器。神经影像学研究已经应用各种分类器来预测精神疾病。在应用这种分类算法时,需要考虑到特征数量相对较多、样本数量较少的维度问题。通常,分类器学习一个规则并优化地分离底层类。任何类型的分类或回归算法都可以用于训练目的,如线性和逻辑回归算法,多层神经网络和高斯方法。作者在这个部分对当前主流使用的各种分类算法进行了简要但明确的介绍。为了能够让读者在本文中获得更多的对分类算法的一般性认知,小编增加了一些内容,来帮助读者更好的了解这些方法。
最近邻方法(Nearest-neighbor)
最简单的分类器称为最近邻,它不需要对分类函数进行任何显式学习。使用最近邻方法,识别训练样本和测试样本之间最相似的测度,例如最小的欧氏距离,然后分配训练样本的标签(即最近邻)到测试样本中。在最近邻算法中,使用最频繁的是k-近邻算法,该方法的实质是:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。更通俗说一遍算法的过程就是,来了一个新的输入实例,我们算出该实例与每一个训练点的距离(距离度量方法是需要根据数据特征确定的),然后找到前k个,这k个哪个类别数最多,我们就判断新的输入实例就是哪类。
判别模型和生成模型(Discriminative and generative models)
其他需要显式学习功能的分类器可以分为判别模型和生成模型。判别分类器使用基于预定义参数的学习函数直接学习对训练数据进行预测。相比之下,生成分类器学习一个统计模型,通过对基于示例类标签的特征值的分布建模来生成类标签。
更具体的说,判别方法是由数据直接学习决策函数 或者条件概率分布作为预测的模型,即判别模型。判别方法关心的是对给定输入x ,应该预测什么样的输出y。比如说要确定一只猫是加菲猫还是狸花猫,用判别模型的方法是先从历史数据中学习到模型,然后通过提取这只猫的相应特征来预测出这只猫是加菲猫的概率,还是狸花猫的概率。常见的判别模型有线性回归、对数回归、线性判别分析、支持向量机、 boosting、条件随机场、神经网络等。

常见的生产模型有隐马尔科夫模型、朴素贝叶斯模型、高斯混合模型、 LDA、 Restricted Boltzmann Machine 等方法。
作者接下来简要的介绍了几种重要的判别模型和生成模型。
支持向量机(Support vector machine)
在监督学习的训练阶段,数据标签被用来优化模型,通过找到一个超平面或决策边界,可以最大限度地区分群体。对于一个简单的学习函数,最常见的选择是基于可能影响结果的特征的线性组合来预测类标签。线性分类器可以被看作是学习一条线或一个边界(例如,将两个类中的点分隔开并区分它们的标签。线性支持向量机(SVM)就是这样一个学习决策边界的分类器。
由于支持向量机在神经影像预测中的广泛应用和前景看好,它是目前调查中最常见的分类器。支持向量机算法通常用于二分类,其目标是在高维空间中最大化不同类之间的边界。在数学上,SVM的判别函数由一个正交于决策边界的权重向量构成,由距离决策边界最近的数据点指定,称为支持向量。这个决策边界进一步定义了未出现的新情况的分类规则。
由于SVM方法已经是业界很成熟的机器学习方法,在各个不同平台上存在大量的学习资料,我们推荐以下链接作为入门了解的良好工具: https://blog.csdn.net/v_JULY_v/article/details/7624837。
线性判别分类器(Linear discriminant classifier)
另一个强大的线性模型是线性判别分类器(LDC),它试图通过最大化类间与类内比值的方差来分离类别。概率判别模型的一个例子是逻辑回归分类器(LRC),它通过将log-odds ratio建模为预测变量的线性组合来学习最优决策规则。LDC和LRC方法都可以产生概率预测,即新案例可以分配给特定的类和类标签。我们推荐以下链接作为入门了解的良好工具: https://www.cnblogs.com/pinard/p/6244265.html。
高斯过程分类器(Gaussian process classifier)
此外,高斯过程分类器(GPC)是一种概率模型,是LRC的贝叶斯扩展。简单地说,GPC首先使用训练特征来确定区分case和control的最佳预测分布。与这个预测分布相关的参数是通过最大化训练特征的边际似然的对数来估计的。在训练阶段,GPC通过使用sigmoid函数提供测试数据的预测分布来预测病例组和控制组对象。进一步了解见:https://zhuanlan.zhihu.com/p/32152162。
神经网络分类器(Neural network classifier)
此外,人工神经网络分类器(NNC)最近成为流行的网络建模方法。多层NNC是线性感知器分类器的扩展,可以产生复杂的非线性决策边界。通常,NNC的结构包括一个输入层、一个隐藏层和一个输出层。每一层的神经元都与下一层的神经元相连。隐藏后的神经元可以使用多种非线性传递函数(如sigmoid函数)。简单地说,在训练阶段,使用反向传播技术调整一组人工连接神经元的权重,以达到学习目的,然后用于分类。
神经网络分类器的具体练习可以参考下文:
https://blog.csdn.net/HerosOfEarth/article/details/52165133
随机森林方法(Random forest)
最近其他更强大的基于大脑的预测方法包括随机森林和深度学习分类器。随机森林分类器是一个决策树分类器的集合,它集成了多个层次的随机化。利用训练数据的随机子集,生成每个决策树,然后通过搜索训练特征的随机子集形成每个节点。对于每个特征,分类器估计一个分数来突出特征的区分能力(即,基尼系数(GI)得分)。随机森林方法提供了更好的泛化准确性,因为它随机化了训练对象,特别是在训练对象相对于训练特征的数量相对较小的情况下。此外,随机森林分类器提供了非线性决策边界,这有助于在训练过程中对特征的非线性模式进行建模。MATLAB随机森林实战看下面:https://blog.csdn.net/sgfmby1994/article/details/77863297。
深度学习方法分类
最近,深度学习分类器已成为精神疾病预测的一个有吸引力的选择。深度学习分类器可以使用层次方法直接从原始数据中学习具有最佳识别能力的特征。这与需要显式特征缩减步骤的传统分类器相比具有很大的优势。通过对原始数据进行非线性转换,深度学习分类器自动克服了特征选择的问题,这对于缺乏先验知识的高维特征或数据尤其有帮助。深度学习的方法目前是机器学习中大热的发展领域,有很多的新的方法出现,也有大量的网络资料供读者学习。深度学习对使用者的数学基础有一定的要求,因此,如果你只是单纯的使用者,学会如何利用现有的工具包就可以了。就目前为止,还没有出现相当有影响力的MRI图像或者EEG数据的深度学习分类工具,感兴趣的读者可以参考斯坦福大学深度学习小组利用CNN方法对MRI图像进行分类学习的项目:https://stanfordmlgroup.github.io/projects/mrnet/。
1.3分类和CV(交叉验证)
在训练阶段,分类器根据相关学习算法从训练特征中预测标签。例如,对于没有复杂的、迭代的特征选择的学习问题,训练好的分类器在之前未见过的测试数据上进行测试。为了获得更好的模型性能,分类器应该尽可能多地使用训练数据进行训练,这在基于神经成像的预测研究中通常是一个具有挑战性的问题。CV方法为我们提供了训练更多训练样本的分类器。一种常见的CV方法是使用多个训练集和测试集分区反复评估模型性能,这种验证方法称为k-fold CV。其他流行的CV方法包括:leave-one-out (LOOCV)和hold-out。LOOCV是一个迭代过程,通常用于较小的样本容量,其中k等于样本的数量,整个样本中的每个受试者都被遗漏一次,用于测试分类器。简单地说,LOOCV过程包括以下步骤:
(a) 去掉一个样本,对其余的样本进行训练,对这个样本进行预测
(b) 依次对每个样本进行重复,
(c) 计算对所有样本进行预测的准确性。
虽然这是一种流行的选择,但将每个样本排除在外可能会增加计算代价,因为它需要训练与样本数量一样多的分类器。此外,LOOCV也被证明可能会引入一些预测偏差,因为它可能会通过在训练状态中提供更多的数据而引入高方差,这也可能导致过拟合。
因此,首选的方法是k-fold,其中k <样本数。分区的常见选择是k = 10或k = 5,这对应于在每个验证折叠期间忽略10或20%的总样本。该方法的其他重要考虑包括
(a) 为了更好的预测准确性,在训练数据中包含所有类别的例子;
(b) 各类别的样本数量大致相同(即,平衡类);
(c) 将相关样本包含在同一折中。
1.4模型性能评估
预测算法最常用的性能评估指标包括准确性、灵敏度、特异性和receiver operating characteristic (ROC)曲线。这些措施提供了一个评估分类器如何准确的推广到新的测试样本中的能力。
