

深度学习是一种主要使用卷积神经网络架构的机器学习形式,从最初的计算机视觉应用,到现在越来越多地应用于医学影像,该方法显示出了巨大的潜力。由于典型研究中获取到大量且丰富的多模态成像信息,因此,神经放射学领域有望成为深度学习的早期采用者。目前,深度学习的研究应用已经获得广泛关注,在未来,其应用很可能会快速增长。本文描述了深度学习的原理,概述了用于训练和测试深度学习模型的基本方法,并简要介绍了深度学习目前在神经放射学上的(潜在)应用。本文重点关注深度学习在未来如何改变神经放射学,神经影像学研究人员和临床医生对这些方法能够熟练掌握,对引导和利用深度学习方法的应用具有重要意义。
深度学习是人工智能的一种形式,它大致模仿了大脑中神经元的结构。在解决计算机视觉、自然语言处理和机器人技术方面的问题上均展现出巨大潜力。由于理论的进步、可用性的提高以及计算能力的提升、软硬件的融合,近年来,深度学习已经成为机器学习的主要形式。目前,在深度学习领域令人兴奋的是,其在各种各样的目标任务中都有出色表现。比如,机器学习性能的一个基准是ImageNet挑战。在这个一年一度的比赛中,参赛队伍要将数百万张图片分成不同的类别(几十种不同的狗、鱼、汽车等等)。而2012年正是一个分水岭,当时第一个基于神经网络的参赛作品以巨大的优势击败了竞争对手,并超越前几年的成绩。从那以后,每一个获奖作品都使用了深度学习框架。现在,深度学习在分类精度等方面的表现已经超过了人类。
深度学习有彻底改变整个行业的潜力,包括医学成像领域。鉴于神经影像学在神经疾病的诊断和治疗中的中心地位,深度学习可能首先对神经放射科医生产生深远的影响。本文将介绍深度学习方法,概述其目前的应用成功案例,并对这些方法在神经放射学应用的未来发展进行展望。
在人工智能的背景下,思考深度学习究竟适用在什么地方,这对理解深度学习概念来说是很有用的(图1)。人工智能是一种计算机方法,这些方法可以完成需要人类智慧才能执行的任务。机器学习是人工智能的一种类型,它开发的算法使得计算机无需显式编程就能从现有数据中进行学习,例如聚类、Logistic回归和支持向量机等分类算法。
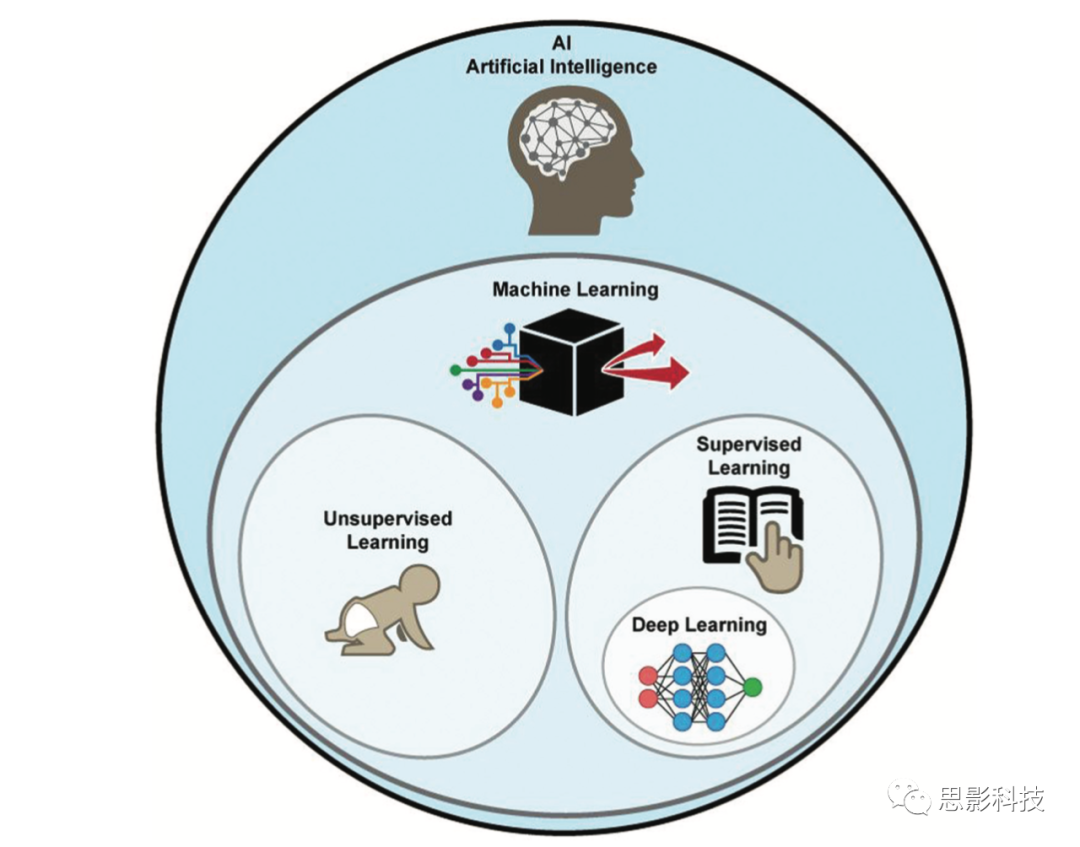
图1 人工智能方法。在机器学习方法的子集中,深度学习通常被实现为一种监督学习的形式。
机器学习方法可以进一步分为有监督学习和无监督学习。在有监督学习中,存在一些用于训练算法的”ground truth”。比如,对收集到的脑部CT扫描数据,神经放射学家可将其分为不同组别。相比之下,对于无监督学习,不需要使用任何标准图像或事先标注类别——计算机本身通过相关算法确定类别。比如聚类算法,图像会根据相似性指标被分为多组,而人们事先并不知道是什么原因导致了分类结果。虽然无监督学习在医学成像中有着巨大的前景,但本文主要关注有监督学习。
在以上介绍背景下,深度学习是一种使用特定体系结构(某种形式的神经网络)的有监督机器学习方法。基于自动提取相关特征的能力,这些人工智能技术的可扩展性极强。以前,若想构建一个图像分类算法,需要领域专家和经验丰富的人工智能研究者进行多年努力。而现在,利用有监督深度学习算法(有标注的数据集)几小时内就能自动创建这样的模型。这些神经网络模型受到大脑结构的启发,用隐藏层表示中间神经元(图2)。虽然现代神经网络与大脑有这些相似之处,但在更准确地了解大脑结构的前提下,模型是否能够提高其应用性能,仍然是一个比较争议的问题。例如,在计算机视觉应用中,在隐藏层敏感性高的许多特征(例如不同方向的边缘)与哺乳动物的视觉皮层都有关联。
