

大量研究使用各种生物信号检测心理负荷(MWL)并证明有效,但目前研究通常只使用一种模态来分类MWL。本研究的目标是使用多模态深度神经网络(DNN)对感知心理负荷(PMWL)进行分类,以允许模态间的特征共享。实验借助语言逻辑题模拟MWL(心理负荷),问题有五个难度级别,以随机顺序呈现。被试做题后报告感受的1到7的难度等级,7是最高难度。我们使用LabStreamingLayer(LSL)同时采集皮肤电反应、光体积描记图、功能性近红外脑血氧成像和眼球运动,答题时的mark信息也传输到LSL。我们使用上述四种模态设计了一种用于PMWL(感知心理负荷)分类的新型中间融合多模式DNN并评估其表现。指导DNN设计的两个主要标准是:模块化和通用性。上述模型可实现七等级PMWL的准确分类(0.985个等级)。由于设计的模块化性质,模型架构允许轻松添加/删除模态,不会对结构产生重大影响。此外,我们显示提出的神经网络用多模式时的表现更好。本文中使用的数据集和代码公开可用。本文发表在Frontiers in Human Neuroscience杂志。(可添加微信号siyingyxf或18983979082获取原文,另思影提供免费文献下载服务,如需要也可添加此微信号入群,原文也会在群里发布)。
可结合以下机器学习相关文章阅读,加深理解,感谢帮转支持(直接点击,即可浏览,加微信号siyingyxf或18983979082获取原文及补充材料):
基于EEG信号与面部表情的连续情绪识别
EEGNet:一个小型的卷积神经网络,用于基于脑电的脑机接口
BRAIN:静息态脑电图揭示了肌萎缩性脊髓侧索硬化症的四种亚型
EEG脑机接口算法
脑电信号处理的机器学习
脑电信号解码和可视化的深度卷积神经网络
基于M/EEG的生物标志物预测MCI和阿尔茨海默病
基于EEG信号的情绪识别
基于机器学习的脑电病理学诊断
高阶统计量在EEG信号处理中的应用
EEG分类实验block设计的危险与陷阱
Current Biology:视觉想象和视觉感知共享Alpha频带中的神
JAMA Psychiatry:使用机器学习的方法探究焦虑和创伤性障
Nature neuroscience:利用encoder-decoder模型实现皮层活
ANNALS of Neurology:中风恢复过程中脑机接口可促进运动
Nature Biotechnology: EEG特征预测重度抑郁症的抗抑郁药反应
BMC Medicine:自闭症谱系障碍静息态EEG信号的定量递归
SCIENCE ROBOTICS:非侵入式神经成像可增强机器控制
Lancet Neurology:一种供四肢瘫痪患者使用硬膜外无线脑机
NATURE子刊:出生第一年的纵向EEG power能识别孤独症谱
STROKE:用于慢性中风患者运动康复的动力外骨骼的健侧脑-机
基于fNIRS连接度特征监测飞行员的参与度(自动vs手动驾驶着陆)
1.介绍
心理负荷(mental workload,
MWL)在神经科学、人因工学等领域备受关注。MWL受两个变量影响:
1、可用认知资源,取决于相关先验知识、能力、任务经验,高度个体化;
2、所需认知资源,取决于任务难度。在Csikszentmihalyi描述的心流状态下,人们会完全沉浸在任务中,可用认知资源和所需认知资源的比率(α)介于0.8到1.2之间。感知心理负荷(PMWL)是被试反应的MWL。PMWL的自我报告通常使用NASA任务负荷指数(NASA-TLX),检索六个工作量相关因素的量级和来源。不过,主观报告可能影响实验的客观性,且会打断受试的心流状态。生理测量可以替代自我评估的方法,这是一种隐式测量方法(不打断心流状态),可以客观、实时地获取数据,且无需由被试报告。 先前研究已使用多种生理信号在单模态场景下分类PMWL,例如功能性近红外脑血氧成像(fNIRS)、皮肤电反应(GSR)和心率(HR),上述信号都可以有效单独分类PMWL。本研究结合单模态与多模态信息分类PMWL,确定哪些生理信号提供的信息对分类有价值。我们还制定了深度学习多模态信号分类场景下的设计原则,原则可用于制定中间融合多模态网络(intermediate fusion multimodal network,