在临床环境中,准确性表示模型如何准确地分类病例和控制,敏感性显示正确识别的真阳性的比例(即,和特异性表明正确识别的真阴性的比例(即真实阴性的比例)。
模型的整体表现可以通过ROC曲线来评估,ROC曲线提供了曲线下面积(AUC)的总结。高敏感性表明只有少数参与者被误诊为HCs,而实际上是患者,高特异性表明少数参与者被误诊为患者,而实际上是HCs。
准确率是指样本被正确分类的总比例。ROC曲线显示了在模型的一个决策阈值范围内真实阳性率(敏感性)和假阳性率(1-特异性)之间的平衡。为了避免由于组间潜在的不平衡而产生的偏差,一种常见的做法是报告平衡的准确性度量,方法是对每个诊断进行标签。总结分类性能的一个有用的方法是提供一个混淆矩阵,它在一边表示实际的标签,在另一边表示预测的标签。从混淆矩阵中还可以提取出其他有用的性能指标,包括正预测值(PPV)、负预测值(NPV)、F1-score (precision和recall的调和均值)和G-mean (precision和recall的几何均值)。
正预测值和负预测值对于预测研究非常重要,因为它们直接量化了分类器在临床诊断中的潜在效用。正预测值定义为分类器正确预测参与者为患者的次数(即,阳性诊断)除以阳性预测的总数。负预测值定义为分类器正确预测一个负诊断的次数除以负预测值的总数。模型评估的不同指标相互之间其实连接紧密,对于解释模型性能具有重要意义,推荐: https://chiang97912.github.io/2020/01/10/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E8%AF%84%E4%BC%B0%E6%96%B9%E6%B3%95%E5%8F%8A%E4%BB%A3%E7%A0%81%E5%AE%9E%E7%8E%B0/
作为大家实战各种不同模型评估指标的文章。
2. 利用神经影像学技术预测精神疾病
随着医学影像技术的进步,神经影像数据的收集比以往任何时候都要快,分辨率也更高。近年来,越来越多的人开始关注如何利用这些海量的大脑数据,通过分析、获取方法和实验设计来更深入地了解大脑的结构和功能。在本文中,作者使用“预测组”这个术语来描述从一个或多个神经影像学模式中使用多变量大脑网络特征来预测精神疾病。在预测组中,基于大脑网络的多个特征(来自相同的模式或多个模式)被纳入预测模型中,以联合估计某一疾病特有的特征并相应地预测被试。在这个部分,作者回顾了最近用于神经影像学分类和预测的预测方法,并提供了对精神疾病预测的研究概况。
2.1对当前文献综述的调查程序的解释
目前的综述是基于对进行基于mri的精神疾病预测分析的研究文章的全面文献搜索。从1990年到2018年,系统的文献检索主要在PubMed进行,共发现550多篇文献。图2展示了本研究的系统文献搜索过程。作者搜索的精神疾病类型为8个,SZ(精分)、MDD(抑郁症)、ADHD (多动症), ASD (自闭症谱系障碍), PTSD(创伤后应激障碍)、 OCD(强迫性行为障碍)和SAD(焦虑症)以及SD(物质依赖症),以下步骤简单概括为:
(a) 不同的术语相关的分类/机器学习以及他们的缩写(例如,支持向量机,搜索术语SVM)
(b) 所有相关术语和缩略语的结构,功能和扩散磁共振成像(dMRI)结合生物标志物
(c) 术语和缩写上述八个精神疾病之一。
对所有疾病重复这些步骤,并进一步检查已确定的参考文献,以查找也包括在本综述中的遗漏出版物。另一项审查程序包括对目前审查的出版物的相关性进行审查。最后,在精神疾病诊断的病例对照设计中使用基于mri的数据预测分析方法,明确评估分类性能指标(例如,总体分类准确性)。
此外,在谷歌Scholar中重复同样的搜索过程,以减少丢失相关兴趣文章的概率。本次调查最终选择了大约250篇论文,包括:101篇SZ, 61篇MDD/BP, 35篇ADHD, 38篇ASD, 1篇PTSD, 12篇OCD, 2篇SAD和7篇SD。根据图1a- e中描述的为本文开发的方案对这些文章进行了分类,所有文章的摘要见表18(表格大大,无法全部贴出,见原文,可添加微信siyingyxf获取)。此外,作者将搜索范围限制在截至2018年12月的英文期刊文章。搜索条件还包括排除没有全文的文章,以及由相同作者发表的类似文章。对于每一项研究,定量研究成像方式、分类方法、样本量、类型特征等关键方面,如图2所示。
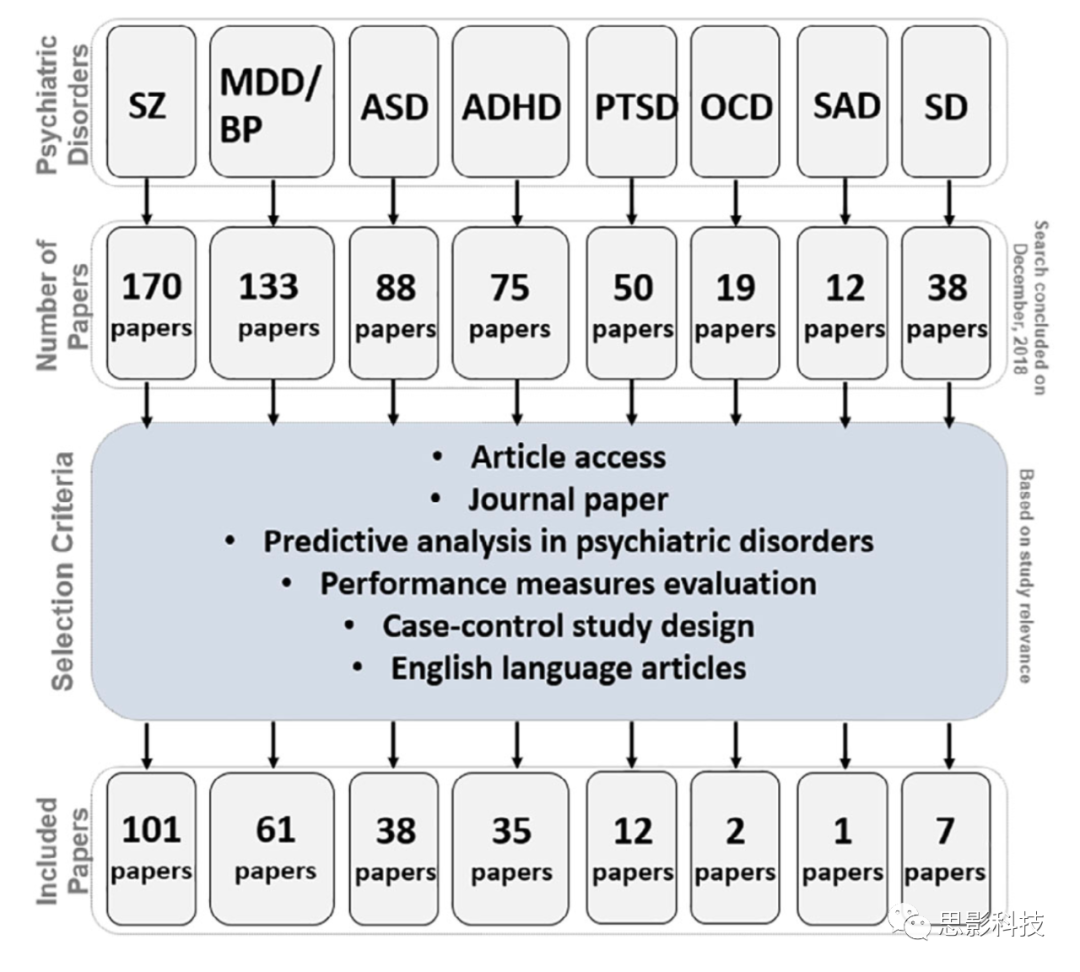
图2 文献检索流程以及对应paper数量
作者在这个部分对每种疾病的相关预测研究进行了概括性的分析。所有疾病的研究基本概括如图三所示。
2.2精分相关研究
SZ是一种慢性精神障碍,其典型特征为认知问题、对现实的感知解体、听觉和/或视觉幻觉,是一种具有持续性损伤的慢性过程。目前还没有针对SZ的标准临床诊断测试,并且已经相当多地关注于使用神经影像学特征识别生物学上的标记,这已经显示出一些希望。作者们调查了101篇同行评议的文章,如表1所示(同样见原文)。
首先来看使用结构MRI的研究: Davatzikos, Shen, et al.(2005)利用sMRI数据,使用基于体素的特征集,并应用高维非线性模式分类方法来计算SZ与HC (HC)的分离程度。使用leave-one out CV (looo -CV)作为cross validation,作者报告了81%的分类准确率(按性别分类,女性为82%,男性为85%)。Yushkevich et al.(2005)的另一项研究使用SVM分类器和基于区域的特征集来区分SZ患者,准确率为72%。最近,Koutsouleris等人(2009)使用了sMRI和主成分特征选择方法,其中基于特征选择算法的整体预测性能,确定了最优的主成分数量来预测SZ。这项研究尤其重要,因为它报告可靠地预测了SZ的不同子类别,SZ的三类别分类显示出82%的最大准确性。另一项大规模研究的样本量为256例对照以及类似规模的复制队列,预测了基于sMRI特征驱动的SZ分类模型, CV和复制研究的准确性均为70%左右。
其次是fMRI数据的预测研究:最近,大量研究使用静息状态和任务功能磁共振成像(fMRI)的特征对SZ进行预测建模,并取得了有希望的结果。
(a) 基于任务态fMRI的研究:使用基于任务的fMRI范式的特征进行的研究包括语言流畅性、工作记忆和听觉判别实验。第一个相对大规模的研究(即使用三种不同的基于任务的fMRI数据对SZ进行分类),来自两个中心的155名参与者(Demirci, Clark, Magnotta, et al., 2008)。将projection pursuit algorithm应用于ICA分离的空间地图,实现了80% ~ 90%的分类精度,其中感觉运动任务的分类精度最高。
进一步,基于区域与大的同步估计从同步血流动力学建模的听觉响应图像,Calhoun 和他的同事获得了97%的预测准确率,后来在一个新的站点的数据中的模型预测准确率高达94%。
许多精神障碍,如SZ、精神分裂情感性障碍和血压障碍,可能有大量重叠的症状、风险基因、脑功能障碍和治疗反应。因此,根据传统的诊断方法对这些患者进行临床鉴别变得非常具有挑战性。最近的一些研究探讨了SZ和分裂情感性障碍以及精神疾病的血压障碍的分类问题。Clementz和他的同事提出了一种基于生物类型的方法,他们确定了三种神经生物学上独特的生物学上定义的精神病类别,并表明生物类型并不遵循简单的疾病严重程度连续体,在不受影响的一级亲属中具有遗传特性。
(b)静息态数据研究:
用于SZ预测的rsfMRI研究包括各种分类器,如SVM、融合lasso、GraphNet、RF、C-means聚类、正则化LDC等,如表1所示。总体而言,这些研究的样本量相对较大,分类准确率在62%到100%之间,但100%准确率的研究样本量非常小(20名参与者),因此,结果可能无法在其他研究中推广。
接下来是使用dMRI数据的相关研究,本次综述中调查的dMRI研究报告的准确率在62%到96%之间,使用支持向量机、LDA和Fisher’s等分类器LDC或多个分类器的组合,这些研究的特征包括来自roi的部分各向异性(FA)图和结构连接性。
最后,Zhu, Shen, Jiang, and Liu(2014)利用多模态dMRI和sMRI数据的连通性测度对SZ患者进行预测,并取得了完美的准确性(即,100%)。然而,由于样本容量小(即, HC = 10, SZ = 10),以及该框架可能引入了分类偏差,缺乏对其他研究样本的泛化能力。
总体,现有的SZ预测组研究多以功能和结构MRI数据为特征,以looc - cv为cross validation方法选择,许多研究的样本量非常小。因此,未来有必要研究使用更好的CV方法和更小尺寸的预测模型。此外,虽然这些初步结果表明SZ可以被预测具有更高的准确性,但准确性范围在这些研究中存在很大差异,需要重复研究来确认普遍性。
2.3抑郁症(MDD)和双向情感障碍(BP)相关研究