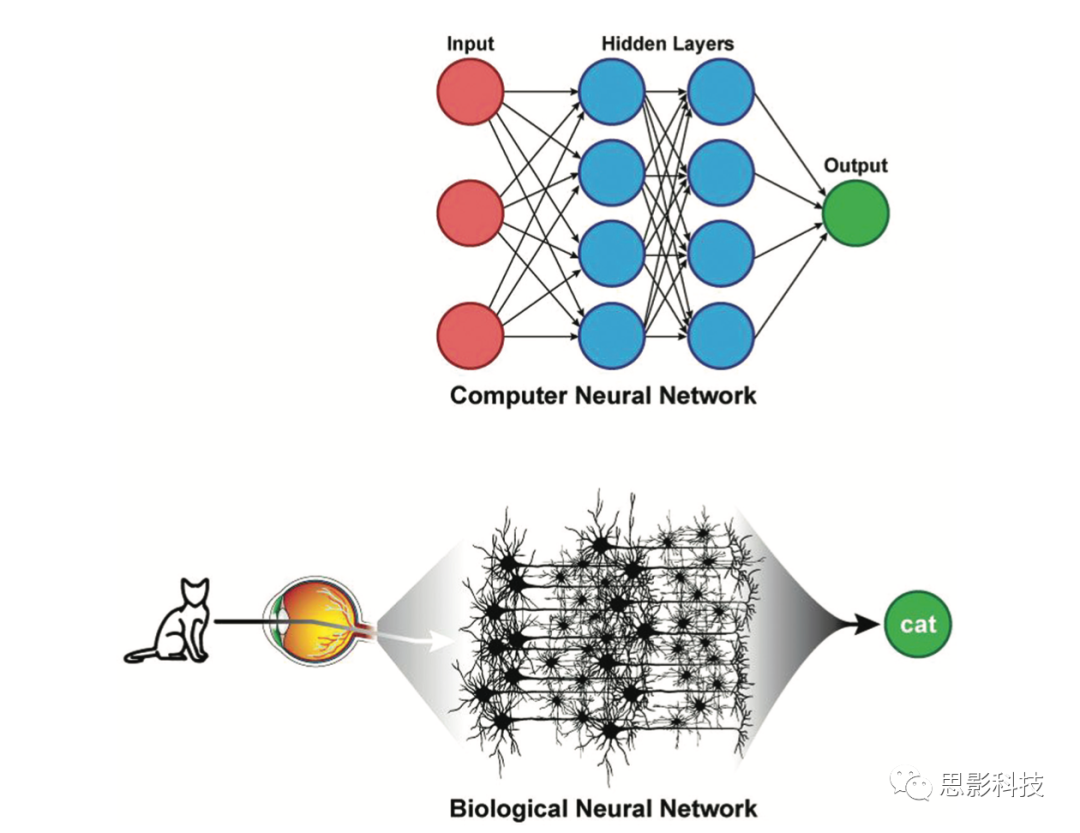
图2:人工神经网络和生物神经网络的相似之处。人工神经网络的隐藏层可以被认为类似于大脑中间神经元。
在神经成像中,一个简单的深度学习模型的架构如下所述:
(1)将影像数据转换为一个由体素强度组成的向量,每个体素则作为一个输入“神经元”。下面讲解的实例中,深度学习的输入是单个影像,但实际运用过程中,输入可以包括整个成像序列、多个序列甚至是多个模态数据。
(2)确定输入对象后,接下来需要了解这个深度学习模型有多少层(深度),每个层有多少个神经元(宽度)(图三)。每个神经元都代表着一个数值,两两神经元之间的连接,代表不同的权重(神经元之间的关系强度)。深度学习中,会接触到“全连接层”的概念,其意思是说,网络结构其中一层的所有神经元均连接到下一层的所有神经元,可以用矩阵乘法加以理解。
(3)最后,在神经元的输出端,通常会包括一个非线性的激活函数,将非线性函数引入至方程求解,即可表示非常复杂的函数。否则,凭借相关线性函数,无法表示、计算深度学习中如此庞大且复杂的网络结构。历史上,sigmoid(S型曲线)和hyperbolic tangents(双曲正切线)一直是基于神经科学的感悟而使用的。
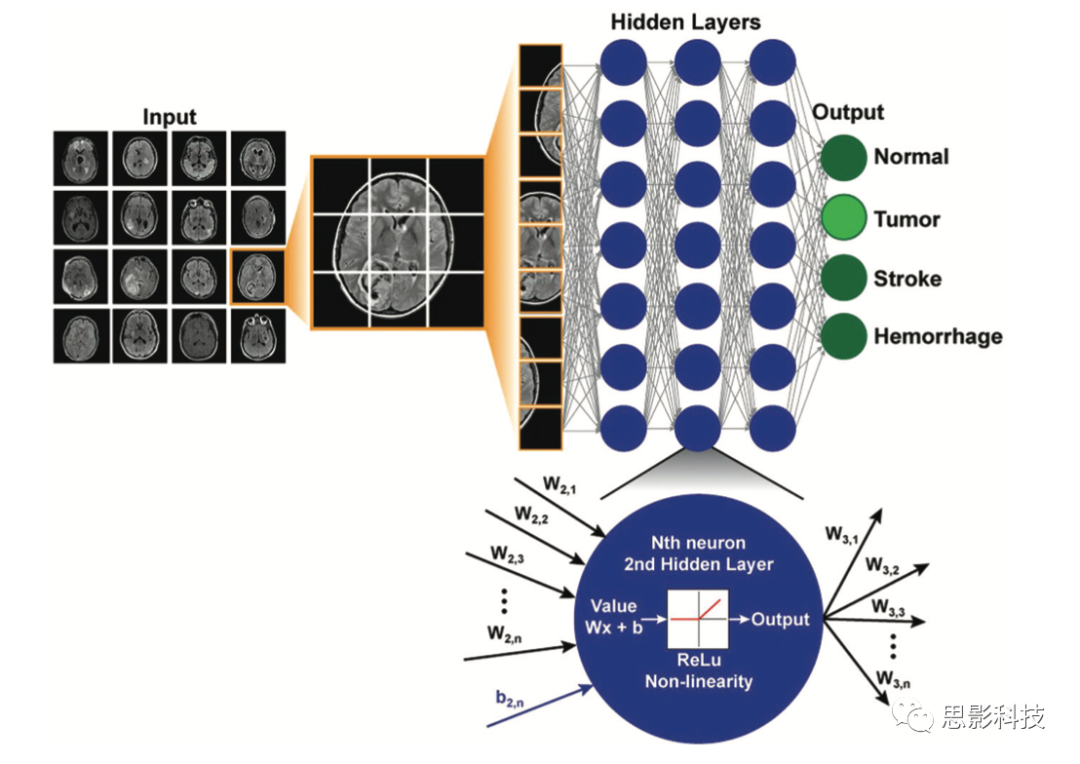
图3:一个简单的深层网络架构的例子。该网络的目标是将MR影像分类为4种特定的诊断(正常、肿瘤、中风、出血)。多个不同的图像作为训练集。对于新的预测图像,其被分解成不同体素,每个体素作为网络的输入。这个例子有3个隐藏层,每层7个神经元,最终输出的是4种分类结果的概率。所有层都是全连接层,底部是一个放大视图第二隐藏层的单个神经元(第一层的所有神经元均和它有连接),通过执行一个标准矩阵乘法及非线性函数进行计算,将结果输出至下一层的所有神经元。
尽管存在一些典型的配置和假设,但为特定应用去选择网络架构还是需要费点思考的。通常情况下,隐藏层的神经元数量大于输入和输出层。最后一层则对期望的结果状态进行编码。例如,如果一个人希望将图像分为“出血”或“无出血”两个状态,则输出层设定2个神经元是合适的,而每个最终神经元存储的值可以理解为训练示例对应于特定类别的概率。模型训练的时候,会有训练集、验证集之分。训练的目标其实是优化网络权值。当网络权值达到越合适时,输入一个新的样本图像,在输出层被预测正常的概率就越大。例如,输入层是一个有出血的图像,我们则希望模型输出的结果是出血的预测概率高,其他类别的预测概率低。那,如何来实现这一目的呢?请带着思考继续阅读寻找答案。