IFMMoN)。
2.材料与方法
本文基于多模态测量,使用深度神经网络(DNN)对PMWL进行分类。设计多模态脑机接口时,端到端管道的设计原则是模块化、通用性(modularity and generalisability, MG)。为实现模块化,新设备应方便添加,数据采集、处理与管道匹配,结构影响最小。我们使用了两个有助于模块化的库:1.LabStreamingLayer (LSL),2.TensorFlow。LSL可以轻松添加专用于设备的数据流,TensorFlow API可以实现深度学习模型模块化。通用性意味着附加模式中获得的数据能够提高分类准确性,为提高通用性和应用性,管道还应在PMWL以外的其他分类中也有良好表现。通用性(MG)要求我们的方法尽可能独立于环境和设备,通过数据采集、分析(大部分)自动化来减少人为错误,本项目应用的所有方法、设计都根据MG标准制定与执行。
3.相关研究
我们共结合四种模态分类PMWL: 功能性近红外脑血氧成像[fNIRS,测量大脑中(脱氧)氧合血红蛋白的变化]、皮肤电反应(GSR)、心率(HR)[使用光体积变化描记图法(PPG)测量]、眼动追踪(ET)。
3.1.功能性近红外脑血氧成像
fNIRS可以测量大脑中脱氧/氧合血红蛋白浓度的相对变化。大脑功能激活期间,能量的使用导致血红蛋白分布发生变化,这种变化可以用近红外光测量,然后与组织特定区域的激活关联。目前对于MWL检测中fNIRS数据深度学习的最佳分析方法没有明确共识。
相关研究可分为两大类:
1.多层感知器(MLP),由几个密集连接的层组成;
2.卷积神经网络(CNN)。
递归神经网络(RNN) 也有被使用,不过目前并不常见。MLP研究在二元以及更复杂问题上表现出很高的准确性,有研究报告63%的用户识别准确率(n=30),以及超91%的心算、休息二元分类,尽管前者的准确率较低,但其分类对象更贴近自然生活。
Tanveer等人使用了两种模型,一种是有六个全连接密集层的DNN,用于修正版Beer-Lambert光极密度;一种是具有两个卷积层、两个密集层的CNN,用于各通道的激活地图,观察二元交叉熵损失。他们报告二元分类的准确率为99.3%,CNN的效果最佳。Daegazany等人将MLP用于5-class运动想象,达到80%以上的准确度,这个方法的好处是没有对数据进行任何预/后处理,因此该方案也可用于所需注意力的分类,因为大部分时间用于数据采集而非(预)处理。不过,为了实现这一点,他们使用了两个全连接层,每层有10,000个神经元,计算相当复杂。
3.2.光体积变化描记图法与皮肤电反应
PPG是一种测量微血管组织血容量变化的光学方法,血容量变化与心脏活动直接相关,因此PPG可用于测量HR和HR变异性、心跳间隔等测量值。Biswas等人在HR分类任务中达到95%以上的准确率,他们使用两个卷积层、两个长短期记忆(LSTM)层、一个密集输出层。
GSR是与交感神经系统神经支配相关的皮肤电反应,通常用于测量情感、认知唤醒。Sun等人使用LSTM-CNN混合网络识别六类情绪,达到高达74%的准确率。
PPG和GSR都可以提取出特征用于分类,这么做的好处是计算起来简单、便宜,不过这样也去除了可能有用于DNN、多模态融合的隐藏特征。除特征提取,PPG、GSR的形状也方便使用全连接层来处理。
3.3.眼动追踪
ET可获取一个人在任何时间查看的位置信息,这有助于我们理解视觉、显示相关的信息处理。ET数据的训练、评估高度依赖于使用的任务,因此本节不陈述相关研究的准确度。Louedec等人使用CNN预测国际象棋游戏的显著图,使用模型基于VGG16,包含几个反卷积层和融合层。Krafka等人也使用卷积层并与全连接层结合,他们根据输入的面部网格(包含面部位置、左右眼以及全脸)分类凝视。ET数据通常使用卷积层分类,不考虑目标,因为我们对数据的空间特征感兴趣。
3.4.多模态融合