虽然重叠的症状使得区分MDD和BP以及与其他疾病(如SZ和分裂情感障碍)具有挑战性,但最近的研究报道了对BP和MDD的成功诊断预测。本文回顾了61项使用神经影像学自动诊断BP和MDD的研究,见表2(同样见原文中的表格)。
在被调查的研究中,结构MRI主要用于预测BP患者,虽然只有少数研究包括BP样本。
因此,在推荐特定的分类器或机器学习框架作为BP预测的诊断工具之前,还需要进一步的研究。如表2所示,许多研究对MDD样本进行了分类。虽然使用rsfMRI、sMRI和基于任务的fMRI作为特征和主要支持向量机分类器来预测MDD的研究有所增加,准确率在52% - 99%之间,但在大多数研究中样本量相对较小。虽然这些研究利用了多种基于MRI的特征,如sMRI、休息和基于任务的fMRI以及dMRI,它们为基于大脑的MDD和BP的鉴别诊断提供了大量证据,但仍旧未出现泛化性能较好的分类模型。未来的研究应该采用大规模的样本量和更多的BP预测研究。
2.4 自闭症谱系障碍
ASD是一种神经发育障碍,其特征是社会交流受损、社会情感互惠的缺失、用于社会交往的非言语交际行为和刻板印象行为的缺失。自2010年以来,少数研究调查了男性和男性女性样本中ASD的自动诊断。本文调查了30篇使用基于MRI的特征进行ASD自动诊断的论文,其结果列于表3(见原文)中。
虽然这些研究利用了所有可用的MRI数据模式作为预测ASD的特征,但样本量以及基于每种模式的研究相对较少。此外,与自闭症谱系障碍相关的异质性,包括低功能和高功能患者的亚型,应该进一步使用预测模型进行研究。
2.5 多动症(ADHD)
最常见的神经发育障碍之一是多动症。然而,由于缺乏基于生物学的诊断方法,目前ADHD的诊断仅基于行为症状。在这篇综述中,调查了35篇使用基于MRI的特征进行ADHD自动诊断的论文,如表4(见原文)所示。
总体而言,这些研究和以上对自闭症以及抑郁症等方面的研究相比,在准确率方面较低,同时也存在同样的样本量较小等问题。
2.6强迫行为障碍(OCD)
目前只有少数研究将分类算法应用于OCD。本文调查了12篇关于使用基于mri的特征进行OCD自动诊断的论文,如表5所示。这些研究包括了所有模态的数据,其中也有利用多模态数据进行预测的论文,但是总体而言,发展较慢,并且同样存在样本量及泛化能力的问题。
2.7焦虑症(SAD)
到目前为止,只发表了两篇关于SAD的研究,样本相对较小,准确率在80%以上(Frick et al.,2014;Liu et al., 2015)。这些研究从不同的MRI模式中得出了多变量模式,这表明与SAD分类相关的特征可以跨模式提取和分析。这两项研究都报告说,有用的特征分布在广泛的大脑区域,而不是通常与焦虑相关的大脑局部区域。本文调查了两篇关于使用基于MRI的特征进行SAD自动诊断的论文,如表6所示。
2.8创伤后应激障碍(PTSD)
迄今为止,只有一项研究对创伤后应激障碍(PTSD)进行了鉴别分析,其中50名患有和未患有创伤后应激障碍的地震幸存者与使用结构成像的对照组进行了比较(Q Gong等,2014)。患者创伤后应激障碍的分类准确率达91%,最具鉴别性的特征出现在不同的大脑区域,尤其是左顶叶和右顶叶区域。表7给出了基于MRI特征的PTSD自动诊断的调查论文。
2.9物质依赖(SD)
到目前为止,只有少数预测研究SD(如酒精、尼古丁和可卡因成瘾)和预测治疗成功性,只有一项研究实现多通道成像方法来预测饮酒和大脑中的治疗效果,但是使用的是非人类数据(老鼠数据)。表8给出了7篇基于MRI特征的SD自动诊断的调查论文。总体而言,这些研究和以上对自闭症以及抑郁症等方面的研究相比,在准确率方面较低,同时也存在同样的样本量较小等问题。
2.10对以上调查的系统分析
图3展示了该调查的一些关键特性。图3a显示了每种疾病类型每年发表的研究数量,图3b显示了每种疾病类型每年发表的研究数量,图3c显示了每种疾病类型和每种疾病类型每年发表的研究数量。这些数据表明,自2007年以来,发表数量有了明显增长,自2010年以来,研究数量一直在快速增长。在2000年之前,只有一项ADHD预测研究,其样本量相对于最近的ADHD文章而言较低。
特别是,所有主要疾病的研究(即从2011年到2013年,美国各州(SZ、SZ、MDD/BP、ASD和ADHD)都呈现出峰值,这可能是由于最近的数据共享举措。从图3c可以看出,所有基于MRI的特征都被用来预测这些主要疾病,只有少量的多模态研究。此外,这表明结构核磁共振成像(sMRI)是最流行的模态选择,特别是在SZ研究中。对于MDD/BP、ASD和ADHD的研究,rsfMRI是最流行的模式。此外,与dMRI相比,多模态研究在这些主要疾病中更为常见。图3d显示了每种障碍分类器对常用分类器的总体预测精度,图3e显示了每种障碍分类器对每种障碍分类器的总体预测精度,图3f显示了每种障碍分类器对每种障碍分类器的总体样本量。支持向量机分类器是所有主要疾病中最常用的分类器,其次是LDA分类器。
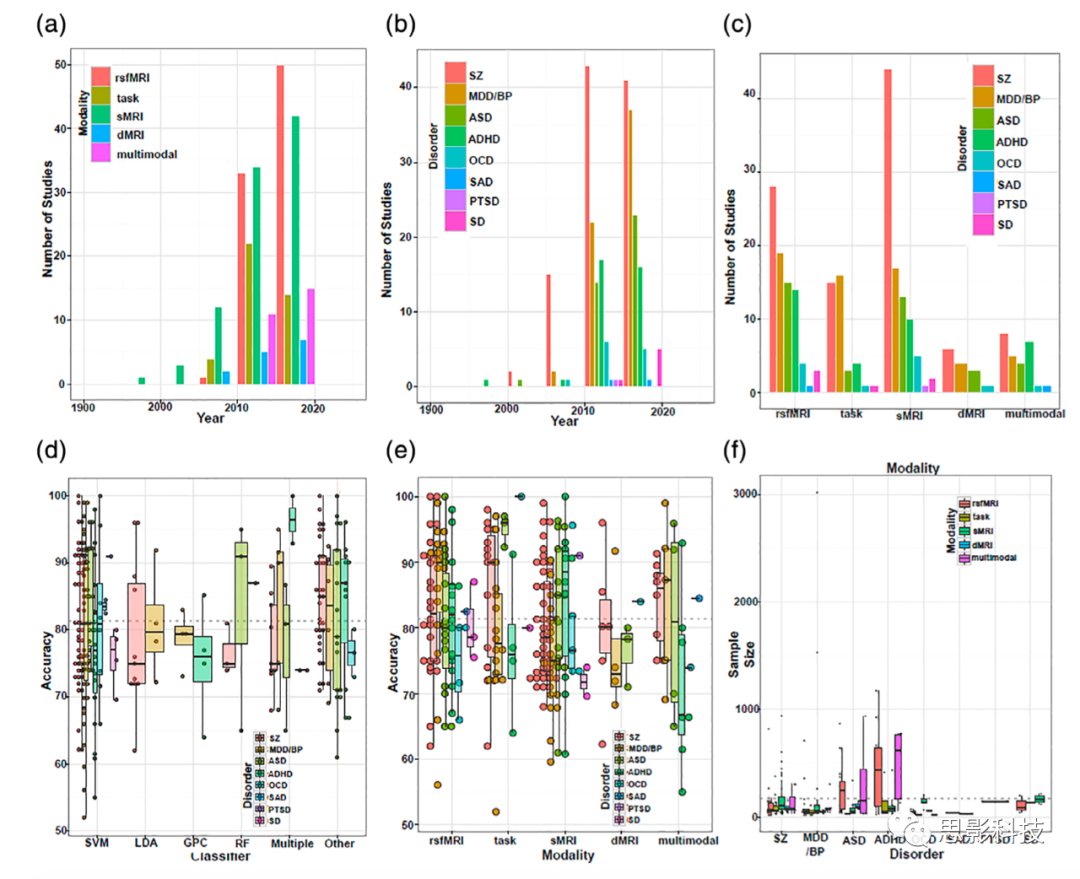
图3 本文搜集的所有文献根据MRI数据类型、疾病类型和分类模型的汇总概括
图4a显示了整体精度、总样本大小以及每个障碍和对于每一个分类器使用的研究。图4 b显示了整体精度对每个通道的总样本量和对于每一个分类器中使用的研究,图4 c显示整体精度的总样本量为每个障碍和每种模态的研究。有趣的是,即使样本量小于100,几乎所有的研究都报告了非常高的准确度,但几乎没有报告100%的分类准确度。在大多数主要疾病中,包括SZ和MDD/BP,报道的总体准确性随样本量的增加而下降,这令人担忧,因为这表明在这些小样本量研究中使用的分类框架可能无法在大规模研究中推广。此外,支持向量机分类方法,在大多数主要疾病中都能实现非常高的准确率。此外,rsfMRI和基于任务的SZ、MDD/BP和ADHDstudies均显示出较高的准确率。图4d为本次调查研究数量的样本量分布。虚线表示所有研究的平均样本量(红色)。图4e显示了针对每种障碍和研究中使用的每种分类器的每种模式的总体准确性。MDD/BP和ADHD研究报告的准确率最低。

图4 可视化总结本次调查中各种精神疾病的预测研究
根据我们的调查研究(表18),结构MRI的体积和皮质厚度,功能磁共振成像数据的ROIs或ICA组件和dMRI数据的FA之间的激活图和功能连接是最常用的分类特征。
此外,支持向量机是所有疾病研究中最常用的分类器,并观察了支持向量机方法的不同扩展,包括线性、非线性(不同的核函数)和递归特征消除支持向量机(SVM- rfe)。其他受调查的常用分类器包括LDA、高斯过程分类器(Gaussian process classifier, GPC)和随机森林(random forest, RF)。图5和图6给出了主要疾病(排除了研究数量很少的疾病)的累积密度函数(CDF)。其中, (a)每种模式的出版年份,(b)每种模式的样本量,(c)每种模式的准确性,和(d)每种分类器的准确性。从这一总结中得出的一个有趣的观察结果是,针对许多主要精神障碍的多模态预测研究出现了增长。
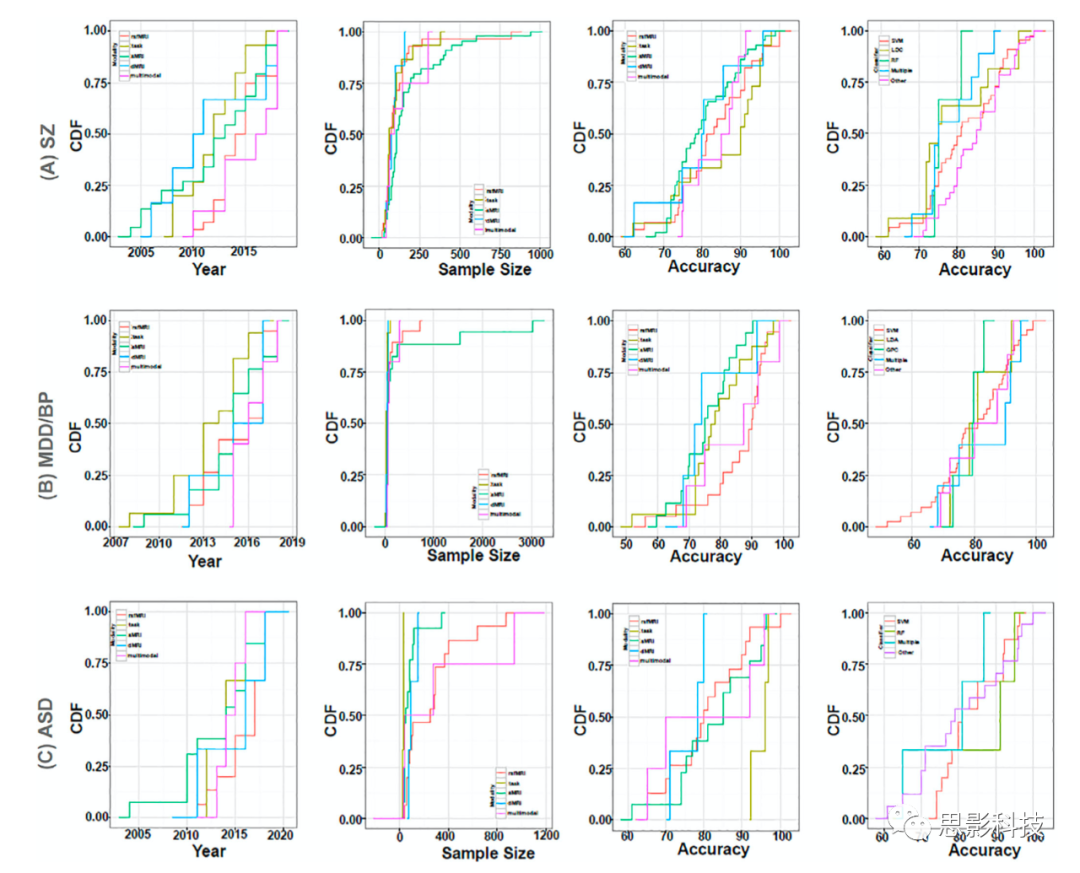
图5本次调查中精神疾病的预测研究的障碍特异性累积密度函数(CDF)的总结结果
注释:(a)精神分裂症(SZ), (b)抑郁症/双相情感障碍(MDD/BP), (c)自闭症谱系障碍(ASD)。对于每种疾病,给出了每种模式的出版年份、每种模式的样本量、每种模式的准确度和每种分类器的准确度
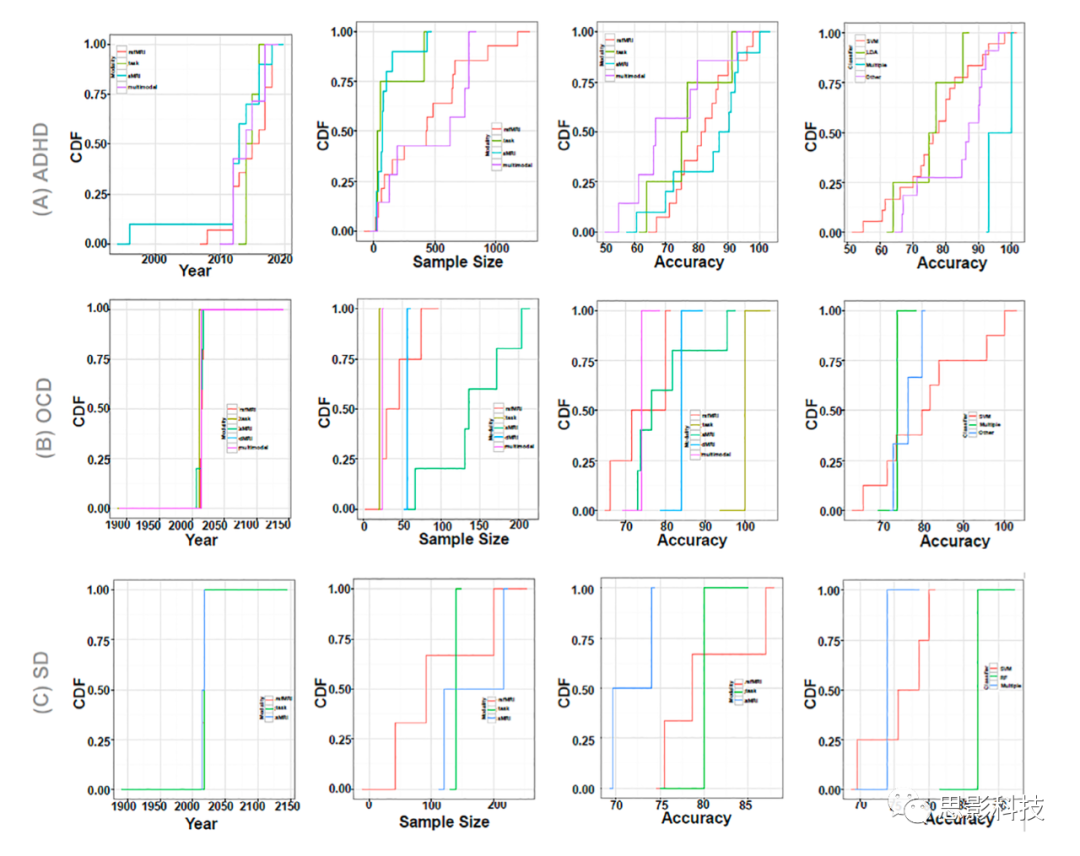
图6 本次调查中精神疾病的预测研究的障碍特异性累积密度函数(CDF)的总结结果
注释:(a)注意缺陷/多动障碍(ADHD), (b)强迫症(OCD),和(c)物质依赖(SD)。创伤后应激障碍(PTSD)和社会焦虑障碍(SAD)被排除在外,因为发表数量很少。
3. 从临床应用的转化视角看基于脑的预测组研究
3.1将预测结果转化为临床应用
通常,在以研究为基础的设置中,预测研究是使用两个或更多比例适当的精神疾病患者组和他们的健康对照组来实现的。在训练监督分类算法之前,对组标签进行仔细诊断,排除诊断不确定或共患病的受试者是一种常见做法。然而,在真实的临床人群中,疾病的诊断是一个更加复杂的过程。因此,预测建模领域需要有相当大的改进,才能将其应用于临床实践。在许多临床病例中,要解决的中心问题不像如何区分患者和对照组那么简单,而是在同一人群中不同疾病之间的具体区别(即子类型)。简单地说,在能够得到可用工具的准确临床实施之前,需要一个鉴别诊断过程。此外,目前预测建模方法的另一个限制是缺乏适当的(或任何)识别患者之间的共病的能力,这是跨多个诊断类别正确分配分类标签的关键。到目前为止,只有少数现有的研究,在目前的文献中,不同的疾病已证明多类分类(即。三种或三种以上疾病的亚型分类。然而,就本文发表截止,还没有这样的研究充分处理了共病的问题。