用分为不同组别的大量样本去训练一个神经网络模型,是一个比较理想的状态。通常情况下,50%-60%的样本量作为训练集,10%-20%的样本作为验证集,20%-40%的数据,则作为测试集。训练集数据用于确定模型的参数设置,大样本的训练集对深度学习模型来说是非常非常重要的,即使是对于一些比较浅的网络架构,也可能存在100000个自由参数。训练数据集需要进行多次循环,直到模型精度达到收敛状态(模型精度再也不能更高了)。最开始,预测结果可能比较糟糕,但是,我们可以通过“代价函数”(量化预测结果与实际观测值的指标)修改我们的模型设置。紧接着,反向传播算法,目的也是用于减小模型输出结果与实际结果之前的误差,它根据代价函数的值调整神经元之间连接强度(权重),然后用于加强正确的预测并惩罚不正确的预测。利用单独的训练实例和多次迭代重复该过程,从而优化网络权重,有效地训练模型。模型训练后,如“学习率”,“迭代次数”等超参数需要进一步优化。最后,利用测试集数据进行模型精度评估。这种评估可能产生与训练集类似或更高的错误率,但这进一步有助于评估最终模型在真实数据中的使用情况。模型进行训练通常需要大量的时间,但最终对新数据进行预测时计算速度会很快。
代价函数的正确选择是非常重要的。对分类而言,如果模型的预测正确率较高时,代价函数值则应当进行较低设置;而当模型的预测正确率较低时,则相反。在分类的情况下,“交叉熵损失”是一种应用比较广泛的代价函数,逻辑回归想进行多个类别的预测扩展时,可以使用softmax函数实现。对于图像预测,常用的代价函数包括预测图像和参考图像之间的均方根误差,以及结构相似度指标:相似度度量。一种比较前沿的方法是生成对抗网络,这个对抗网络会代替成本函数本身,其目标是使参考图像和预测图像在最佳状态下难以区分。生成对抗网络去努力消除预测图像和参考图像之间的系统差异,这在放射学环境中是非常理想的。
完全连接的神经网络在计算上非常昂贵,因为权值的数量太庞大,特别是对于典型矩阵大小的图像(拥有256 *256*65,536个体素)。即使只有一个切片,要实现一个完全连接的层也需要40亿个权重计算(OMG!,小编注)。因此,基于图像深度学习的许多研究已经转向使用计算效率更高的结构,如卷积神经网络(CNNs)。
CNNs非常适合成像。在每一幅图像的位置上,使用一个小的权重“核”来确定下一层神经元的值,而不是完全连接(图4)。这种方法模仿了卷积的数学运算。
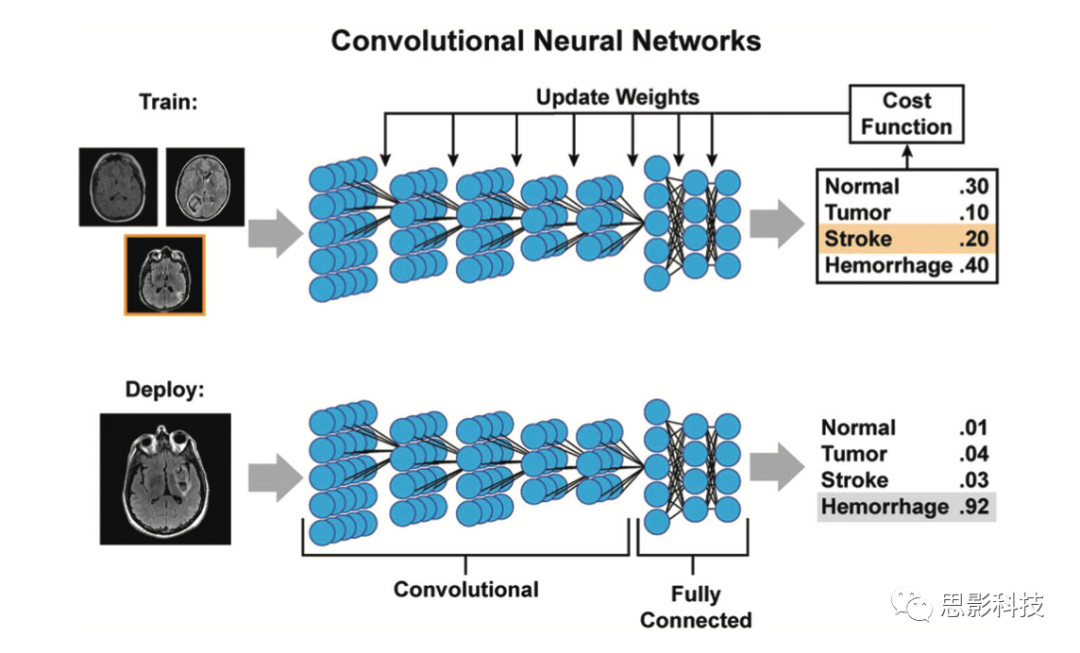
图4:深度卷积神经网络的训练和部署示例。
在训练过程中,对每一幅图像分别进行分析,并在每一层上移动一小组权值(卷积核),以便向下一层提供输入。每个层可以有多个通道。通过汇集相邻体素或在内核应用之间使用更大的步距,更深的层通常具有更小的空间维度,但有更多的通道,每一个通道都可以被认为代表一个抽象的特征。在这个例子中,5个卷积层之后是3个完全连接的层,然后输出各个类别图像的概率。这些概率与已知的类(训练示例中的stroke)进行比较,可以用来度量预测的差异(代价函数),然后使用反向传播来更新不同内核和全连接参数的权重。当模型训练完成并应用在新的图像上时,该过程将产生类似的概率输出,并期待其中真实诊断的样本具有最高的预测可能性。