大多数神经网络高度依赖于使用的任务,多模式DNN的设计也如是。Ramachandram和Taylor在深度多模态学习回顾中制定了多模态深度学习的几个关键因素:
1.何时融合这些模态。
(1)早期融合/数据级融合,连接特征或原始数据,将数据输入神经网络。
(2)中间融合,使用各种层将输入映射到较低维度,在输入和输出层之间的某个地方进行融合。
(3)后期融合,看几个较小网络的多数表决。
如Karpathy等人所证,融合时间的选择是灵活的,并且对模型表现有巨大影响。
2.融合哪些模态。
并非所有数据都有助于分类,数据有效的程度也不同。
3.如何处理缺失的模态或数据。
数据缺失可能带来严重的问题,尤其在实时分类中。
早期融合不符合MG标准,因为它需要将输入数据“缝合”在一起,一些原因会导致应用程序出现多个问题:1.不同模态可能使用不同采样率,2.设备的维度可能不同,时间/空间维度的特征可能丢失,3.早期融合将所有数据输送到同一个网络却不管数据来自哪种模态,当数据参数发生变化时,网络的早期层和形状需要重新调整。
后期融合符合模块化的要求,但不符合通用性的要求。后期融合添加/删除模态网络(modality network, MNet)无需考虑其他MNet,不过网络分离也导致我们无法同时实现多模式学习,因为模态之间没有信息交换。
中间融合允许创建多个模块化MNet,这些MNet在各自的领域发挥作用,添加/删除模态也很简单。中间融合最符合MG标准。
3.刺激呈现
实验要求被试解决斑马谜题(zebra puzzle)。斑马谜题是语言逻辑题,提示的基础上将属性与对象关联,问题难度由给出的提示数、所需的平均提示数决定。图1示例有五个问题,问题难度从“非常低”到“非常高”,所有问题来自Brainzilla的研究。回答每个问题后,要求被试休息放松,报告他们认为的问题难度,评分从1到7,7是最高难度。这些评级会在训练期间用作标签。呈现问题的顺序完全随机,刺激呈现过程中LSL流采集数据,被试每次操作时打mark。被试操作为(取消)选择提示和(取消)选择答案,记录被试ID、操作时间点、操作类型、操作ID、操作状态(正确、不正确、已检查),操作时间点用于数据分段。
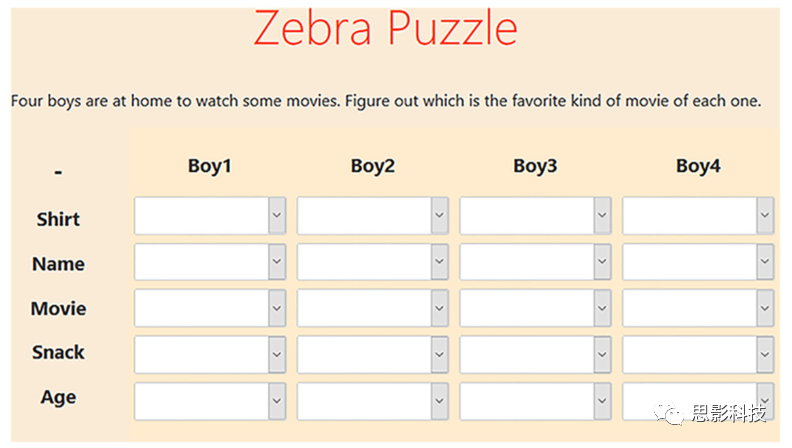
图1.斑马谜题,问题下方有一些线索来帮助被试连接属性和对象(boy)。一个示例线索是“Joshua在某一单元格选项的最后一个”,单击单元格的箭头会下拉该单元格的所有选项。
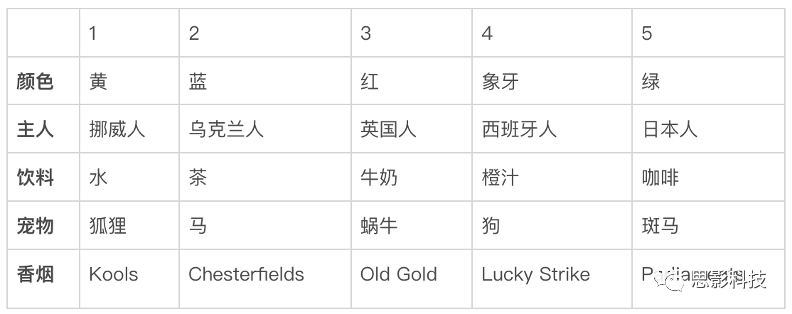
[附: 来自1962年《生活》杂质的一个斑马谜题]
1.有五栋房子。
2.英国人住在红房子里。
3.西班牙人养狗。
4.绿房子里的人喝咖啡。
5.乌克兰人喝茶。
6.绿房子紧挨在象牙色房子的右边。
7.抽Old Gold牌香烟的人养蜗牛。
8.黄房子里的人抽Kools牌香烟。
9.中间的房子里的人喝牛奶。
10.挪威人住在第一间房子。
11.抽Chesterfields牌香烟的人住在养狐狸的人的隔壁。
12.抽Kools牌香烟的人住在养马的人的隔壁。
13.抽Lucky Strike牌香烟的人喝橙汁。
14.日本人抽Parliaments牌香烟。
15.挪威人住在蓝色房子的隔壁。
通过推理可得:
4.被试
招募23名被试,11名男性,12名女性,平均年龄24.7岁(20-57岁,SD=9.8),一名被试因为数据质量差被排除。我们使用Sona系统招募被试,这是特温特大学的被试云管理软件,同时我们也通过社交网络进行招募。实验得到特温特大学BMS学院伦理委员会的批准,所有被试签署书面知情同意书。
5.数据采集与同步
所有数据在同一配置参数的笔记本电脑上流式传输和记录。多模态数据采集使用:1、Shimmer3 GSR+,测量GSR和PPG,2、Tobii Pro X3-120,测量ET,3、Brite24,测量fNIRS数据。设备采集数据实时发送到LSL。使用LabRecorder将数据记录到每个被试的XDF文件中,然后使用PyXDF将数据导入Python。PyXDF会自动检查指定的与接收到的采样率,必要时进行数据去抖动处理。我们还手动检查了数据同步情况,确保各模式数据在录制过程中对齐。数据选择、处理过程中还进行了几项同步检查,见6.1.数据选择。