虽然在临床应用基于研究的诊断/预测工具之前应该解决现有的局限性,但即使是目前的方法也可以作为临床诊断的补充,虽然具有更高的决策不确定性,但可以为任何后续的医疗程序需求做出决策。除了传统的主观方法,结合精神疾病的定量预测方法可以帮助更准确的临床诊断。然而,在神经影像学预测模型的成功临床转化之前,有几个关键因素需要考虑,包括基于神经影像学的发现的可靠性和学科水平的临床过渡。此外,精神病学神经影像学研究中存在的一些空白需要解。更具体地说,预测建模的一些直接临床应用可能包括:
1、除了临床访谈外,形成基于生物标志物的诊断:目前的临床诊断主要基于临床访谈。除了现有的行为测量,预测建模结果可以提供更准确的基于大脑的内表型或生物标志物,并结合这两个测量可以提供更深入的了解生物通路,机制和疾病的进展。例如,基于大脑的ASD和ADHD的生物标记可以更客观地帮助疾病诊断。
2、多类别分类:在临床实践中,诊断具有大量重叠症状的严重精神障碍,如SZ、分裂情感性精神障碍、单极型和双极型抑郁症以及心境障碍,是非常具有挑战性的。通过获得对多个疾病类别的预测置信度的估计,预测模型可用于识别患者群体中的共病。最近的多类方法可以为每个被试的所有感兴趣的类别指定一个预测值,并能够根据预测的置信度来指示多个疾病的受试者共病情况。其他识别共病的方法包括多标签分类和multi-task learning,其中为每个样本分配多个类标签。
3、患者筛选:在进行临床操作或专家意见之前,基于神经影像学的预测结果可作为患者筛选阶段。预先使用预测模型对患者进行筛选可能会减少与临床访谈相关的时间和费用。
4、治疗反应/结果预测:除了辅助临床诊断的决策程序外,预测技术还可以用于预测治疗反应和治疗结果的预测。通过监测治疗结果和使用预测模型寻求潜在的治疗手段,临床诊断和治疗可以变得更加高效。
5、药物试验设计:基于预测模型的结果,对未来的药物反应也可以分类。通过选择最有可能对特定药物产生反应的个体的子集,可以设计更有效的药物试验。例如,对情绪稳定剂(双相)或抗抑郁药(抑郁)的反应的药物分类可以使用机器学习方法进行分类。
3.2连续测量与分类诊断
在本文中调查的大多数精神疾病预测研究都是基于为测试样本分配离散或分类标签。然而,分类诊断方法在预测某一疾病类别时忽略了连续测量,这可能导致误导的结果,或遗漏了对预测风险有用的亚临床趋势。对于更可靠的结果,使用连续测量(如模式回归)进行预测,可以成为一个有价值的工具。
此外,对于使用基于大脑特征进行精神疾病预测,基于回归的建模可以用来估计疾病的进展和治疗结果,并可以估计连续的测量指标(例如,神经精神或认知测量)。为了从神经影像学数据中估计持续的临床措施,Wang及其同事最近的一项研究提出了一个使用关联向量机(RVM)构建回归的框架,与支持向量回归类似。另一项研究探索了区域间皮质厚度相关性,以识别和表征自闭症诊断观察表评分。这项研究的结果表明,多个大脑网络之间的结构协方差测量与自闭症症状有关。
此外,Tognin及其同事基于脑灰质体积和皮质厚度测量,使用相关向量回归预测精神病高危人群的正、负综合征量表得分。最近,研究开始预测健康和疾病的连续评估措施(例如,研究领域标准[RDoC];T. Insel et al., 2010)。这些研究表明,除了进行分类诊断外,还可以通过使用连续的疾病预测措施来取得有希望的结果。
除此以外,作者还分别讨论了疾病患病的风险预测和治疗结果的预测,但是相关研究目前还较为缺乏。虽然这类研究在临床转化上具有非常重要的意义和转化价值,但目前还没有出现类似的模型显示出较好的预测能力。
4. 基于大脑的预测组的当前研究趋势
4.1单变量和多变量方法
近年来,各种多变量神经影像学分析方法的方法学发展受到越来越多的关注,因为它们能够检验除体素和单变量技术之外的其他特征。对于单变量功能性神经成像方法,通常在每个体素的时间过程中独立拟合预期反应变量的模型,然后使用实验条件下的估计反应水平进行进一步的测试。虽然方便,但这种方法引入了大量的统计测试,因为它只针对与特定刺激相关的特定大脑位置(即大脑活动区域),从而产生反应的统计差异图。也因此,它限制了对大脑区域间刺激无关关系(如功能连接)的研究。此外,单变量方法不允许在多个大脑位置估计刺激效果。多变量神经成像方法考虑了大脑活动在多个空间位置同时发生的整个空间模式,能够探测到单变量方法无法捕捉到的大脑活动的细微但局部的测量。与传统的单变量、基于模型的方法缺乏直接处理体素/区域间相互作用的能力相比,多体素模式方法估计了跨脑区域激活的相关性或协方差。多变量结果也可以更可靠地转换为底层大脑网络的特征。最近的多元神经影像学方法提供了分析刺激和同时测量的许多位置的反应之间的关系,如空间反应模式或多体素反应模式。与单变量技术相比,多变量方法可能提供更强大的统计能力和更好的重现性。
在基于神经影像的诊断中,多变量机器学习方法同时整合可用的特征来联合区分不同的组。通常,对于多变量机器学习方法,分类器在一个训练数据集上进行训练,以预测不同的类别(例如,患者组),然后应用于测试数据集。通过LOOCV以提高模型准确性。到目前为止,已有多种多变量机器学习方法在基于神经图像的预测中得到了应用,如SVM、k近邻(k-nearest neighbor, KNN)、高斯朴素贝叶斯(Gaussian Naive Bayes, GNB)和LDA等。在这些分类器中,基于svm的分类器获得了更好的分类性能。
其他最近和更有效的分类器包括:随机森林(Breiman, 2001),深度学习(图7给出了一个深度学习用来分类的例子)与人工神经网络分类器。多变量机器学习方法用于精神疾病诊断的例子包括使用结构MRI数据对SZ进行分类,分类精度从81%到93%。
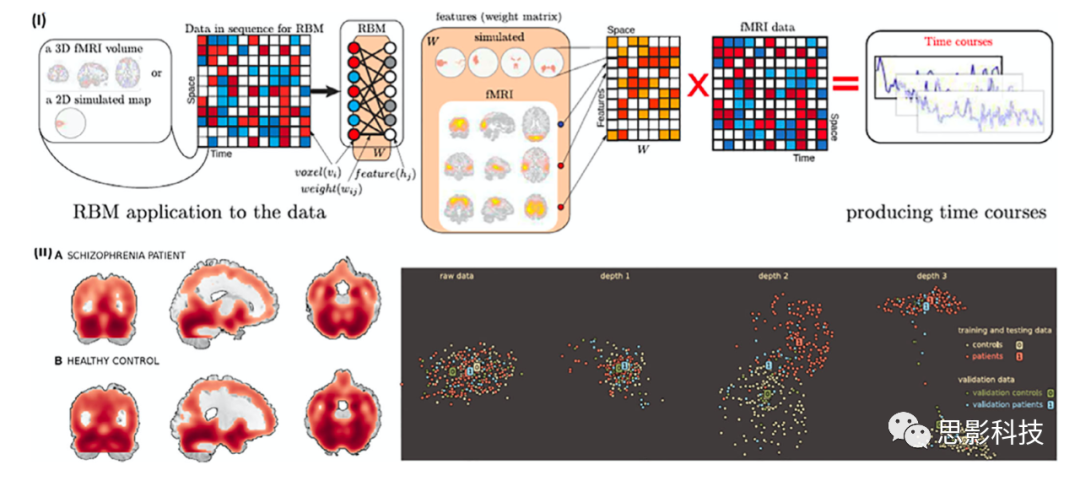
图7 精神分裂症预测的深度学习方法。
注释:(I)基于受限玻尔兹曼机(RBM)的深度学习处理流程的方法,特征是从fMRI数据的timecourse中获得的。
(II)展示精神分裂症患者训练样本和健康对照的平滑灰质分割的例子(左图),以及深度信念网络(DBN)深度对邻域关系的影响(右图)。结果显示,在深度1和深度2之后,DBN继续提取使两类数据进一步分离的细节。(Plis et al.2014)
深度信念网络是一种深层的概率有向图模型,其图结构由多层的节点构成。网络的最底层为可观测变量,其它层节点都为隐变量。最顶部的连接是无向的,其他层之间的连接是有向的。它的目的主要在获取可观测变量下,推断未知变量的状态,并调整隐藏状态以尽可能重构出可观测数据。
4.2多模态研究
虽然神经影像学技术已经成为鉴定精神疾病相关生物标记物的流行工具,但每种影像学技术都有其局限性。通过开发多模态神经成像技术,结合从多种神经成像技术(如脑电图、结构磁共振成像(sMRI)和fMRI)获得的数据,可以部分克服特定模式的局限性,这比单模态神经成像方法在大脑结构和动态方面提供更丰富和可靠的结果。
多模态神经影像学是一个相对较新的和迅速扩展的领域,它整合了来自不同模式的数据,以了解精神疾病的病理生理学。例如,通过将基因组变异与大脑功能、结构和连接测量相联系,成像基因组学方法可以描述基因组变异影响精神疾病认知和行为的潜在神经机制。多模态数据融合方法利用两种数据模式的互补信息,通过考虑模态间的关系来共同估计它们之间的关联。特别是,对于复杂的疾病,如SZ,通过合并先进的多模态建模提供的额外信息,可以更好地理解来自多种模式的特征之间的关系。因此,在对精神疾病进行预测建模时,研究多模态神经影像学数据以及非影像学特征(如行为和基因组数据)之间的相互关系非常重要。
正如Calhoun和Sui(2016)所述,目前有多种方法集成从各种单模态成像技术获得的数据。主要的方法是两种:一种是利用某一模态数据约束另一模态数据,如MRI数据约束EEG数据的源重建方法。另一种模态的独立成分分析的联合分析,如联合独立成分分析(joint- independent component analysis, joint- ica)或平行独立成分分析(parallel- ica)。
虽然现有文献中的大多数研究使用单一的模式来预测精神疾病,但最近数据融合方法的发展使得多模式神经成像成为一种流行趋势。最近的几项研究通过结合rs-fMRI或基于任务的fMRI数据,以及sMRI,将SZ患者与HC区分开来Cabral et al., 2016; J. Ford, Shen, Makedon, Flashman, & Saykin, 2002;Qureshi, Oh, Cho, Jo, & Lee, 2017; Yang, He, & Zhong, 2016)。
还有fMRI与单核苷酸多态性结合(SNP;基因组功能;Yang et al., 2010),以及rs-fMRI和MEG (Cetin et al., 2016,图八)数据的结合,而只有少数研究结合了来自三个或更多模式的数据(Sui et al.,2013;Sui et al., 2014),精度为75% - 100%。