在两层之间,唯一需要确定的权重是内核权重,然后对整个图像进行光栅化,即可获得下一层的结果。这种方法有几个优点。首先,它显著减少了权重的数量。其次,它允许空间不变:图像特征可能出现在不同的位置,而CNN允许它们的识别独立于它们的精确位置。通常,CNNs会将相邻的体素汇集在一起,或者将内核以间隔(称为“跨越长度”的超参数)在这些图像之间滑动,这样每个后续层的维度都比上一层的维度小。对于每一层,通过在创建多个“通道”,可以训练多个不同的内核;这样的结构允许网络学习许多位置不变的特性,例如边缘、纹理和数据的其他非线性表示。通过pooling或增加stride长度,可以将更大的特性合并到网络的隐藏层中。事实上,CNNs以位置不变的方式提取相关图像特征的能力与大脑视觉系统的结构相似;Hubel和Wiesel5在20世纪60年代表明,猫的大脑的不同区域对不同方向的边缘等特征反应强烈。
对于分类预测,最终的输出层通常需要连接全连接层。对于图像预测,使用上采样层将较小的维度隐藏层“重新形成”为输入图像的原始大小。这样的架构被称为“编码-解码器”,因为它以增加隐藏层的抽象(编码)的方式表示图像,然后使用它们又重新创建(解码)图像。
如上所述,典型的深度学习模型有数百万个权重需要估计,我们会确定非常多的方程(不是变量),最后解这些代数方程组,来确定权重估计值。如果一个深度网络只训练了很少的样本例,就有可能非常完美地表示输入和输出状态之间的转换。但是,这种方法在新的样本上却并不适用,即所谓的“过度拟合”问题。过度拟合的最佳解决方案是扩大样本量,同时,正则化或删除等方法也可解决过拟合问题。另一个解决过拟合问题可能的解决方案则是数据扩充。
数据扩充是一种增加训练数据量的方法。由于大多数图像数据,无论是在x-y平面上的偏移量、旋转、翻转、轻微拉伸还是倾斜都是可识别的,因此通常采用这种图像操作来增加训练数据。虽然这些图像改变不会增加更多的样本数据,但有研究已经证明,它们可以提高模型的鲁棒性。
神经放射学许多方面均有深度学习的具体应用,神经放射学研究的一个完整工作流程会考虑到相关深度学习算法的应用。设计流程中,首先会参考临床医生的研究,找到研究临床着陆点,然后采集相关影像数据。接下来,放射科医师会接触这批数据,针对这批数据,是做目标物体检测、病灶分割还是鉴别诊断?不管是做哪方面工作,我们都可能因为应用深度学习算法而受益(在更加智能的情况后,达到我们预期的指标)。
确定研究思路后,需要根据特定的神经影像学方案进行试验。这一过程,往往需要各科医生大量的宝贵时间,不止是依赖放射科医师成像协议的专业知识,也需要临床医师的特定需求关注点(这些点可以理解成临床医生接触的大量以往的文本病例)。深度学习在自然语言处理方面已经很成熟,因此,这些文本病例的自动化处理具有可行性。理论上来说,文本处理,也是一个分类的过程,通过输入文本病例及患者的元数据,最终预测的是不同文本类别。由于已经存在大量的训练数据,包括所有被人类所记录的先前的研究都可以用于训练,使用深度学习应用于文本研究,是一个比较理想的选择。
利用深度学习方法可以进行图像重构,也可以提高图像质量。深度学习框架能够去“学习”标准的MR成像重建技术,如笛卡尔和非笛卡尔获取方案。通过优化图像数据的采集方式,将深度学习到k空间欠采样与基于模型/压缩的感知重建方案相结合,有潜力促成一场成像科学革命。