我们使用Thales HBA实验室编写的应用程序将原始GSR、PPG从Shimmer3 GSR+流式传输到LSL,数据采样率为256Hz。Tobii Pro X3–120的数据使用Tobii Pro SDK和PyLSL制作的自定义python应用程序流式传输。ET数据以120Hz的采样率传输,包含双眼的x、y坐标。fNIRS数据使用Oxysoft 3.2.51.4 × 64和Brite24,可用通道27个,采样率10Hz,波长756和853nm,通过修正Beer-Lambert将O2Hb和HHb数据从Oxysoft映射到LSL。光极模板见图2,数据传输见图3。
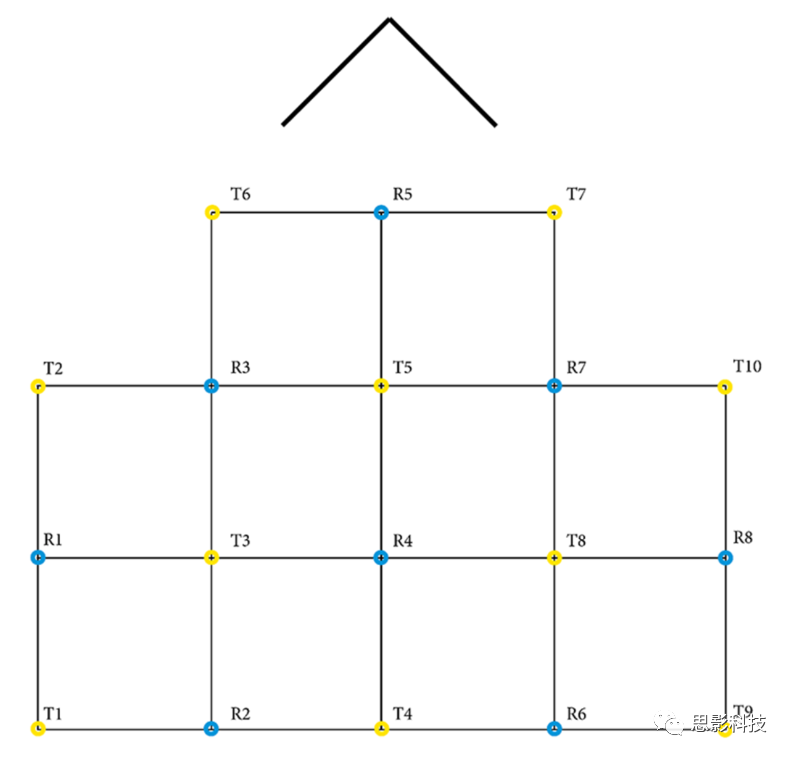
图2.fNIRS光极分布。每个发射器(T)和接收器(R)间形成一个通道,共有10个发射器、8个接收器、27个通道。箭头代表被试的鼻子。
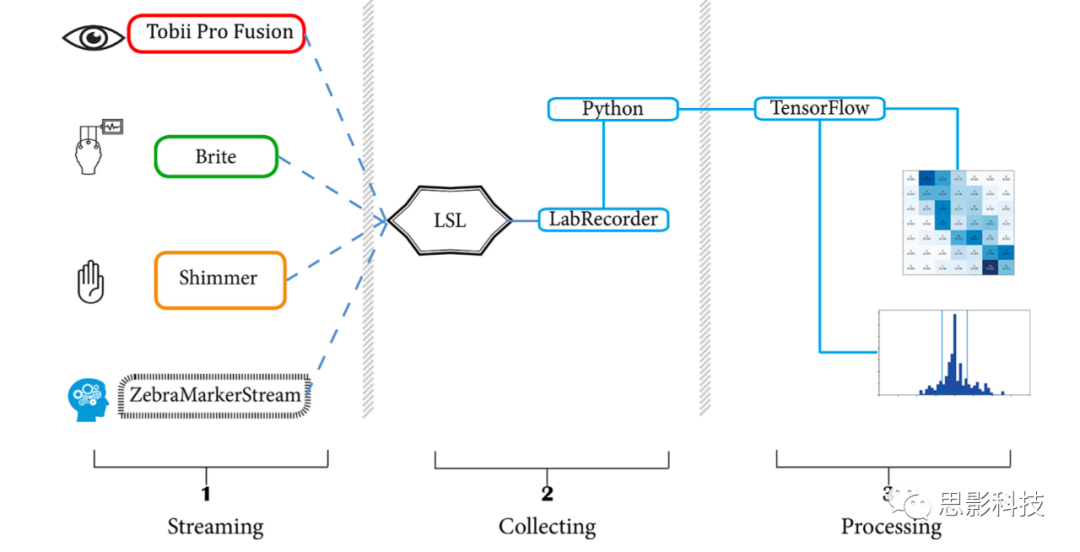
图3.实验设置,左侧为所有数据流:Tobii眼动追踪数据、Brite fNIRS数据、Shimmer GSR和PPG数据、斑马谜题的mark。虚线表示到LSL的流式连接,中间部分的LabRecorder以XDF格式记录数据,右侧部分显示已处理数据的输出示例。
6.模型优化
6.1.数据选择
数据根据斑马谜题数据流的mark选择。数据选择过程中需要注意:
1.被试快速连续选择多个答案时,mark可能靠得很近,基于这些mark选择的数据会部分重叠。
2.软件问题会导致部分数据缺失。
为了解决这些问题,我们使用布尔掩码来确定可用的mark。首先去除时间点完全相同的mark(可能由于设备时间点漂移和/或数据丢失),其后计算样本的简单统计数据(如均值、方差、最大值、最小值等)来查看分段数据的质量。不过,噪声大的样本可能是更贴近真实生活的数据,我们没有移除这些样本。
确定mark后,选择mark前8秒的数据(血液动力学函数在神经元活动开始5-8s后出现峰值,被试的沉思发生在知道/选择正确答案之前)。每个被试新建一个包含最终mark的CSV文件,包含四个同步数据:fNIRS、GSR、PPG和ET,样本标签为斑马谜题的难度。这些样本被添加到TFRecord文件中,该文件允许将许多方法(如混洗、批处理和拆分)同时应用于所有数据。数据集可在doi: 10.4121/12932801找到。
6.2.模型
模型选择中间融合,这可以最大限度提高模型的应用性,允许多模态数据特征共享,同时遵守MG标准。中间融合的模型架构中每个模态有一个基本网络/MNet,一个Head网络集成所有MNet。我们用两种方法实现MNet和Head网络:1.基于文献,2.仅包含密集连接层。
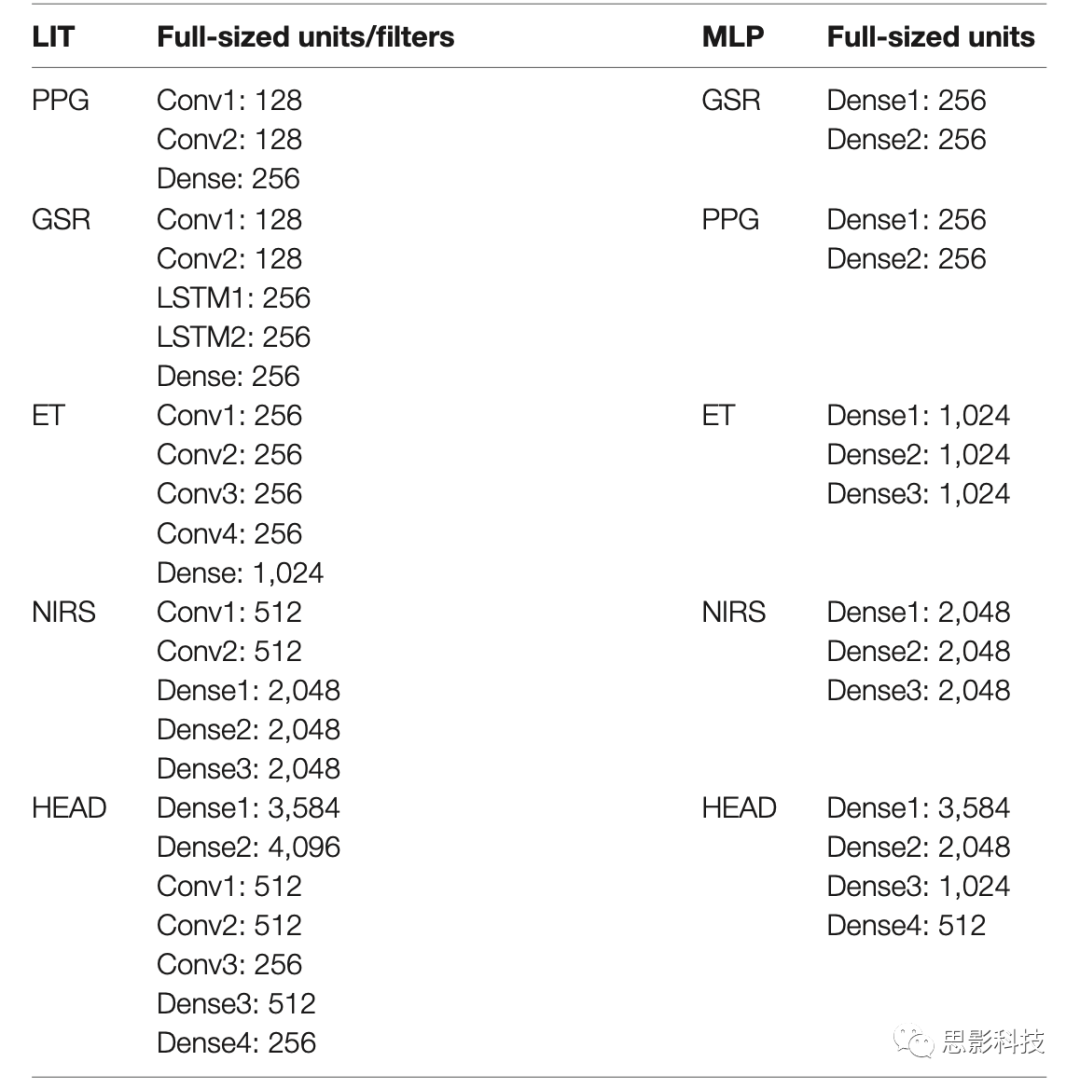
基于文献设置的模型有四个自定义MNet,每个模态一个,和一个自定义Head网络。PPG MNet由两个卷积层组成;GSR MNet由两个卷积层和两个LSTM层组成;ET MNet由四个卷积层组成;fNIRS MNet由两个卷积层和两个密集层组成。在Head融合之前,所有MNet都通过各自的密集连接层在低维空间中表示。基于文献、密集连接模型的结构和层见图4、5,模型的层和每层的单元/过滤器数量见表1。通过批量标准化、最大池化使输出更加稳定。两种模型都创建了一个较小的替代模型,每一层包含一半的单元和过滤器,以此观察减少网络大小的效果。由此,我们共有四个模型:MLP(仅密集)、S_MLP(小型,仅密集)、LIT(文献)和 S_LIT(小型,文献),所有模型用同一个数据集训练。
我们使用两种不同的标签:
1.各被试报告的问题难度,例如被试1报告问题3的难度为6,那么问题3的所有样本都打上被试1的评分6的标签。使用公式将评分转换为0和1之间的值:评分/7,评分1对应于标签“0”,评分2对应于标签“0.1667”等。所有模型使用具有Sigmoid激活函数的单个输出单元,预测标签介于0和1之间。为保证分级准确,机器预测标签和真实标签之间的平均差异必须低于0.1667。机器预测标签为预测的工作负荷等级(level of workload, LoW)
2.被试报告的平均难度,每个问题一个标签,公式转换同上。这种标签用于对比个人与群体标签的分类准确度。模型同样使用具有Sigmoid激活函数的单个输出单元,预测标签介于0和1之间。预测表现通过直方图可视化,误差分布的理想结果应是零附近的窄高斯分布。
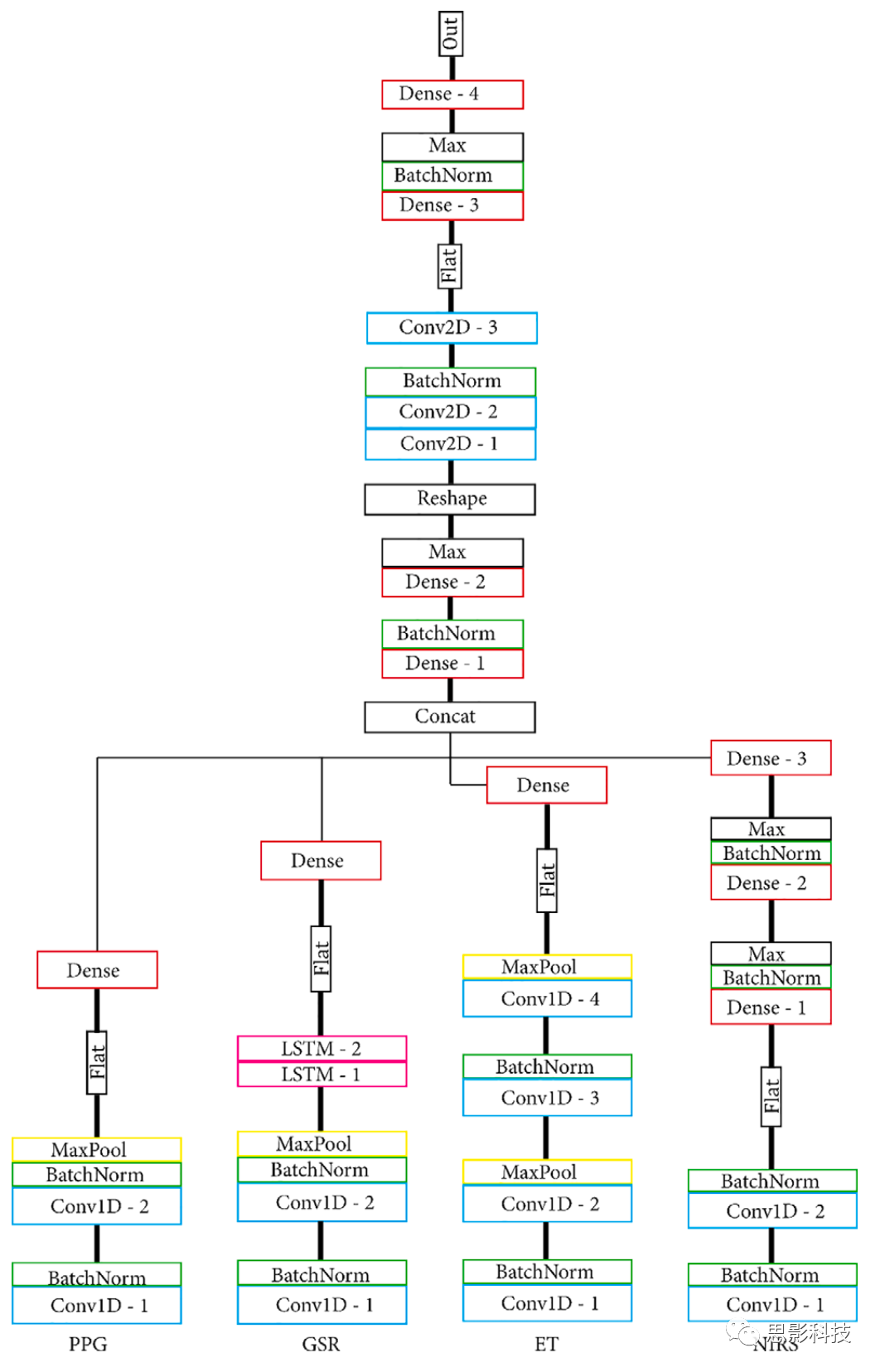
图4.(S_)LIT模型。所有MNet输入一个Head网络,Head网络融合之前MNet在单个密集连接层被展平并在低维空间中表示。
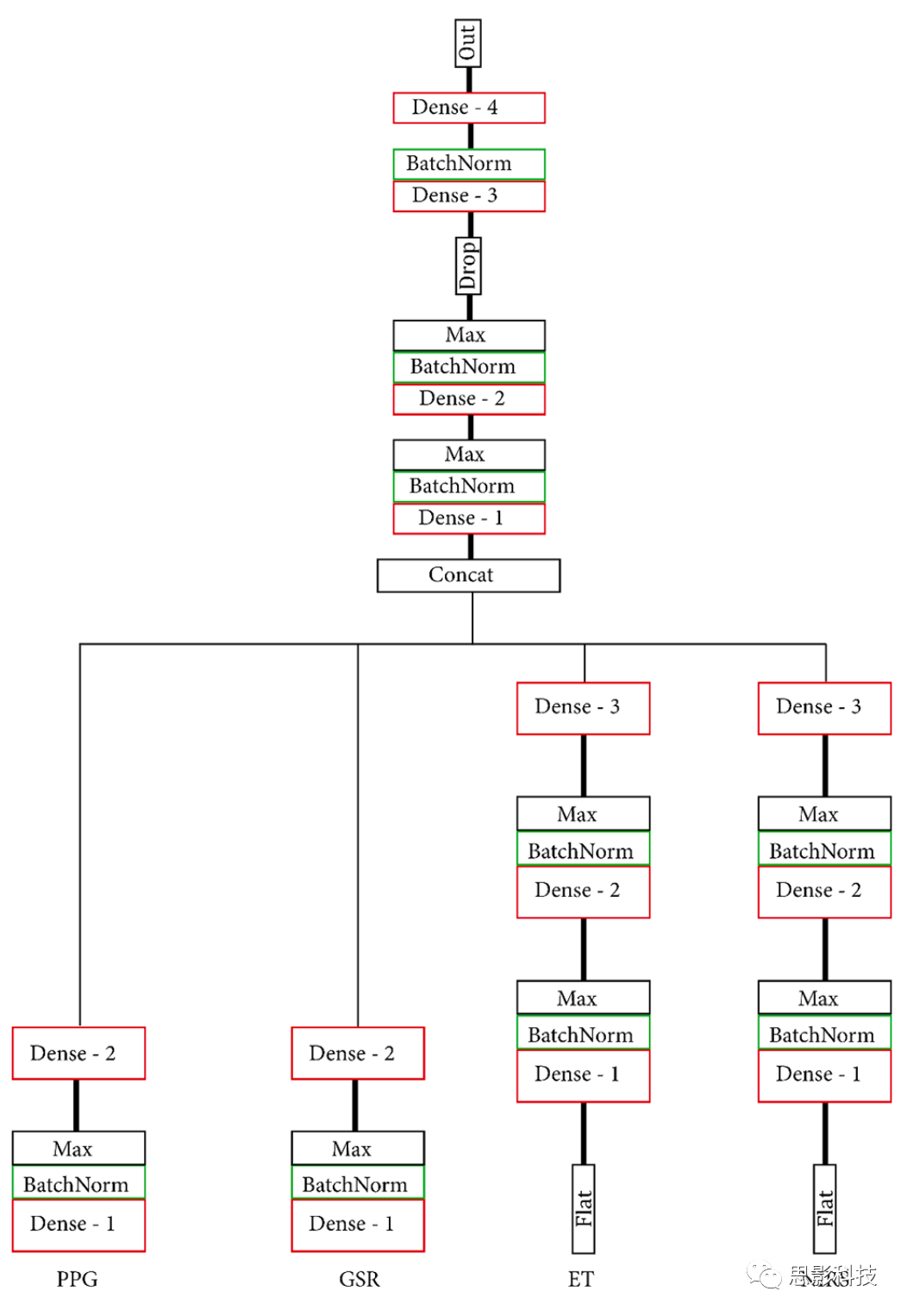
图5.(S_)MLP模型。所有MNet输入一个Head网络。MNet和Head仅由密集连接的层组成。
表1.模型、层以及每层的单元/过滤器数量。LIT指基于文献的模型,MLP指仅包含密集连接层的模型,表格显示全尺寸模型的信息,半尺寸模型每层单元/过滤器数量减半。
6.3.超参数优化
超参数的组合极大地影响了模型表现。我们使用Optuna,这是一个开源的define-by-run API,允许我们灵活、快速地设置参数搜索空间。我们使用默认的Tree-structured Parzen Estimator设置学习率、dropout和动量,使用均方误差衡量模型表现。我们共做20次trial,每个trial包含一个5折交叉验证,总数据集分成四个训练集和一个测试集。每一折都会进行不同的拆分,并训练一个新模型来防止经过训练的模型暴露。超参数优化的目标是最小化预测标签和真实标签的平均差异。进一步优化学习使用Smith描述的“1Cycle Policy”学习率策略,缓慢增加/减少金字塔形状的学习率来防止陷入局部最小值。我们使用在超参数优化期间发现的超参数训练表现最佳的模型,训练期间数据集随机拆分为90-10%的训练-测试集,所有训练均在单个NVIDIA
GeForce GTX 1080-Ti GPU上完成,更多详细信息见doi:10.5281/zenodo.4043058或GitHub1上的代码。
7.结果
7.1.数据
样本总数为4082,平均每位被试185.5个样本(77-345个)。表2中可以看到样本难度评级的分布,被试最常报告的谜题难度为5/7,其次是6/7,他们很少认为谜题是最简单(1/7)或最难(7/7)的。使用Cronbach's alpha评估标签的一致性,假设问题是测试项,alpha为0.74;假设被试报告是测试项,alpha为0.97。
表2.评级分布。第二列为被试报告7点难度等级中各难度的问题数量,第三列为不同难度问题的难度评分均值。

7.2.个体标签模型表现
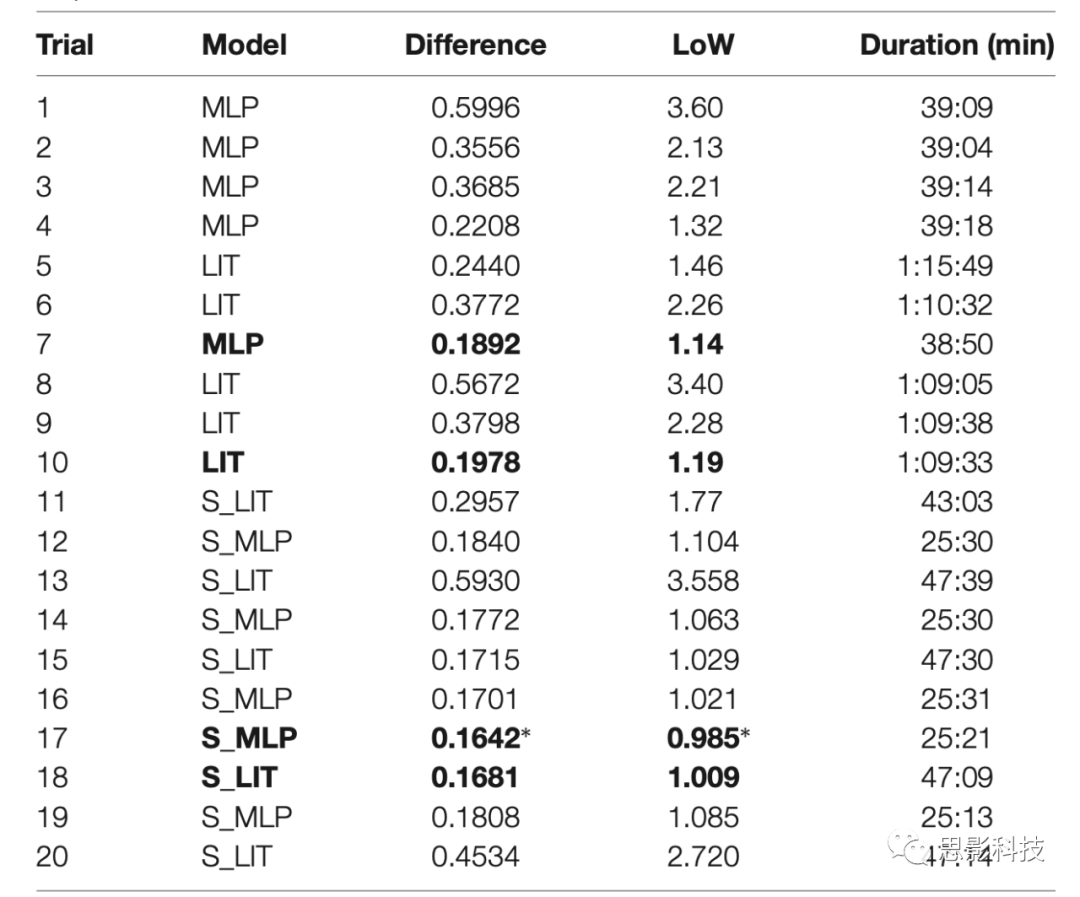
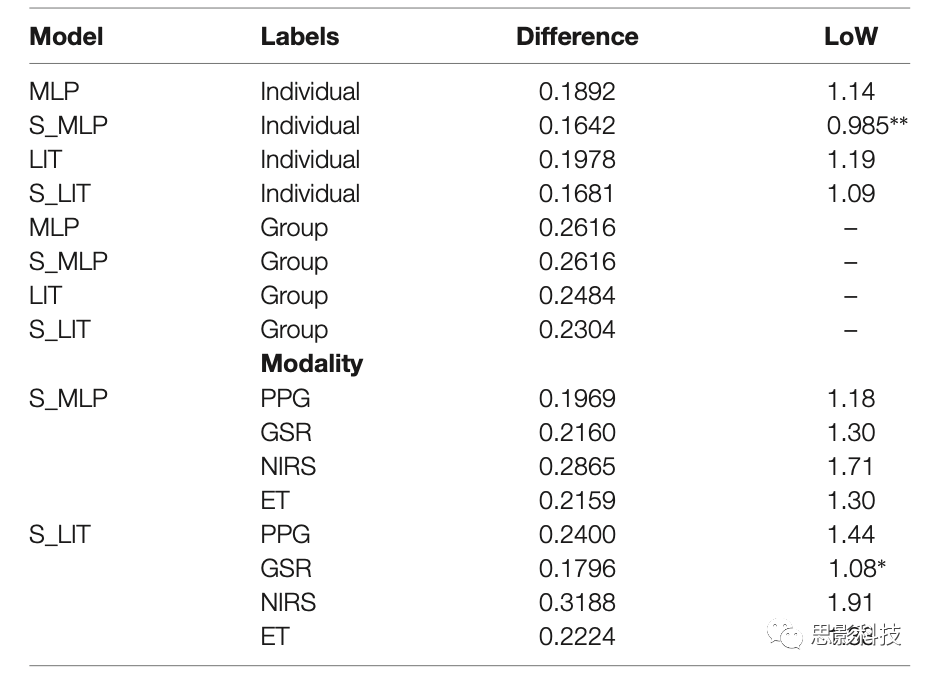
我们使用Optuna工具箱评估两组10个trial,一组使用MLP和LIT模型,一组使用S_MLP和S_LIT模型。如表3,使用MLP模型实现的最佳表现是预测和真实标签间平均绝对差异为0.1892(转换为PMWL 7点量表为1.13LoW),5折交叉验证的训练时间(每折25个epoch)约为40分钟。LIT模型的最佳结果是0.1978(1.19LoW),训练时间约70分钟。S_MLP是0.1642(0.985LoW),这也是搜索空间中取得的最好结果,训练时间约25分钟。S_LIT模型的最佳结果是0.1681(1.009LoW),培训时间约43分钟。
表3.各trial的最佳模型、预测-真实值差异、对应LoW、训练用时