其他最近的数据融合进展包括集成多个基于任务的fMRI数据集(D. I. Kim et al., 2010; Sui, Adali,Pearlson, & Calhoun, 2009; Sui et al., 2015),与传统的基于线性模型的方法相比,该方法在更大程度上指定了共同和特定的活动来源。
Ford和同事使用Fisher的线性判别分类器,基于任务fMRI数据对SZ和HC进行分类,准确率为78%,sMRI数据准确率为52%,而组合的多模态数据(fMRI和sMRI)的准确率最高为87% (J. Ford et al., 2002)。
Yang和同事最近的另一项多模态神经成像研究整合了利用ICA提取的基于rs-fMRI的连接特征和基于sMRI的结构特征,并使用SVM分类器比较单模态和多模态的准确性(Yang, Chen, et al.,2016)。研究结果表明,多模态特征的识别正确率(77.91%)高于单一模态特征(72.09%)。Cabral和同事使用多模态sMRI和rs-fMRI数据对SZ患者和HC个体进行了75%正确率的分类,其中基于多模态特征的分类优于基于单模态特征的预测准确性(使用sMRI数据的准确率为69.7%,使用rs-fMRI数据的准确率为70.5%);Cabral et al,2016)。Qureshi和他的同事使用类似的方法对SZ患者和HC个体进行分类,使用rs-fMRI和sMRI联合数据,但样本数量更高,并实现了10×10倍嵌套交叉验证预测精度99.29% (Qureshi, Oh, Cho, et al., 2017)。
需要注意的是,为了尽可能多的使用训练数据,克服样本容量的问题,该框架使用了一个没有新数据的嵌套CV进行测试,这可能会引入分类偏差,导致预测精度如此之高。尽管存在方法上的局限性,但这些研究和其他研究显示了利用多模态成像数据的潜力。然而,在临床应用之前,还需要更可靠的多模态融合方法和验证。除此以外,基于ICA的方法在多模态融合预测方面取得了很好的效果。 虽然在大多数当前的样本容量有限数据集使得预测研究仍旧具有很大的挑战性,但是我们可以看到这种希望是在不断提升的。
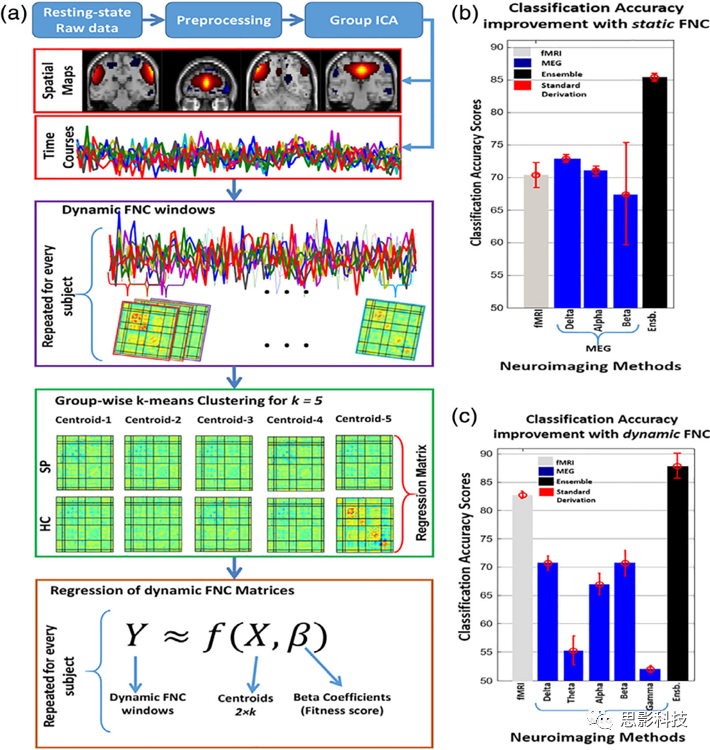
图八 MEG-fMRI分类框架的示意图。
(a) 静息态fMRI和MEG数据均采用组ICA、多窗fnc和k-means聚类方法。对动态FNC测量进行回归分析,提取特征。
(b) 用静态FNC方法显示平均分类精度提高的条形图。
(c) 动态FNC方法平均分类精度提高的条形图。动态方法明显优于静态FNC方法。(Cetin et al,2016)
4.3 疾病亚型的多分类研究,对减少疾病异质性的探索
虽然对精神疾病患者与对照组分类的诊断方法已在现有的精神疾病预测文献中成功实施,但它并没有解决精神疾病预测的鉴别诊断方面(即,区分症状重叠的疾病或亚组诊断)。传统的病例对照模型忽略了疾病组内部的异质性,将预定的病例或对照标签分配给测试样本。许多严重的精神疾病,如SZ、分裂情感性障碍、单极型和双极型抑郁症以及其他情感障碍都有大量重叠的症状,因此仅根据所报告的症状进行疾病预测不足以准确诊断。为了解决这个问题,美国国家心理健康研究所引入了研究领域标准(RDoC;(http://www.nimh.nih.gov/research-funding/rdoc),这是一种根据多种症状、行为和生物学维度对精神疾病进行分类的方法,目的是减少诊断组之间的异质性。
与《欧洲精神健康研究路线图》(Schumann et al.,2014)一致,RDoC在神经生物学层面提供了改进的分类验证。大多数针对RDoC项目的研究都采用了各种基于神经心理学测量的数据驱动的聚类方法来划分临床人群。这些研究包括SZ亚型诊断(Bell, Corbera, Johannesen, Fiszdon,& Wexler, 2011;Brodersen et al.,2014),情感障碍亚型(Lamers et al., 2010;Van Loo, De Jonge, Romeijn, Kessler, & Schoevers, 2012)和ADHD 亚型(Dias et al., 2015;d.a. Fair, Bathula, Nikolas, & Nigg, 2012;Koutsouleris et al,2015;van Hulst, De Zeeuw, & Durston, 2015)。
如上所述,传统病例控制预测的主要局限性之一是二元疾病特征,即将测试样本指定为病例或控制类别。这种方法忽略了相关的疾病异质性,通常称为疾病亚型。然而,包括自闭症和SZ在内的许多异质性精神疾病被定义为谱系障碍(即在同一诊断类别下有多种疾病病因)。虽然使用泛型分类来寻找诊断生物标志物是一种常见的做法,但精神疾病诊断过程中的一个主要问题是缺乏对多个疾病亚型患者的鉴别诊断。
疾病亚型的准确诊断对于合适的治疗过程至关重要。例如,在SZ病例中,患者可以表现出类似的认知缺陷,但程度不同。因此,为了强调SZ的表型异质性,本文引入了两个具有不同遗传和认知特征的主要亚型:(a)认知缺陷(cognitive deficit)和(b)认知幸免(cognitive) (Green et al.,2013;Jablensky, 2006)。然而,由于样本量有限,SZ亚型的鉴别诊断研究较少。
在大多数现有的数据集中,每种疾病亚型的受试者数量都很少,这限制了开发可靠的亚型预测器来准确区分它们的能力。已有研究中,Ingalhalikar和他的同事提出了一种无监督的频谱聚类方法,利用来自78个ROI之间的结构连接网络的多边图来对自闭症和SZ的亚型进行分类(Ingalhalikar et al., 2012)。
在本文的调查研究中,只有少数重要领域出现了自动鉴别诊断亚型的研究。Costafreda和他的同事使用功能磁共振成像(fMRI)对SZ、双极型和HCs进行了分类(Costafreda et al.,2011)。Calhoun et al.(2008)(图9)和Arribas et al.(2010)的两项研究使用功能磁共振成像(fMRI)进行听觉辨别任务,其中他们应用ICA方法提取默认网络相关特征和大脑的颞叶听觉网络。这两项研究均获得了SZ与BP障碍之间较高的预测精度。
Rashid及其同事提出了基于静态和动态功能网络连接(FNC)特征的算法(图10),对来自动SZ、双向情感障碍和HC进行分类(Rashid et al., 2016)。Pardo和他的同事的另一项研究使用了来自结构MRI的23个ROIs和22个神经生理测试分数的组合,用于SZ、BP和HCs的自动分类(Pardo et al., 2006)。也出现了一些其他的方法,但是在大多数当前的样本容量有限数据集中,执行疾病亚型预测的被试数量在每个疾病中样本很小,这为此类研究带来了很大的挑战性。

图9 使用颞叶听觉网络和默认网络成分预测精神分裂症(SZ)和双相情感障碍(BP)
注释:(a)分组平均的颞叶听觉网络和(b)默认网络成分,从健康对照(HC)、SZ和BP患者的fMRI数据中提取。组水平单T,p<0.001,校正后。(c)分类结果说明了先验决策区域,以及被试的实际诊断。平均敏感性和特异性分别为90和95%。(Calhoun et al,2008)
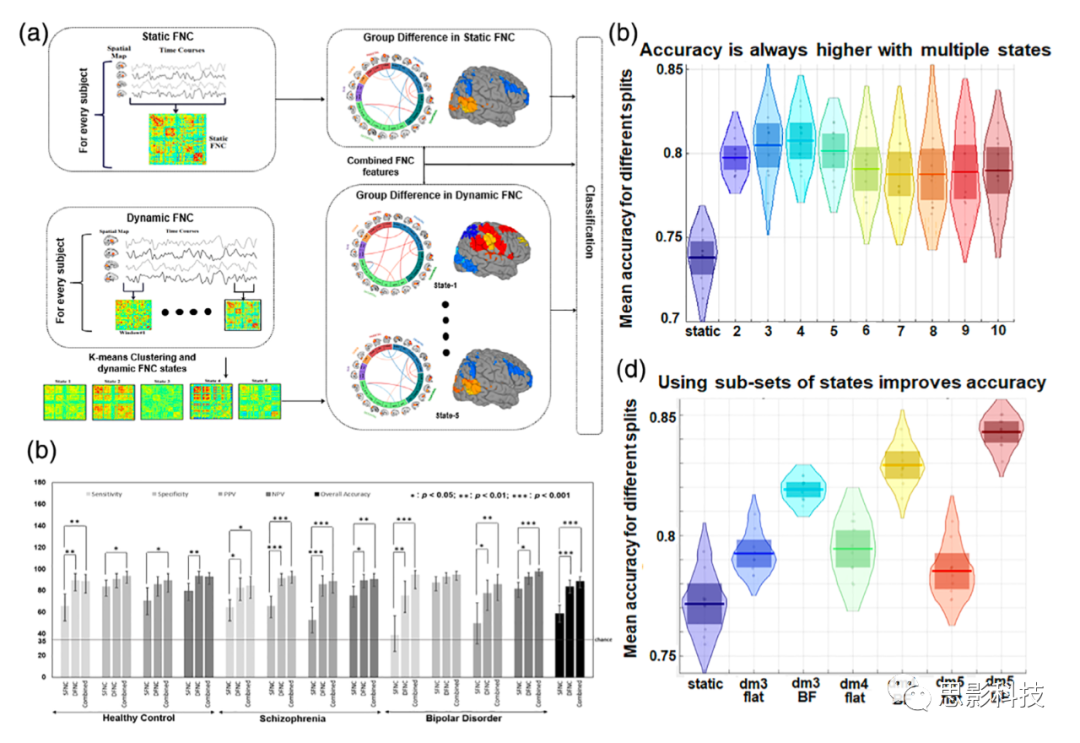
图10 采用静态和动态FNC的分类方法
注释:(a)采用加窗FNC和k-means聚类方法提取精神分裂症(SZ)、双相情感障碍(BP)和健康对照(HC)的动态FNC特征。
(b) 分类结果显示,动态FNC方法优于静态FNC框架(准确率分别为84%和59%)。
(c) 另一种基于FNC的方法显示动态FNC方法明显优于静态FNC方法(Saha et al., 2019, ISBI)。利用多个动态聚类k值(k = 2 -10)评价分类性能。
(d)此外,使用状态子集对性能进行了评估,显示了状态子集的准确性的提高(Saha et al,2019,ohbm)。图片来自,Rashidet al. (2016), Saha, Abrol, et al. (2019), and Saha, Damaraju, et al. (2019)。
4.4进阶的基于大脑数据的预测算法
最近,一些更先进的机器学习算法已经显示出基于神经成像的精神疾病预测的巨大潜力。例如,最近的一项研究提出了一种新的基于ICA的平行分析框架,联合估计SZ中功能网络可变性和结构共变之间的关联,并基于这些相关的功能/结构特征预测几个认知域得分(Qi et al., 2019;图11)。
简而言之,通过将fMRI(提取自组ICA)的时域特征与并行组ICA算法中的结构MRI特征相结合并进行估计,通过联合估计功能网络变异性和结构共变,以识别模态间联系。利用真实的神经成像数据,确定了一个重要的功能和结构MRI组件对,在两种成像模式中均捕获组差异,这进一步与认知得分相关,表明多模态大脑特征可以预测多个认知得分。