此外,还可以用深度学习的方法提高图像质量。如果可以获得低分辨率和高分辨率的图像,就可以使用深度网络实现超分辨率。如果有低质量和高质量的成对图像集,可以考虑它们之间的最优非线性变换。该方法已应用于CT成像,并通过由正常剂量和模拟低剂量的CT数据集上证明其价值。一项使用3T影像作为输入数据,7T影像作为输出数据的研究表明,可以训练深度网络从3T数据中,直接创建模拟的“7T”影像。通常,要得到一定的成像序列是非常耗时的;比如DTI序列,对多个角度的扫描延长了检查时间,超出了许多病人所能忍受的范围。研究显示,通过预测相对较少角度的最终参数图(分数各向异性、平均扩散率等),深度学习方法可以将成像持续时间缩短12倍。本课题组通过采集2分钟和30分钟的成对动脉自旋标记(ASL)CBF图像,训练了一个深度网络,显著提高了ASL的信噪比(图5)。
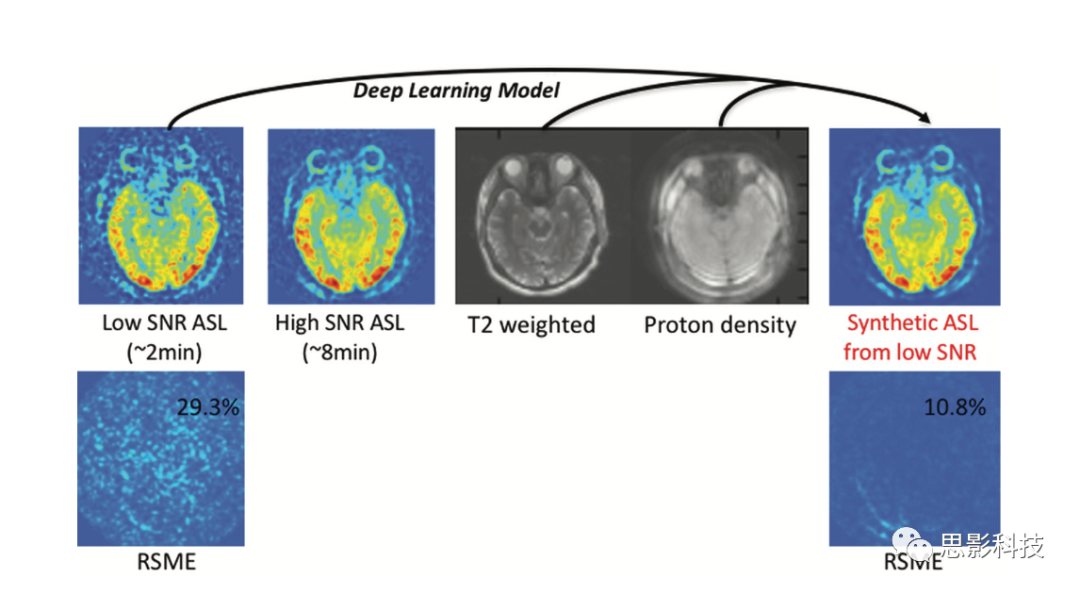
图5:利用深度学习提高动脉自旋标记MR成像的信噪比。
使用单次重复获得的低信噪比ASL图像对模型进行训练,参考图像为多次重复获得的高信噪比ASL图像(本例为6次重复)。为提高算法性能,质子密度加权图像和T2加权图像也被用作模型的输入。模型预测的低信噪比ASL图像结果如右图所示,这是一幅具有改进信噪比的合成图像。在本例中,参考图像与合成图像之间的均方根误差(root-mean-squared error, RSME)与原始图像相比降低了近3倍,从29.3%降至10.8%。
创造不同对比或不同特点、不同模式的图像,是深度学习的扩展。例如,通过使用全国医学影像计算数据库联盟(http://www.insiight-journal.org/midas/community/view/17),Vemulapalli等人使用深度学习网络从T2影像预测T1影像,反之亦然。深度学习的另一个应用是PET/MR成像,其与PET/CT不同,CT用于计算衰减图,MR图像不直接产生衰减图像。然而,如果MR图像中有软组织、空气和骨骼的信息,这些序列就可以作为深层网络的输入。关键的是,这里要预测的图像不再是另一个MR图像,而是同一对象的一个校正的CT扫描。最近证明了磁共振成像衰减校正的原理,其性能优于其他同类技术,另一项研究则证明了磁共振成像在放射治疗中的类似应用。
在临床试验中,患者可能无法接受某种诊断技术(如患者身体有植入物时,不适合磁共振成像扫描),或者,患者会缺少某特定时间点的图像。虽然可以使用统计技术来解释这些缺失的数据,但前提是从同一人群中抽取的足够多的患者已经完成了影像学检查,才有可能去训练一个深度学习网络来重现这些数据。Li等人通过阿尔茨海默病神经成像计划(ADNI;http://www.ADNI-info.org/)证明了这一点。他们使用FDG-PET和T1加权磁共振成像进行CNN训练,然后在测试集上使用该网络,预测患者磁共振成像研究中预期的PET图像,结果显示,CNN方法优于更传统的方法。