如图6,表现最好的模型预测的63.6%样本在1个LoW之内,72.7%样本在1.5个LoW之内,预测和真实标签的差异分布μ = 0.033,σ = 0.233,分布的均值略大于零,这意味着模型容易高估被试的工作量。如图7,混淆矩阵显示模型最常正确分类的标签是0.6667的样本,对应难度等级为5。从混淆矩阵可以推断分类器的准确率为32%,大大高于机会水平:一个针对7个目标标签的随机分类器将正确分类14%的样本。如果标签差异正确,那么分类器的准确率为77%,随机分类器的表现为3/7(43%)。
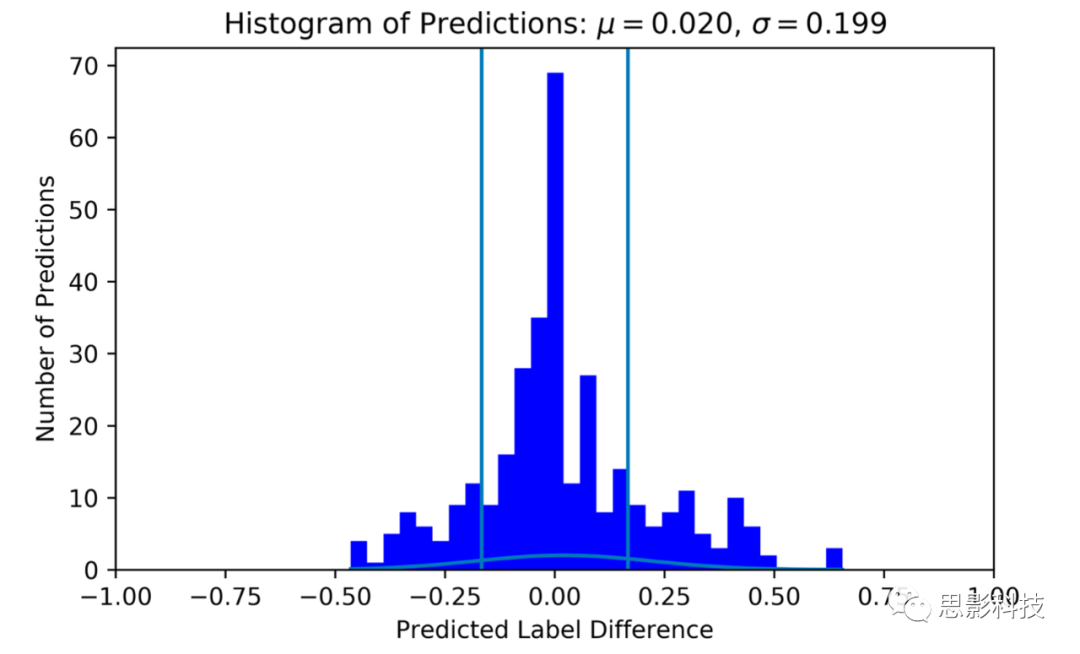
图6.个体标签的预测-真实标签差异直方图。真实标签处理为0。垂直线表示-1/6和1/6(一个LoW),超出范围的预测认为不准确。该直方图使用S_MLP与表3的trial17。
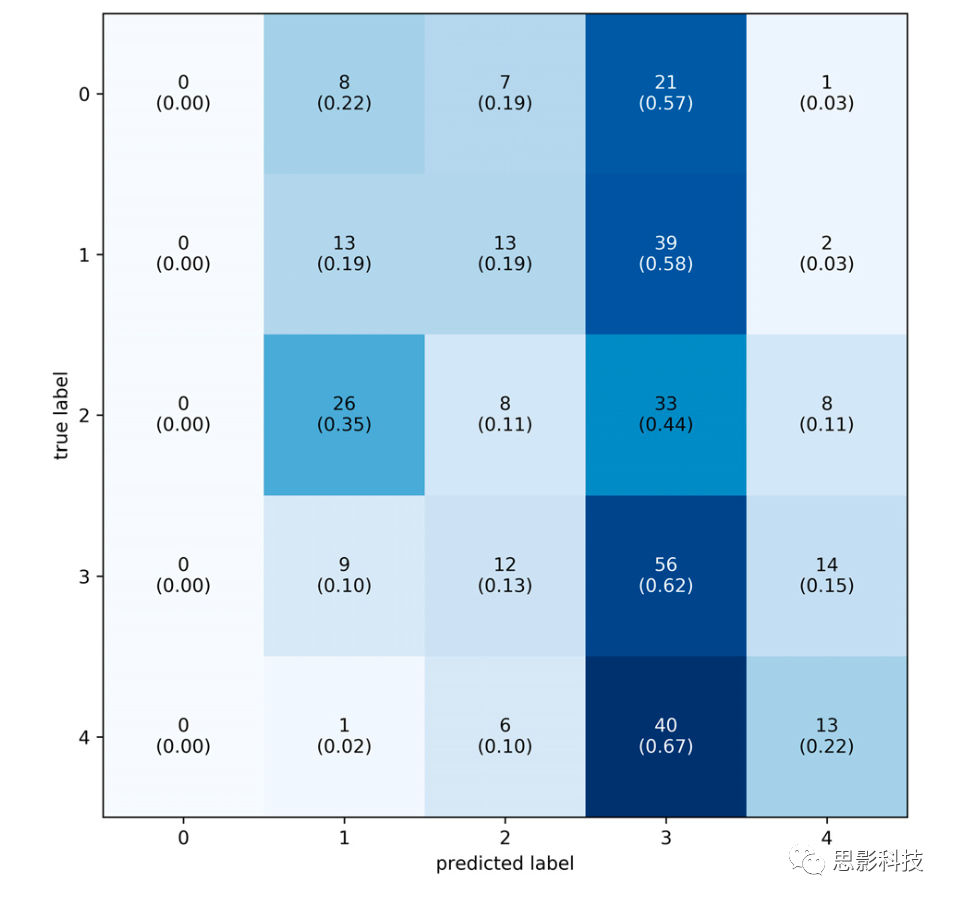
图7.个体标签的混淆矩阵。标签从0到6,共七个级别的LoW。每个方块包含预测标签次数、预测标签占比(括号)。大多数预测标签在对角线周围。
7.3.组标签模型表现
第二类组标签分为五级,取决于被试的平均评分,不等距,分布与占比见表4。与个体标签模型训练类似,使用Optuna工具箱完成了共20次超参数最优trial,结果见表5。S_LIT模型获得最好结果,真实和预测标签之间的平均差异为0.2386,如图8,分布μ = -0.055,σ = 0.284。如图9,混淆矩阵显示不管真实标签如何,该模型最常将数据分类到第四级难度。在这种情况下,分类器的准确率为27%,略高于机会水平(准确率20%)。如果标签正确,分类器表现72%的准确率。因此,组标签会降低分类器的表现,可能原因是标签中存在噪声。
表4.组标签数量与占比
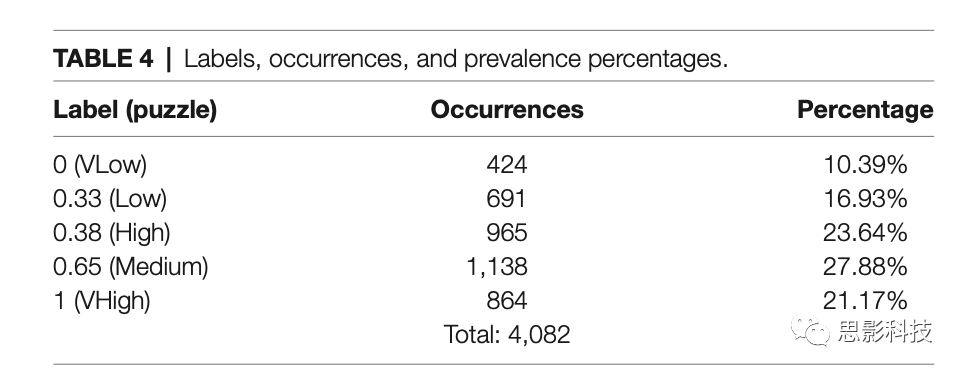
表5.各trial的最佳模型、预测-真实值差异、训练用时
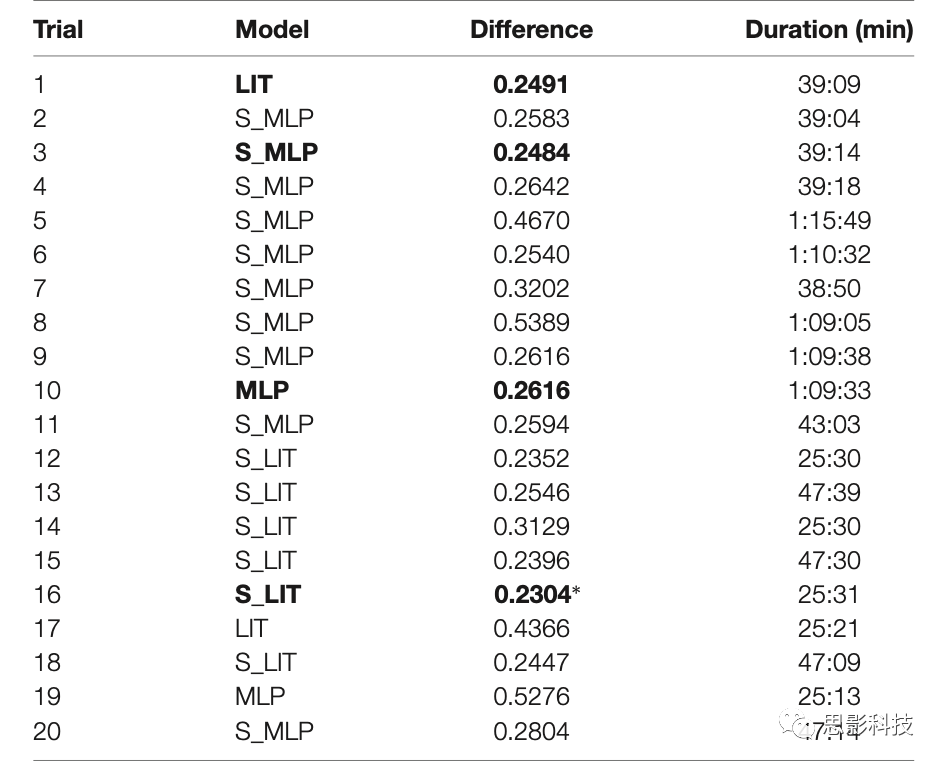
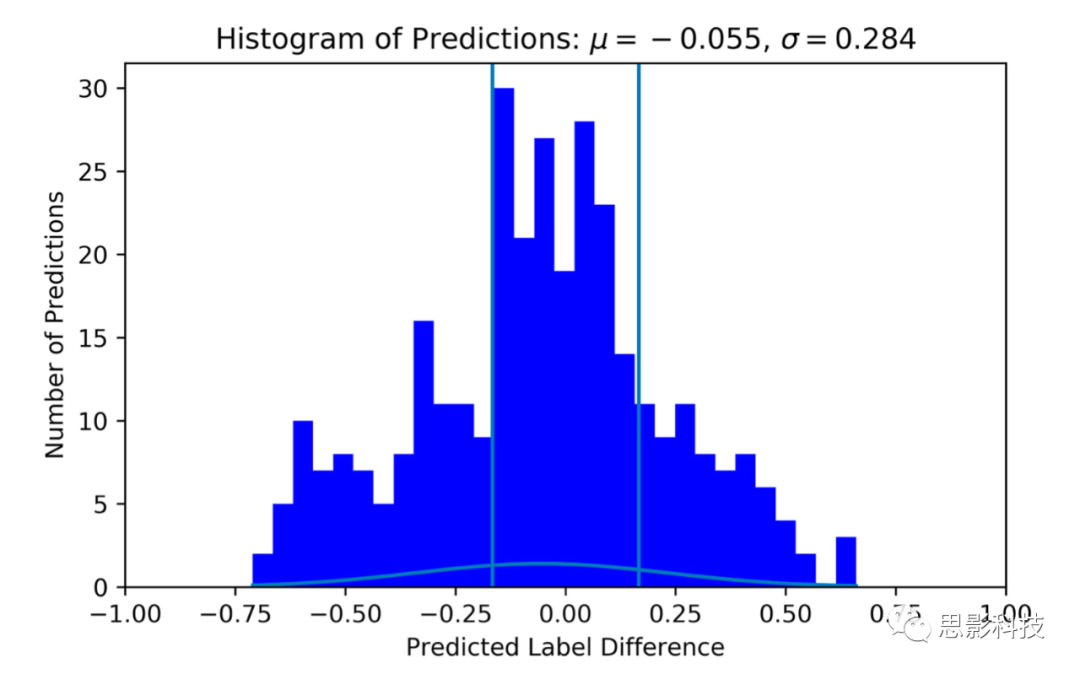
图8.组标签的预测-真实标签差异直方图。垂直线内是原始边界1个LoW,该直方图使用S_LIT与表5的trial16。
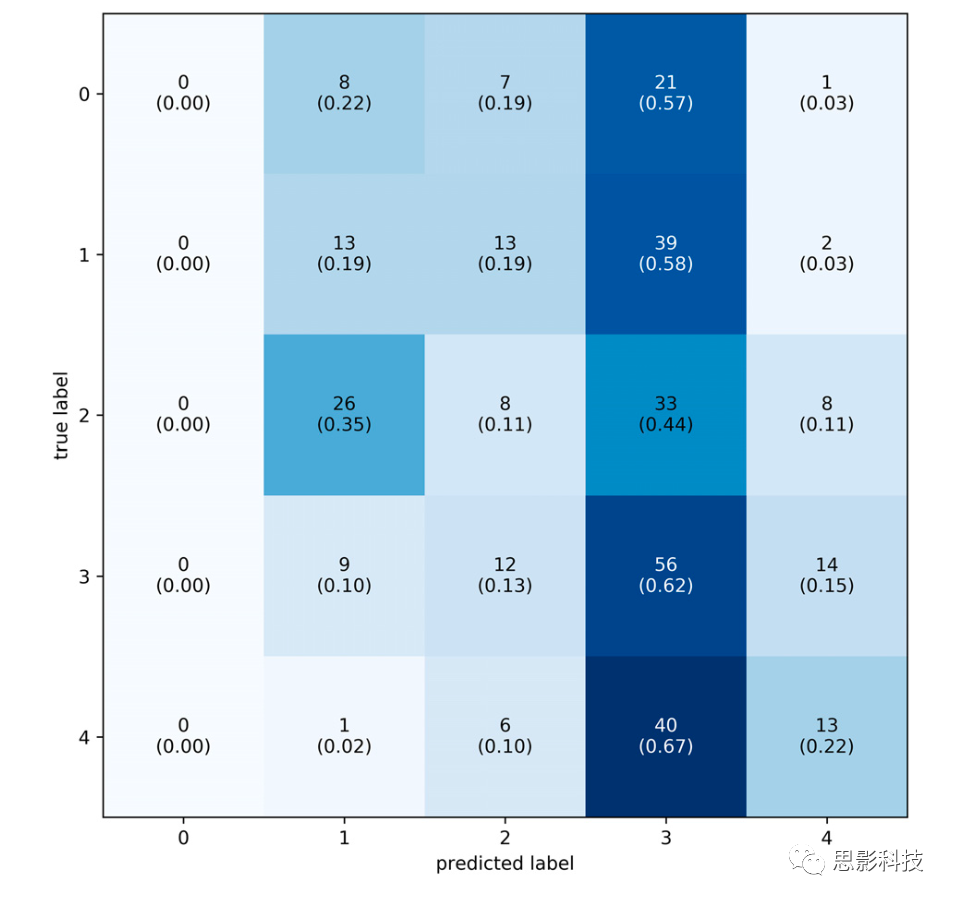
图9.组标签的混淆矩阵。标签从0到4,共五个级别。每个方块包含预测标签次数、预测标签占比(括号)。大多数预测标签在第四级难度(高难度)。
7.4.单模态的表现
为了研究附加模式的价值,我们还评估单模式的表现。所有模型使用已证明对目标模态最有效的超参数进行训练,使用个体标签。测试结果见表6,S_MLP模型中PPG表现最佳,预测与真实标签之间的平均差异为0.1969(1.18LoW)。GSR和S_LIT模型实现单模态的最佳整体表现,差异为0.1796(1.08LoW)。fNIRS模态在两种模型上的表现最差,S_MLP和S_LIT的结果分别为0.2865(1.71LoW)和0.3188(1.91LoW)。
表6.个体标签的结果
8.讨论8.1.表现
分类PMWL时,使用个体标签训练的模型表现达到7个等级的精度,这证明了IFMMoN在该场景下的有效性。直方图显示的正态分布中绝大多数点位于零附近,表明大部分预测标签接近真实标签。混淆矩阵显示IFMMoN的平均预测转换值略高于真实标签,但仍可观察到对角线趋势。该模型在第五级分类表现最好,其次是第三和第六,这也符合趋势,即更流行的标签表现更好(第二级除外)。此外,第三级虽然在样本中数量第三,但表现最差。由于样本分布,相对代表性不足的极端情况下的表现很难评估。这种分布还导致超参数优化期间表现的巨大变化,因为数据集在每一折的混洗方式不同,因此一些折叠包含了测试集中代表性不足类别的较多样本。
组标签的分类没有显著对角线趋势,无论标签是何,IFMMoN都将大多样本分类在第三级,这也是最普遍的标签,意味着IFMMoN无法在此最小化损失,可能原因在于PMWL均值不能很好地代表被试的个体PMWL,导致样本和标签之间的联系不显著。IFMMoN可能在给定个体标签的情况下学习个体生理特征,但如果标签对不同的生理特征通用,就可能无法在数据集中进行概括。未来工作可以关注个体差异的影响,模型的情感(model affectivity)以及总体表现可能因人而异,更深入地了解这些差异可以提高IFMMoN的应用性。