图11 一种基于并行方法的group ICA + ICA的精神分裂症联合预测估计方法
注释:提取fMRI (a)和sMRI (b)特征,采用并行GICA+ICA (c)进行特征集成,从GICA中提取组级组件(d),然后从个被试中提取GICA组件(e),在组水平结构协变网络中提取ICA组件(f),最后进行FNC分析。Qi et al.(2019)
SZ最近的另一项研究提出了一种多位点典型相关分析与联合ICA(MCCAR+jICA)相结合的多模态融合算法,在三种模态数据融合(fMRI、sMRI和dMRI)中对被试的个体特征变量(具体为工作记忆性能)进行预测,识别多模态共变的特征模式(Qi et al.,2018)。结果发现,在SZ中,有几个大脑区域以前与工作记忆缺陷有关,这表明新的MCCAR+jICA方法在识别严重精神疾病的生物标志物方面有很大的潜力,例如SZ。
此外,Sui和同事在SZ中采用了约束融合的方法来预测认知能力(Sui et al.,2015;图12)。认知评估采用MATRICS Consensus Cognitive Battery (MCCB)进行测量,使用多组典型相关分析,探讨MCCB与静息fMRI低频波动分幅(fALFF)测量的脑功能异常、结构MRI的灰质密度(GM)、dMRI的FA之间的联系。这项研究的结果表明,相关的功能和结构缺陷可能与SZ的认知障碍有关。除此以外,还有多项基于其他开发的ICA算法和多模态数据融合的方法进行预测的研究,这些方法都提出了不同的多模态融合研究的框架,读者可以对原文中的参考文献进一步阅读以获取相关方法的实现过程。
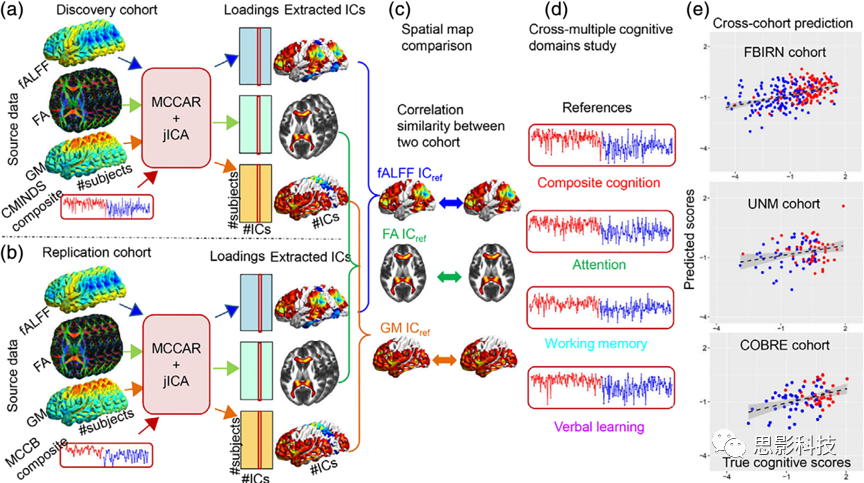
图12 使用MCCAR+jICA方法预测认知
注释:文章使用了一种基于约束的数据融合的认知预测方法。a和b部分展示了作者对不同站点数据的多模态数据的融合分析,c为多组间多模态共变模式的抽取,d为多模态共变模式对复合认知的预测比较,综合认知得分作为多站点数据群组的预测对象。e为预测得分(Sui et al ,2018)
4.5 基于大脑数据预测的功能连接测量方法
近年来,利用神经影像学研究大脑连通性已经成为研究大脑网络之间联系的热门方法。功能连通性(FC)可以使用各种不同的神经成像技术进行量化。一种常用的测量方法是fMRI,它通过血液氧合来测量同步的大脑活动,并推断不同大脑区域之间的功能相互作用(Craddock et al.,2013)。FC被定义为大脑空间距离区域之间的时间相关性(或其他类型的统计相关性)(K. Friston, 2002),最近被用于研究这些大脑空间距离区域之间的功能组织和时间相关性。不同的分析工具已经被应用于静息态fMRI数据来描述脑功能连接。两种广泛使用的FC方法是(a)基于种子的分析和(b)纯数据驱动的方法,如ICA 。还可以使用空间ICA在网络级别上研究FC,空间组件之间的连接称为FNC。在大多数情况下,FC(以及FNC)在整个扫描期间被认为是静止的,正式称为sFC/sFNC分析。
由于FC分析产生的高维特征,如果没有有效而有意义的特征选择,分类器可能会引入过拟合问题,导致分类性能较差。因此,为了消除冗余特征,只选择FC度量中合适的特征,应用合适的特征选择策略至关重要。对于基于FC的特征选择,采用了特征过滤等方法来实现特征维度的压缩(例如LASSO等方法),如图13中的研究。
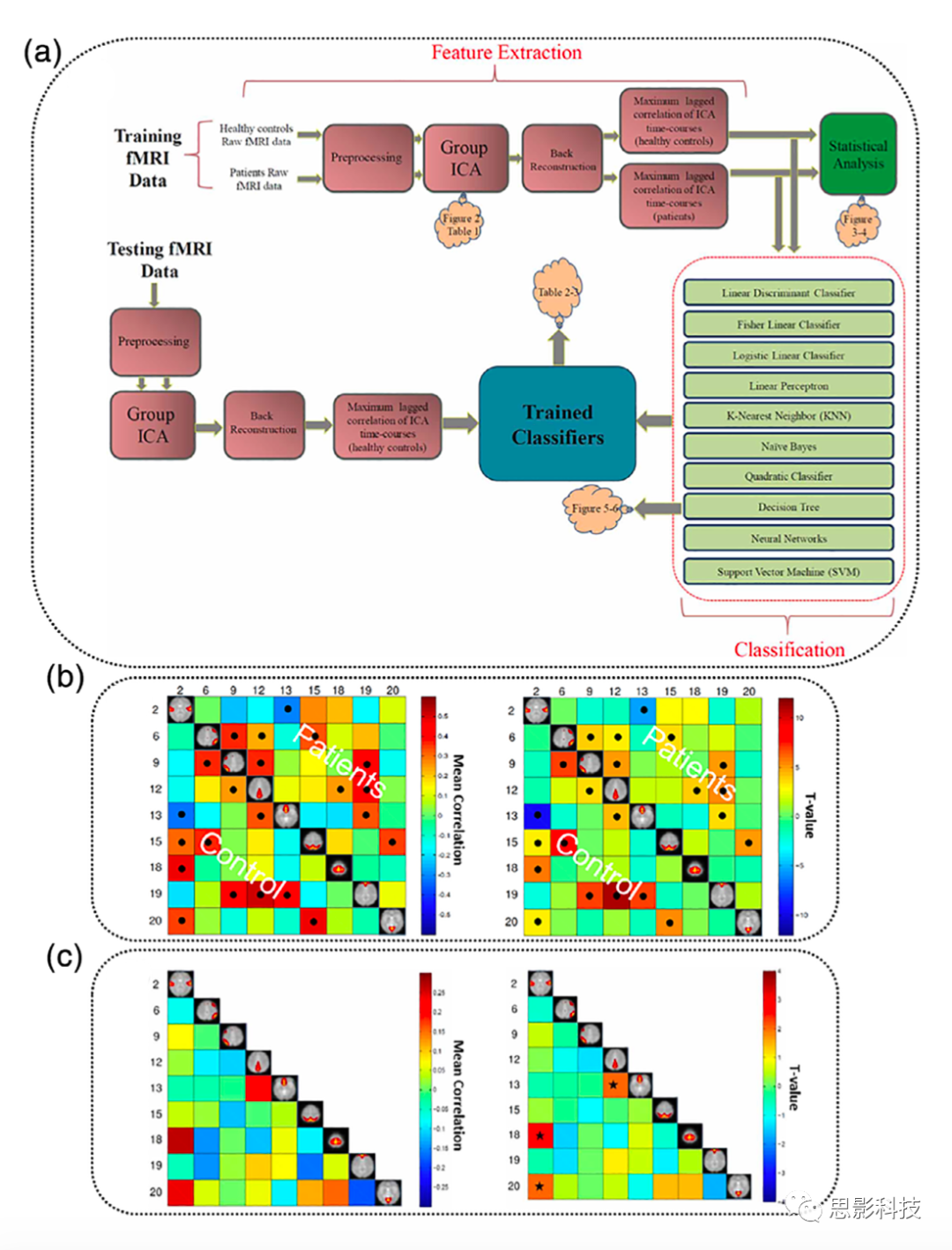
图13 利用静息状态功能网络连接(FNC)对精神分裂症(SZ)进行分类的方法
注释:(a)基于fnc的框架的特征提取和分类步骤,这篇文章中利用了多个不同的方法来对ICA成分进行降维从而选取特征,也利用了多个模型来评估分类器的训练效果。
(b) 组内平均FNC(左)和T值(FDR校正后,p<. 05)(右)。
(c) 组间平均FNC测量值(左)和FDR校正值(p <0.05,T值显示组间差异)。Arbabshirani et al. (2013)
表9(见原文)给出了基于FNC的SZ、MDD/BP、ASD和ADHD患者自动诊断的分类研究。FC和FNC措施均已用于被试水平的诊断(即严重的精神疾病,如SZ和双相情感障碍。例如,通过使用大脑功能网络之间的连接。
另一个基于不同图谱识别出的ROIs之间的FC矩阵的方法也被用来区分SZ和健康个体,并且有不少研究以此方法获得了较好的分类表现。此外,Bassett等(2012)使用高级网络组织作为SZ分类的特征,准确率达到75%。除了基于单一模态的FNC特征外,研究还探索了将FC与其他模式的特征融合来对SZ进行分类。例如,Yang和他的同事开发了一种混合机器学习方法,使用fMRI(体素和ICA网络)和SNP特征对SZ进行分类,这种组合特征包括了体素、ICA网络和SNP数据;Yang et al.,2010)。
虽然少有研究对具有重叠症状的精神疾病进行分类,如SZ、分裂情感性障碍和伴有精神病的BP障,但也有研究在这方面取得了进步。Du及其同事利用GIG-ICA提取静息状态脑网络,将SZ患者、伴有精神病的BP障碍、伴有躁狂发作的分裂情感性障碍、伴有抑郁发作的分裂情感性障碍和健康个体进行分类(Du et al., 2015)。采用RFE方法选择FNC特征,采用五类SVM分类器进行训练,分类准确率达到68.75%(图14)。
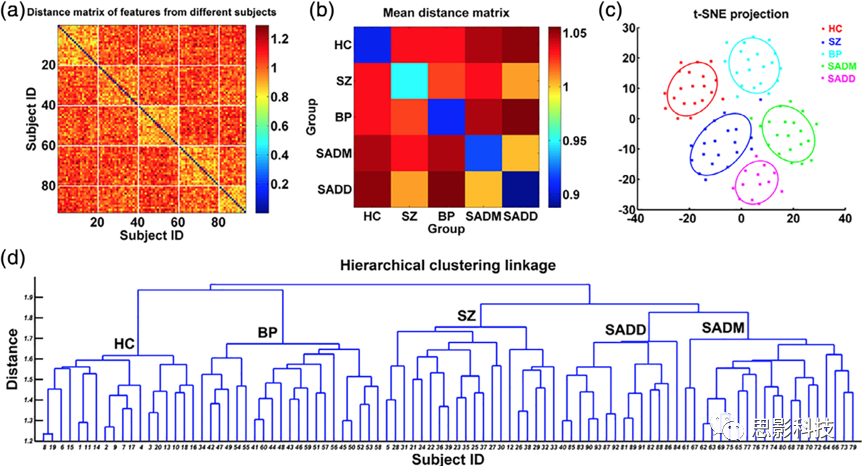
图14 一个使用网络测量和层次聚类预测精神分裂症和双相情感障碍的例子。
注释:(a)距离特征向量的距离矩阵。
(c) 组间和组内平均距离矩阵。
(d) 显示被试投影结果的t-distributed random neighbor embedded (t-SNE)方法的结果,其中每个点都指向一个受试者(group-wise colored)。
(e) 层次聚类方法的结果。SADM:情感分裂症(躁狂型),SADD伴有抑郁发作的分裂情感性障碍。
FC测量也被用来作为自闭症和多动症的分类特征。使用来自7266 ROI的静息状态FC测量(应用灰质mask限定分析区域),Anderson和他的同事在20岁以上的受试者中达到89%的准确率,在所有受试者中达到79% 正确率(J. S. Anderson et al., 2011)。Murdaugh和他的同事在logistic回归分类器中使用了基于种子的FC和全脑FC来对自闭症进行分类,并报道了96.3%的全脑和基于种子的FC特征的准确性(Murdaugh et al., 2012)。
此外,Plitt和他的同事使用了三个来自于ABIDE数据集的ROI之间的FC,应用基于RFI的特征选择以及logistic回归和支持向量机分类器对自闭症进行分类,总体准确率达到了76.7% (Plitt et al., 2015)。在自闭症多模态分类研究中,Deshpande及其同事使用FC和分数各向异性(来自DTI数据),使用基于递归聚类消除的SVM分类器获得了最大分类准确率95.9% (Deshpande et al.,2013)。 最近的另一项基于rest -state fcbased (between 90 ROIs)预测研究使用深度学习分类器(probabilistic neural network, PNN)对ASD进行分类,分类准确率约为90% (Iidaka, 2015)。有趣的是,在最近的ASD分类研究中,不同频段的信号之间的FC被用作特征,其中Slow-4波段(0.027 - 0.073 Hz)被发现捕捉到最具鉴别性的特征(H. Chen et al., 2016)。
此外,通过利用一个大规模静息态fMRI研究,对多个站点的SZ和健康对照组进行分类,该研究提出了一种基于ICA的预处理流程,以提取FNC和基于空间地图的成像特征作为潜在的生物标志物。结果表明,与基于FNC的特征相比,空间地图在所有实验中都表现出更好的分类性能(Lin et al., 2019)。另一项研究提出了一种稳健的基于群体信息引导的ICA (GIG-ICA)的框架,用于评估不同疾病和独立研究之间的神经标志物之间的功能网络图和连接性,其中的连接性度量是独立计算和优化的,以实现基于每个即将到来的个体受试者数据的独立性。本研究结果表明,使用该方法计算的网络特征在预测不同疾病和分类患者方面更有效(Y. Du et al., 2019)。这个框架的优点之一是它不需要选择感兴趣的组件,并且可以完全自动化(图15)。
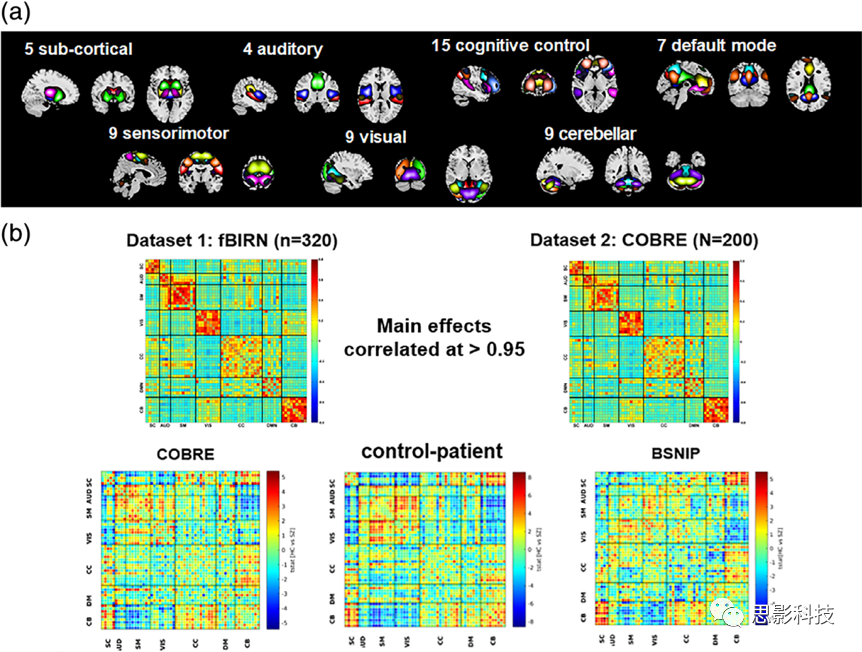
图15神经标记方法旨在连接不同疾病和独立研究之间的神经标记
注释:(a)发现完全自动化的组水平ICA非常稳定,可用于个别被试的ICA成分的提取。