检测和分割病变对人类来说是一项繁重的任务,但非常适合机器学习。虽然两者(检测和分割)有关联,但实际上它们是两个不同的任务。前者的输入是未标记的影像,通过自主学习,标记潜在的异常;后者分割的目标则是限定异常结构周围的区域。神经放射科医生经常被指派监测已知病变的大小或活动随时间或治疗反应的变化,所以,识别和描绘病变边缘是非常重要的。深度学习在分割正常脑结构方面也有优势,因为现有的方法费时费力,可能应用于年轻人或老年人。此外,许多研究项目依赖于图像病灶的人工描绘。因此,我们可以训练一个深度学习网络,以图像作为输入,手工绘制分割的结果作为输出。实际应用中,这种做法早期已经显示出巨大的成功。虽然在不同的神经疾病条件下有许多例子,但我们主要参考3个有代表性的领域:检测微出血、识别脑梗死和预测中风患者的最终梗死体积,以及分割脑肿瘤。
Dou等人描述了一种通过训练CNN对磁敏感度加权图像的注释数据集来检测脑微出血的过程。他们提出了一个级联的,两步走的方法:首先,候选病灶被CNN识别;然后,这些被识别的病灶输入到一个有辨识力的CNN网络中(比如,判别真正的微出血或模拟微出血)。此网络的灵敏度高达93%,平均每个受试者存在3个假阳性识别。
自动识别和勾画梗死的脑组织将有助于急性中风的设置。Chen等人使用DWI作为两阶段深度学习算法的输入,能够检测94%的脑急性梗死。使用Dice系数作为准确性的标志,患者中风后2天的的Dice平均得分为0.67。另一项研究使用三层深度CNN和两层全连接的CNN研究得到了类似的结果,并且优于其他几种机器学习方法。另一个应用是预测急性中风患者早期DWI/PWI的最终梗死体积。目前,弥散-灌注适配的方法是主流的模式,即DWI病变代表不可逆损伤的组织,而PWI则代表有梗死危险的组织。与其使用这些人为勾画再提取的特征,不如使用初始DWI和PWI图作为输入,几天后测量的最终梗死面积作为输出,来训练深度神经网络。通过使用这样的框架,Nielsen等人证明了深度学习架构在急性中风中比传统的损伤预测方法表现更好。他们还表明,37层架构优于较浅的3层架构,这突出了网络深度特性的重要性。这种方法的一个令人兴奋的应用是,基于不同处理,可以训练不同并相互独立的网络。在中风方面,人们可以训练接受中风治疗和未接受中风治疗的患者的网络。使用这两种不同模型的新预测可以洞察治疗是否会导致梗死体积减少(图6)。
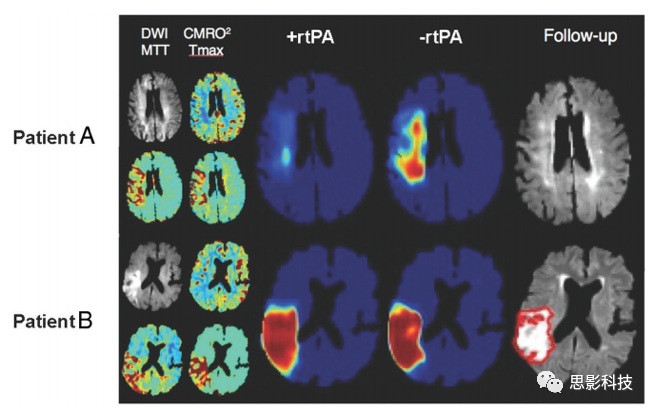
图6:两个急性缺血性卒中患者梗死风险的预测实例,针对有无使用rtPA的患者,分别使用两个训练过的神经网络进行预测。患者A,76岁,女性,症状发作后1.5小时,NIHSS评分为10分。rtPA网络估计永久性损伤可以忽略不计,与急性DWI一致,随访时永久性组织损伤很小。rtPA网络显示,如果不进行治疗,相当一部分急性缺血区域将发展为永久性损伤。患者B是一名72岁男性,入院时NIHSS评分为10,发病后2小时扫描。在这种情况下,这两个网络显示治疗的预期影响很小,可能是由于在DWI上看到的缺血性事件成像时的进展。CMRO2:大脑氧代谢率;Tmax:最长时间。图由Kim Mouridsen和Anne Nielsen/奥胡斯大学提供。