评估单模态,某些模态的表现明显优于其他模态。尽管本文没有直观报告,单模态分类显示出与组标签相似的趋势:所有分类集中向一个标签,这降低了单模态分类的可信度和价值。fNIRS模态的表现尤其不佳,这可能意味着数据不包含有价值的信号,或者信号处理不充分。模态表现不佳的另一个可能因素在于刺激呈现,fNIRS模态通常使用block设计,功能性MRI(fMRI)研究也如是,这两种模态本质上测量的是相同的信号。
然而,我们研究中的刺激呈现并没有遵循block设计,相反使用了更自然的刺激。刺激的“真实性”(贴近真实生活)使我们能够评估fNIRS在非实验室场景下的有效性,但也影响了条件(标签)的可区分性。我们没有针对每个单模态进行超参数优化,而是使用了相应网络的最佳参数,因此单模态的表现可能不是最佳的。
想真正证明多模态方法的优越性,我们需要在不同工作负荷范式上进行验证,例如N-back和视觉信息过载。此外,需要一种完善的统计方法来证明显著性,包括由多次测试导致的伪发现率校正。某些工作负荷情况中单模式方法与多模式方法的表现相当,这是正常的,不过超出了本文的研究范围。评估方案的MG:采用模块化设计,更改IFMMoN的配置快速、简单,这表明模块化的标准得到满足,且在研究过程中实用。由于我们能够使用所有模态获得更好的表现,因此通用性的标准也得到满足。IFMMoN似乎可以更好地概括多个生理来源的数据,因此我们认为MG标准实用且有价值。
8.2.限制
1.硬件限制,这在检查设备同步性时最明显。记录到被试数据的平均漂移为548ms(SD=590ms, 58-2827ms)。共四名被试的漂移大于1s。其中两名的原因是录制结束前软件崩溃,设备关闭。其余两名的原因尚不清楚。对某些模态(如ET),平均记录的548ms漂移影响相当大,而对于fNIRS则不那么敏感。如果将此系统与对漂移敏感的模态一起使用,如脑电图(EEG),则需要进行较大改进。一种方法是在功能更强大的计算机上采集数据,或者用多台计算机采集数据。为每个设备和流分配更多CPU可能使结果更好。特定设备的硬件限制也可能导致数据流的漂移。进一步研究漂移时也可以查看记录数据使用的软件。
2.被试数量有限。提高模型表现的一种常见方法是采集更多数据。我们总共招募22名被试,采集4082个样本。从数据集的角度来看,常用的大型图像数据库ImageNet有超过1400万张图像。当然,采集生理数据要耗时更多,尤其是使用多个设备。
3.模态的选择。目前,相关研究仅使用凝视数据(双眼的X和Y坐标)。Duchowski等人证明瞳孔活动评估认知负荷有效。将瞳孔数据纳入本研究可能导致不同的结果,大脑测量也是如此。fNIRS用于测量脱/含氧血红蛋白的相对变化,EEG也可用于预测认知负荷,在某种程度上,同样的研究可以使用不同模态,获得截然不同的结果。
4.模型架构和优化。目前,我们使用了两种IFMMoN,每种都包含大、小两个版本。小版本表现出更好的分类表现,也更有效,这可能是因为数据集的规模较小。我们没有进一步探索模型表现随着模型规格与复杂性的减小而提高的截止点。此外,超参数优化仅针对动量、学习率和dropout,而改变隐藏层、神经元的数量也可以提高表现。另一方面,结果中的模型表现估计可能较为乐观,因为应用的超参数优化在整个数据集上,而非嵌套交叉验证(即在交叉验证中对每折都应用超参数优化)。
基于mark的数据选择也可以针对模态修改。例如,与ET数据相比,标记fNIRS数据可能有所不同,因为与眼球运动相比,血流动力学响应非常缓慢,因此mark之后的数据可能包含对某些模态有价值的信息。值得注意的是,数据集/模态的更改需要重新训练网络,并重做超参数优化。如果添加了模态,则需要重新训练与新模态对应的Head和子网络。如果删除了一个模态,则只需要重新训练Head网络。本研究没有测试包含相同模态的其他主题是否还需要培训(理论上不需要)。最后,网络的输出可以编码为7维向量,每个输出给出相应标签的概率,而非0到1之间的单个数字。