(b)功能网络连通性(FNC)在多个位点的数据之间具有很强的相关性(r>0.95),不同站点的分裂症(SZ)和健康人群之间存在一致的组间差异。Y. Du et al. (2019) and Lin et al. (2018)
5. 基于脑影像数据预测组研究的共同缺陷
在这个部分,作者分析了脑影像数据预测组研究的6个共同缺陷,但是虽然作者使用short comings 这样的说法,小编认为,这些特性与其说是缺陷,不如说是机器学习方法中的挑战在面对复杂的、高维的大脑数据时遇到了更大的困难,它们分别是:
①特征的选择和缩减
②过拟合问题
③最优模型选择
④可重复性问题
⑤不同研究预测结果一致性
⑥患者之间的异质性
在这6个问题中,作者重点对特征选择问题、不同研究结果一致性问题和患者之间的异质性问题进行了论述。
精神疾病预测研究的一个重要局限性是对有意义特征的选择和降维。在这篇综述中,几乎所有被调查的论文都是先进行组级判别分析,再进行被试的对象分类。许多这类研究首先使用统计测试(例如,t测试)进行鉴别分析,以提取显示组间差异的显著特征,然后使用这些特征进行被试水平分类。然而,在特征选择、提取或约简过程中,测试数据集和训练数据集的使用会给预测模型带来额外的偏差。
基于从整个样本中识别出的群体差异结果进行特征选择的过程可能会导致双重倾斜问题,这可能会导致偏差性能。基于组差异的特征选择方法的另一个主要问题是,基于组差异的特征选择方法的另一个主要问题是显著性水平是基于统计检验的p值,而p值不一定与模型的区分能力线性相关。基于单变量组级统计测试的特征选择的另一种解决方案是使用过滤和主成分抽取的方法,过滤方法如LASSO方法等通过减少贡献值低的特征来优化特征选择,主成分抽取如PCA方法通过提取方差变异贡献最大的成分来作为特征向量。这些方法在机器学习中面临着的挑战并不是只有面对脑影像数据时才存在,但是高维的脑影像数据以及其信噪比等问题缺失加剧了该类问题。
除此以外,在预测研究中,一个常见的做法是将总体精度作为最终的模型性能度量。虽然许多被调查的研究报告说,他们的算法比其他现有的研究表现得更好,但这种说法往往是未经证实的,而且仅仅是基于他们的总体准确性与现有研究之间的比较。没有很好匹配的研究变量(即,样本大小,年龄,性别,扫描仪参数和成像序列,药物,症状评分,数据形式,扫描功能数据的长度,预处理流程,感兴趣的特征,特征选择方法,分类器类型,CV方案),但是,就目前为止,对这些进行不同研究间的比较是完全不切实际的。此外,任何与表现相关的声明都必须经过适当的统计显著性检验。
基于神经影像学的机器学习研究的另一个局限性是患者之间存在实质性的异质性。在以研究为基础的神经影像学研究中,被试是根据匹配的年龄、性别或教育背景招募的,通常具有特定类型的脑病理学。相比之下,在临床环境中招募的被试可能包括几种病理类型,这些病理类型在疾病阶段和人口统计变量(即年龄、性别等)上存在很大的异质性。如前所述,使用更大的训练样本可以提高分类性能(例如,准确性)(Franke et al., 2010;Kloppel et al., 2008),也可能通过整合整个临床和病理特征的频谱来减少疾病的异质性。最近的方法,如离群点检测(即离群点检测),将患者分类作为离群点检测问题处理(Mour~ao-Miranda et al., 2011),可以减少患者间较高的异质性。此外,最近的两项研究进行了多成分和症状双聚类,其中沿着不同维度的同质聚类为SZ亚型(图16)。这些方法都提高了对被试异质性问题的解决能力,但就目前为止,该问题仍旧是此类研究的一个重大问题。
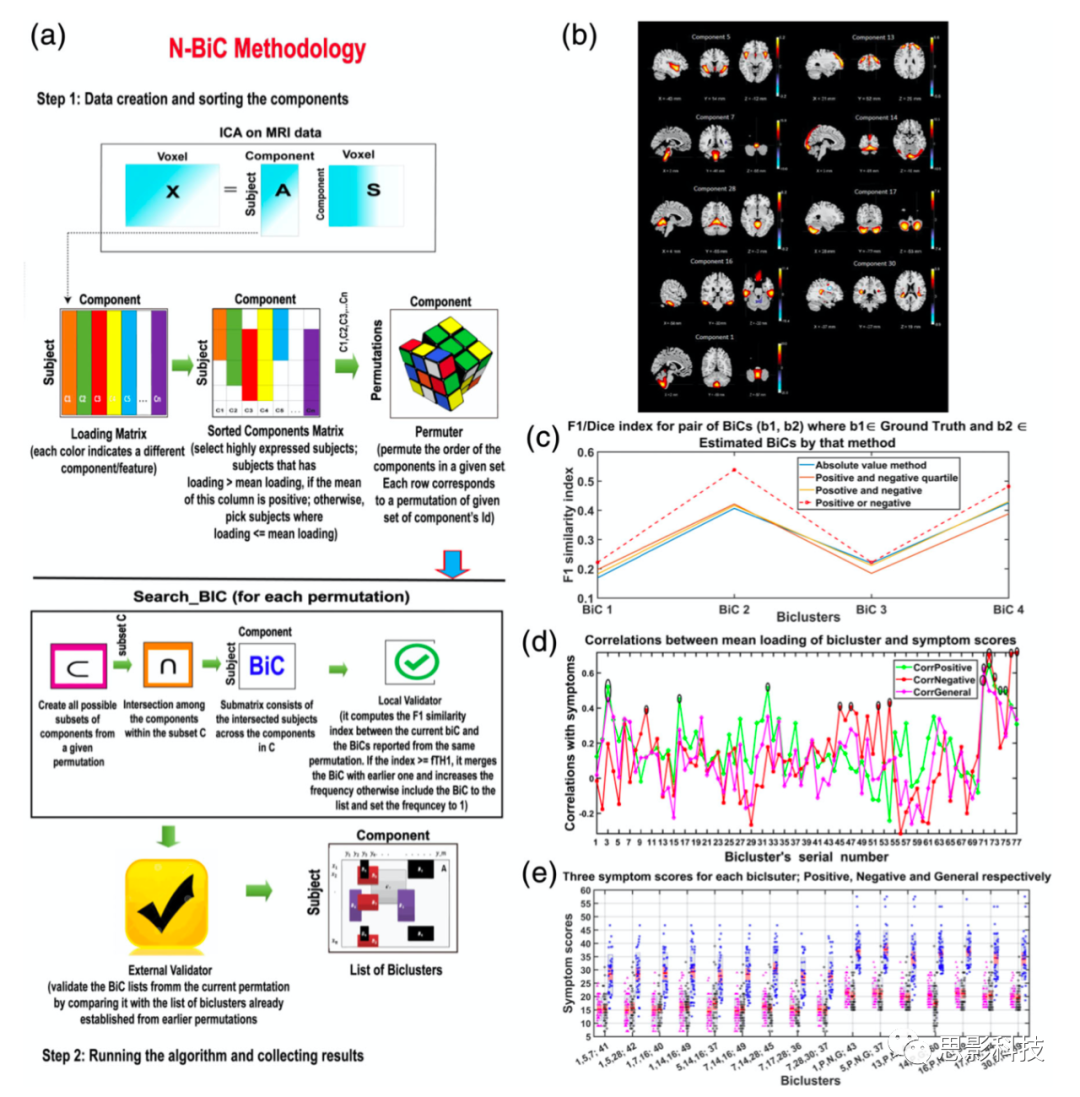
图16 一种基于多成分和症状聚类的精神分裂症(SZ)预测方法
注释:(a)研究总框架的流程示意。
(b) 以加载参数为特征的判别元件。
(c) F1索引图表示模型估计值和真值之间的相似度指数,值越高表示相似度越高(估计越好)。红色虚线表示该方法优于其他方法。
(d) 症状评分与双量表的相关性。颜色代表不同的症状分数;高的峰值表明显著的相关性。
(e) 两组患者症状得分的平均值和标准差。这些点代表了主观的症状评分。红色:积极的分数;黑色:负分数;蓝色:一般的分数。
6.利用脑影像数据对疾病预测的预测组分析的未来发展方向
6.1使用深度学习技术进行预测
近年来,深度学习作为机器学习技术的一个分支,在包括神经影像学在内的各种数据分析领域的模式识别和分类得到了广泛的关注。传统机器学习与深度学习的根本区别在于,深度学习能够利用连续的非线性变换,从原始数据中发现并学习复杂的模式。基于数据驱动的自动特征学习过程,深度学习能够识别复杂和微妙的(可能是非线性的)模式,因此它最近成为精神疾病神经影像学研究的一个有吸引力的工具。
基于深度学习的方法在检查大量特征时更有效,而在特征选择方面没有任何先验的知识需要。使用非线性层的分层模型,深度学习可以建模更复杂的数据模式。使用深度学习,主要的优点超过传统的机器学习方法包括:
(a) 能够实现数据驱动的自动功能相关的学习和消除主观性特征选择
(b) 深度模型设计,包括非线性层的层次结构,允许模型有效地识别复杂的数据模式。通过从高维神经成像数据中提取复杂的、隐藏的模式,深度学习为理解精神疾病的神经基础提供了一个有希望的工具(Kriegeskorte, 2015)。深度模型有多个优点,包括需要指数较少的参数来建模与传统机器学习方法的模型相同的东西(Bengio, 2012)。此外,对于更大的神经成像数据集,深度学习为更有效地诊断精神疾病提供了机会。就目前为止,深度学习方法已经在预测组研究中表现出了很强的潜力,除了前文中提到的使用深度信念网络研究的方法以外,另一项多模态数据集成研究开发了一个神经网络框架来研究大脑发育。简而言之,该研究提出了深度协作学习(deep collaborative learning, DCL)方法,考察不同年龄组之间功能连接测度的差异,最大预测准确率约为98% (W. Hu, Cai, Zhang, Calhoun,& Wang, 2019)。
但同样的,深度学习方法也存在一些方法上的通用局限性,包括:
1) 深度学习技术高度依赖于训练数据的质量和数量,这可能导致过度拟合(即过度拟合)。,学习数据中不相关的变化),可能反过来导致缺乏普遍性。为了解决过拟合问题,深度学习方法中加入了诸如正则化策略(如L1或L2规范、辍学和权重衰减)等方法。
2) 深度学习技术需要大量的训练数据来识别更广义的特征和提高性能,因此在样本容量较小的情况下表现较差。此外,即使增加样本量(如ImageNet),噪声影响较大的神经成像数据可能也不能提高模型的线性方法之外的性能。这个问题的一个解决方案是使用特定类型的低噪声特性来训练模型。
3)深度学习模型提供了一个类似黑盒的系统,它可能会在学习和测试步骤中引入缺乏透明性的问题。在许多情况下,理解模型的技术和逻辑基础是非常困难的。深度学习缺乏透明度可能会限制神经影像学结果的可解释性。事实上,深层模型的多重非线性使得追踪到原始大脑数据的连续权重层变得困难,因此限制了检测大脑区域异常的能力。
4) 深度学习方法的另一个挑战性问题是工作流程的集成开发,特别是这些模型的临床应用。为了在临床环境中实现这些深度模型,有必要与临床医生分享这些模型的相关知识,并在模型开发阶段作为最终用户接受他们的反馈。
6.2大型数据样本的收集问题
在精神疾病预测研究领域最常见的观察局限性是有限的样本量。缺乏更大的数据集(即以及临床记录、共病、症状和疾病进展、治疗结果和反应等表型细节的不足,限制了利用机器学习算法开发精神疾病个性化护理的范围。本综述中大部分预测研究的样本量都相对较小。尽管样本量是一种常见的限制所有预测研究中,相对于其他使用机器学习的研究领域,由于招募的困难病人和收集的数据的成本问题,神经影像学研究一般非常小的样本容量。这可能会引入几个问题,包括分类器性能下降(Franke et al.,2010;Kloppel et al. 2009),缺乏诊断目的的泛化,无法处理疾病异质性,以及由于样本量不足导致的模型过拟合(Pereira et al., 2009)。对于机器学习方法的最优评估,需要更大的样本量来最小化准确性、敏感性、特异性和其他性能度量评估的方差。
为了解决神经影像学研究的这一局限性,多个正在进行的工作创建了数据存储库。大规模或大数据革命有望减少神经影像学研究中的数据异质性相关问题(Franke et al., 2010;Kloppel et al,2008)。虽然大多数现有的神经影像学研究由样本大小适中,通常小于50个样本,一些数量的研究已开始接受神经影像学的大数据,收集成千上万的对象或利用巨大数量的增加成像和非成象特性收集项目清单上的每一个项目。目前,存在三种类型的大数据计划:(a)集中的,(b)分散的数据共享存储库,和(c)大规模的研究。
其中,集中的大数据计划有:
①NIMH data archive: The Adolescent Brain Cognitive DevelopmentStudy (ABCD) (Casey et al., 2018).