不仅是增强边缘,还有如增强区和坏死区的特征进行的脑肿瘤的自动分割,有助于广泛的一些适应症确定,如诊断、术前计划和随访。脑肿瘤图像分割数据集公开可用,专家可手动分割,为训练新的分割算法提供了一个试验场地。在赢得2015年ImageNet挑战赛的结构基础上,2016年,脑肿瘤图像分割数据集的最高性能是使用全卷积残差神经网络实现的,其完整肿瘤、核心肿瘤和增强肿瘤的Dice系数在0.72到0.87之间。另一项研究中,Korfaitis等人训练了一个深度自动编码器解码器,在脑肿瘤图像分割数据集上分割T2-FLAIR病灶,该数据集包括186例患者手工绘制的病灶轮廓。然后,他们将模型应用于另一组135名肿瘤患者,在这组患者中,由3名专家进行病灶分割,并综合了3个专家的个体结果测量了Dice系数(0.88)。他们注意到,3个专家在分割上存在显著差异,同时指出了统一分割标准的重要性。
放射学领域,机器学习至高无上的应用其实是一个“端到端”的解决方案:输入端是图像,输出端则是一份涵盖图像所有突出特征的放射学报告草案。这似乎不太可能实现,但随着深度学习的深入研究,这方面也正在逐步取得进展。这种方法需要大量带标注的训练数据(有监督学习),这些数据目前以多种不同形式存在。使用标准化词汇的结构化报告及标准电子病历平台,这些都能够形成深度学习所需的大型成像/诊断数据库。本节则将讨论深度学习在神经放射学诊断中的一些早期应用。
Gao等人使用深度学习网络,将285例无增强脑部CT图像分为3类(正常老化、病变[如肿瘤]、阿尔茨海默病[AD])。另一项研究表明,在ADNI数据集中,使用多模态叠加深度多项式网络可以将患者分为不同的二元组(如AD与NC(健康对照组),轻度认知障碍转换(MCI-c)和无轻度认知障碍转换(MCI-n))。该研究的输入不是图像,而是使用从T1加权图像中分割出的93个结构体积以及这些相同区域中的[18F]FDG-PET信号强度。在区分AD和NC时,模型的AUC值高达97%;预测MCI转换与否时,模型的AUC也达到0.8。Suk等人的研究表明,利用深度加权稀疏多任务学习框架,使用ADNI数据集中的脑脊液数据结合相似特征,可以提高分类准确率:区分AD患者与NC患者的准确率达到95%。但是,当尝试3分类(AD、NC和MCI)时,准确率下降到63%,4分类(AD、NC、MCI和MCI -nonconverter)准确率进一步下降到54%。后一点说明,从简单的二分类任务过渡到神经放射学家所熟悉的多任务诊断分类,仍然是一个重大的挑战。
另一个应用,是使用深层网络识别非创伤性脑部CT上是否存在出血。虽然一般的机器学习技术已经成功地应用到这些案例中,但近期才对深度学习方法在此方面的应用进行了评估。Phong等人使用几个“预训练”的深层网络作为他们训练的起点。
具体的说,他们的训练起点来自GoogLeNet(http://deeplearning.net/tag/GoogLeNet/)或Inception ResNet(https://keras.rstudio.com/reference/application_Inception_ResNet_v2.html)的最佳权重,随即利用这些权重去训练非医学图像,然后使用这些非医学影像数据训练最后的全连接层。这种方法(迁移学习)与从零开始的训练相比,可以用更少的数据对网络进行训练。以此思想为基础,他们使用80例数据作为训练集,20例数据作为测试集,最终分类准确率达到98%。