②NITRC: For SZ, ASD, and ADHD (Buccigrossi et al., 2008).
③COINS: Collaborative Informatics and Neuroimaging Suite or COINS for ASD patients (https://coins.mrn.org/).
作者这里并未全举,其实在HCP(https://www.humanconnectome.org/)大型数据项目中,有多个大型的大数据计划正在或者已经进行。
分散的数据共享存储库有COINSTAC: a decentralized and privacy-enabled infrastructure model for brain imaging data (Gazula et al., 2018; Plis et al., 2016).,以及如果你想获取更多的相关信息,可以查看Ming et al. (2017).的文章。
大规模的研究数据贡献项目有:
1. FBIRN: For SZ patients (J. M. Ford et al., 2008).
2.COBRE: For SZ patients (center of biomedical research excellence,http://cobre.mrn.org/).
3. MCIC: For SZ patients (Gollub et al., 2013).
4. Functional Connectomes Project: For healthy subjects (B. B. Biswalet al., 2010).
5 . ABIDE: For ASD patients (Di Martino et al., 2014).6.ADHD-200: For children with ADHD (Consortium & others, 2012).
以及参见(Milham et al., 2018)的文章获取更多信息。
大数据研究除了数据收集的问题以外,还面临着统计和计算模型方面的更多困难。首先,在不同贡献站点之间数据获取和处理的不一致性可能会在使用汇集的多站点数据时引入预测建模的性能偏差。对于大规模成像研究,有几个潜在的人为因素值得关注,这些人为因素可能包括影响成像和其他变量的因素,如(a)头部运动,(b)头部大小,(c)心率和呼吸变化,(d)扫描仪硬件的变异性,和(e)扫描仪硬件的变异性。
其次是统计方面的挑战。这些丰富的数据集旨在探索各种假设。随着研究者对多种成像模式的研究,他们中的许多人倾向于探索不同的替代模型来寻找意义,而没有适当的多重比较测试或CV框架。这使得CV和复制变得更加重要。同样,效果大小也应该被报告,如果使用零假设检验,大数据可以为微小的效果大小提供非常显著的结果,这可能对任何单独的受试者都不是特别有用。此外,使用鲁棒的测试统计数据也很重要,例如,非参数测试(如基于排列的测试)的使用可以在检查多种模式时合并使用。该问题目前已经被很多研究者关注到,近日发表在Nature(Variability in the analysis of a single neuroimaging dataset by many teams)的来自70多个团队的大型重复研究已经使该问题的严峻性受到了更多研究的关注。
再次,大数据带来了维数的诅咒。与观测量相比,高维数据具有许多特点,容易受到稀疏性、多线性、计算量、模型复杂性和过拟合等问题的影响。一种可能的解决方案是在分析和建模数据之前实现特征选择或减少方法,例如主成分分析。
最后,通过大数据联盟共享神经成像数据已经引起了一些伦理和隐私方面的担忧,例如,从结构图像重建面部的可能性。通过在数据共享之前使用de-facing方法删除可识别的面部特征,这个问题可能会得到解决。其他伦理问题包括基于受试者地理位置的受试者识别风险,因为这些大规模研究通常是在特定区域内进行的。通过采用多层、受限的数据共享方法,可以实现对完整数据集的更多受控访问,从而消除被试主体识别的风险。
6.3 神经影像领域的标准机器学习竞赛
在机器学习领域,最近基于标准预测分析的竞赛已经大大促进了技术的发展。这种比赛的典型布局包括:
(a) 为参与者提供一个标签的训练数据集和一个标记测试数据集,基于训练数据集
(b) ,参与者试图开发一个最佳性能预测模型,然后应用训练模型来预测测试样品标签
(c) 最后,参与者提交预测结果和性能。
通过使用这些竞赛提供的标准训练集和测试数据集以及一些基本的预处理,参赛者可以专注于预测建模方面,而不会产生任何有偏见的结果。但在神经影像学领域,由于数据共享政策的限制,这类竞赛并不像其他领域那样常见,但近年来已经举办了一些基于大脑的机器学习竞赛。
2011年,ADHD-200竞赛举办,包括静止状态fMRI数据,以及776名被试的(491名典型发育儿童和285名ADHD)的解剖数据,用于训练集,197名被试作为测试数据集(Consortium &,2012年),目的是区分多动症患者和健康的、正常发展的儿童。本次竞赛显示了多站点、大规模ADHD数据共享的更大前景。
另一个最近的机器学习竞赛是由IEEE MLSP研讨会组织的,该研讨会只提供基于神经成像的特征,目标是自动预测来自HCs的SZ患者(Silva et al.,2014)。简而言之,研究人员向参与者提供了静息态fMRI的FNC测量,以及144名受试者(75名hc患者和69名SZ患者)的结构性MRI的SBM测量的ICA成分。比赛共有245支参赛队伍参加,优胜队伍的AUC约为0.90。综合前三种模型,AUC约为0.94 (Silva et al., 2014)。
此外,在2018年,结构MRI数据预测MDD和HC的竞赛也出现了(https://www.photai.com/pac)。该竞赛包括来自759名抑郁症患者和1033名HCs的训练数据,以及来自3个不同站点的448名被试的未标记测试数据。获奖者的分类准确率达到了65%。这些标准的机器学习竞赛显示了基于大脑的精神疾病预测的潜力,因为它们能够以准确、无偏倚的预测能力评估数据。随着竞赛的不断开展,基于脑影像数据的预测组研究的方法部分将得到快速的提升。
6.4 利用动态连接分析方法的优势
直到最近,功能连接性一直被认为在扫描时间(通常是几分钟)内是相对稳定的。虽然便于分析和解释,但最近几项研究(Sakoglu et al., 2010)以及侧重于时频分析方法的研究和其他几项研究深入研究了综合时间线索使用动态连通性特征识别生物标志物方面的成功应用。这些研究报告发现,大脑功能的连通性可以在短时间内发生变化(比如几十秒),并可以成功地捕捉到疾病人群中连通性中断的情况。
但是,只有少数研究利用动态大脑连接特征来预测精神疾病。利用静态和动态连接特性,Rashid和同事开发了一个分类框架来预测SZ、躁郁症和健康被试(Rashid et al.,2016)。使用10折交叉验证框架,比较了静态、动态、静态和动态联合连通特征的分类性能。结果表明,动态FNC(分类精度:84.28%)显著优于静态FNC(分类精度:59.12%),说明功能连接中的动态模式可能比静态FNC提供更清晰、更丰富的信息。另一项研究使用了一种新的递归神经网络(RNN)方法。来测量大脑网络之间的时间动态和依赖关系(X.-H.Wang, Jiao, & Li, 2018)。另一项研究使用SVM分类器和LOOCV/10-fold CV对ADHD儿童进行分类,数据来自ADHD-200项目。具体地说,内在连通性网络与人口统计和协变量之间的时间变异性被用作特征。LOOCV的总准确率达到了78.75,而10倍CVs的平均预测准确率达到了75.54% ,证明了使用时间动力学和SVM分类器对ADHD的准确预测。这些研究都说明,在未来的研究中,利用动态功能连接的特性可能可以更加有效的提升模型的分类表现。
6.5动态连接和其他数据类型的融合
从fMRI数据估计的动态FNC测量可以进一步与其他数据类型和模式融合分析,例如,基因组和结构MRI数据,以利用基于模式间的特征进行疾病表征。在一个新的成像基因组框架中,Rashid和他的同事最近建立了动态FNC状态和基因组特征之间的关联模型,以检测SZ相关的内部异常(Rashid等人,2019;图17)。 具体而言,采用并行ICA算法(J. Liu et al.,2009)对遗传变异进行组合(即使用滑动窗口和聚类方法从动态FNC数据中揭示功能核磁共振数据的功能特征(Allen et al., 014;Rashid等人,2014),以用来区分SZ与健康个体。结果发现,在SZ中,SNP组成部分和动态FNC组成部分之间存在显著相关性。

图17 一个图像基因组学框架,联合评估精神分裂症(SZ)和健康对照组(HC)的群体差异
注释:基于并行ICA的多模态框架融合了成像(动态FNC测量)和基因组(单核苷酸多态性,SNP)数据。
总结:
本文针对最近基于大脑神经影像数据的精神疾病预测研究进行了系统且角度详尽的综述,尽管由于样本量小,一些结果需要进一步验证,但总体而言我们已经可以看到希望。文章介绍了许多先进的已经开发和应用于精神疾病预测领域的算法,但也指出这些方法仍存在许多具有挑战性的问题,必须在应用于临床之前进一步解决。
在这项工作中,本文全面回顾了现有的基于大脑的预测研究在几种精神疾病,如SZ,抑郁症、ASD、ADHD、SAD、OCD、PTSD和物质障碍。本文不仅对各种应用于该领域的模型方法进行了简要的介绍,并且还进行了总体的评价。
文章指出,对该领域的一个主要挑战是预测表征精神疾病的表型异质性。虽然最近的方法已经开始处理疾病亚型,但仍旧有很多挑战。另一个主要挑战是大多数研究报告的样本量相对较小。如果没有更鲁棒的验证,这些结果在应用于独立数据集时的泛化程度还不清楚。然而,最近的数据共享计划已经开始通过提供足够的数据来开发更鲁棒和改进的预测模型来改进样本容量问题。作者还敏锐的提出了大型的模型竞赛给该领域将带来更多的客观收益和较大的进步。这是与其他类似综述一个不一样的想法。
本文提到的基于深度学习、复杂网络和动态连接特性的dFNC网络等方法,可以通过识别复杂和异质的基于大脑影响数据的疾病模式,可以更好地实现预测建模。这些方法可以潜在地用于临床更个性化的药物,针对具有不同症状和疾病进展的疾病的特定亚型或集群。但目前为止,这些临床上的转化只能通过整合临床和技术专业知识来实现,可能通过两个领域的专家之间的一些来回反馈系统来实现,直到自动的评估工具被优化,并简化为临床应用。最后,我们希望基于大脑的预测组研究能够超越分类诊断,并考虑一些关键的连续测量的变量,如认知和行为,以提供一个全面的诊断方法。
如需原文及补充材料请加思影科技微信:siyingyxf 或者18983979082(杨晓飞)获取,如对思影课程感兴趣也可加此微信号咨询。觉得有帮助,给个转发,或许身边的朋友正需要。

微信扫码或者长按选择识别关注思影
非常感谢转发支持与推荐
欢迎浏览思影的数据处理业务及课程介绍。(请直接点击下文文字即可浏览思影科技所有的课程,欢迎添加微信号siyingyxf或189839798082(杨晓飞)进行咨询,所有课程均开放报名,受疫情影响部分课程时间有调整,报名后我们会第一时间联系,并保留已报名学员名额):
磁共振脑影像结构班(预报名)
弥散磁共振成像数据处理提高班(预报名)
小动物磁共振脑影像数据处理班(预报名)
更新通知:第十届脑影像机器学习班(已确定)
更新通知:第十九届脑电数据处理中级班(已确定)
更新通知:第二十届脑电数据处理中级班(已确定)
脑电信号数据处理提高班(预报名)
脑磁图(MEG)数据处理学习班
眼动数据处理班(预报名)
近红外脑功能数据处理班(预报名)
数据处理业务介绍:
思影科技功能磁共振(fMRI)数据处理业务
思影科技弥散加权成像(DWI/dMRI)数据处理
思影科技脑结构磁共振成像数据处理业务(T1)
思影科技啮齿类动物(大小鼠)神经影像数据处理业务
思影数据处理业务三:ASL数据处理
思影数据处理业务四:EEG/ERP数据处理
思影科技脑电机器学习数据处理业务
思影数据处理服务五:近红外脑功能数据处理
思影数据处理服务六:脑磁图(MEG)数据处理
招聘及产品:
招聘:脑影像数据处理工程师(重庆&南京)
BIOSEMI脑电系统介绍
目镜式功能磁共振刺激系统介绍