Plis等人检测了结构和功能磁共振成像作为预测各种神经疾病的深度网络输入。在结构成像方面,他们可以从健康患者中鉴别出精神分裂症和亨廷顿舞蹈症患者。对fMRI,他们发现,在识别功能网络时,深度网络和独立成分分析的表现相似,但前者更倾向于保留边缘细节。使用时序自编码神经网络模型预测的静息态下fMRI时间序列下一时间点时的结果,应用于Human Connectome Project数据,则显示了识别特定任务网络的能力。
一个值得关注的问题是,如果以上应用获得成功,那放射科医生所做的一些传统工作可能会过时。最近报告了一项深度学习应用案例,模型输入是医学影像(病理切片),输出则是基于文本信息的诊断报告。虽然这项技术还处于初级阶段,但不难想象,用CT扫描影像及其文本报告信息,完全可以训练一个类似的网络。虽然深度学习很可能自动化放射科医师的工作任务,但模型的输出结果仍然需要医生进行检查并验证,如此才可更可靠的应用于临床。深度学习的另一个关注点是,我们对模型的内部工作机制了解甚少,就像一个黑盒子;它们能很好的应用于预测,但我们并不清楚,它们是如何实现这一功能的。这与以往许多放射学研究形成对比,以往放射学研究严重依赖于领域知识和现实模型的构建。所以,了解深层网络如何以及为什么能够表现得如此出色,是AI的一个活跃研究领域。
此外,深度学习仍然存在两大限制:1,严重依赖大量标注数据集,2,在原始数据和实践模式发生变化时,如何保持模型的最新版(更新迭代问题)。在那些容易受到干扰的应用程序中,还不清楚哪些应用程序有足够的临床需求来推动其后期的广泛使用。因此,放射科医生必须与人工智能科学家保持联系,其既要了解现有方法的能力,又要以智能的方式指导未来的研究。虽然这是一个比较有争议的问题,但深度学习虽然在逐步发展,可目前也近乎没有研究证明,深度学习技术可以完全取代放射科医师。在可预见的将来,它们可能会成为强大的图像处理和决策支持工具(助手),以此提高放射科医生的诊断准确率和工作效率。
深度学习的丰富应用可能会导致往后大家更多地使用这项技术。但以多快的速度发生取决于以下几个关键因素:
1)算法方面:深度学习通过添加隐藏层可以从大量数据集中学习到更多信息;如果可以使用更大的标注数据集,深度学习的应用能力将更强,诸如ADNI和癌症影像存档(https://public.Cancer Imaging Archive.net/ncia/legalRules.jsf)等数据共享计划的重要性怎么强调都不为过;
2)硬件方面:运行这些方法所需的计算机硬件不断改进,成本也越来越低;
3)软件方面:开源软件框架的可用性,如Caffe、Tensorflow、PyTorch和Keras,极大地促进了深度学习的发展。然而,在这些方法成为临床实践的常规部分之前,供应商们应提供一个能够很好地把当下工作流模式集成的全包系统。通过医学影像会议和同事等之间的交流,越来越多的放射学研究工作者和实践者对深度学习感到满意,而深度学习的临床应用,也将从当前较为简单的情况扩展到解决更复杂、更专业的问题。因此,我们可以期待深度学习在神经放射学这一领域的进一步发展!
4)参考文献:10.3174/ajnr.A5543

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
更新通知:第十届脑影像机器学习班(已确定)