5.数据采集和检索时出现了一些并发问题。由于软件会崩溃、设备连接性差,被试3、8、13和16的数据被部分排除,被试6、9、15和21偶尔展示可能与运动/深色头发有关的伪迹。不过这些数据也被包含在数据集中,目的是让系统暴露在一定程度的、也许更贴近真实生活的噪声中。
8.3.标签
被试对相同的PMWL会给出不同评级,评级完全主观,不稳定。此外,一个人在经历高工作量时可能感到自信和平静,而另一个人可能会在经历低工作量时感到有压力。因此,评估PMWL或相关的人类情感时,应该预期看到高度的误差和差异。由于本研究系统的最终目标是在自然环境中实时分类PMWL,因此我们一开始就使用自然刺激。比较分类结果,使用哪种标签方案高度影响结果,我们建议使用个体标签训练IFMMoN。
9.结论
本研究的目标是使用多模态DNN来分类PMWL。当被试解决语言逻辑题时,使用LSL同时收集GSR、PPGF、fNIRS和ET数据。我们提出一种新颖的IFMMoN,最好的模型能够在7等级上以0.985个LoW的准确度分类PMWL。基于此,我们认为IFMMoN可以使用上述四种模态分类PMWL。MG标准在研究各阶段(数据采集、数据选择、模型设计)都有指导意义。将来自各(模态)应用程序的数据流式传输到一个采集软件中,使用输入到一个Head网络的MNet中间融合来满足模块化标准;添加多种模态时改进模型表现来满足通用性标准。小模型在分类任务中取得了更好的结果。
10.未来工作
目前我们训练了两种不同标签:1.个人报告难度等级,2.所有被试的平均报告难度等级。分类不同目标会很有趣,给定一个已知的选项,可以输出一个包含被试下一步行动概率的向量,这可以预测甚至拦截错误。另一路线是训练替代任务的数据,这将深入了解管道和网络的泛化能力,有利于系统的整体鲁棒性。
该研究方向的长期展望是创建一个可以实时分类用户PMWL,并最终可以同时为多个用户进行分类的系统,然后可以引导用户提高任务的整体效率,例如通过调整环境来触发心流状态。被试也可以通过自我调节来适应环境,借助视觉、听觉、嗅觉刺激。本研究表明多模态可以准确分类PMWL,且采用的设计原则可以允许轻松添加其他模态和用户。此外,网络的尺寸也允许实时监测。该系统甚至可以检测到哪个人正在使用,这提高了系统的适应性以及集群使用模式,类似于无监督问题所做的。
10.1.数据扩展
提高模型准确性的一种有效方法是提供更多数据,以便模型更好地泛化。然而,收集、格式化、标记数据既耗时又昂贵。数据扩展允许生成新的/看不见的数据,解决数据短缺的问题。数据扩展有几种不同的选择,比如可以在输入空间、特征空间或学习特征空间中完成。输入空间的扩展涉及多次转换原始数据。在图像分类中通常采用旋转或缩放的形式,或者向图像添加噪声。对于输入和特征空间中的数据扩展,通常需要领域专业知识来确保新生成的数据匹配,生成的模型被证明能执行此类任务,且克服数据甚至模态缺失。上述示例中必须针对每种数据类型和问题专门设计新的特征提取和扩展block。
Vries和Taylor建议在学习特征空间中执行数据扩展。该方法依赖于首先学习的数据的表示,然后对这些表示执行数据扩展,假设简单扩展编码数据而非输入数据会生成更合理的合成数据。他们建议在seq2seq模型的基础上使用序列自动编码器。Vries和Taylor提出的方法与其他数据扩展方法相比有几个好处。1.与先前工作类似,特征扩展在降维中完成的,可实现轻量级。2.不用受限于特定领域的任务和输入数据,可制定更通用的参数来扩展数据,这些参数也适用于超参数优化。因此,该方法最符合MG标准,值得在未来工作中更进。
如需原文及补充材料请添加思影科技微信:siyingyxf或18983979082获取,如对思影课程及服务感兴趣也可加此微信号咨询。另思影提供免费文献下载服务,如需要也可添加此微信号入群,原文也会在群里发布,如果我们的解读对您的研究有帮助,请给个转发支持以及右下角点击一下在看,是对思影科技的支持,感谢!

微信扫码或者长按选择识别关注思影非常感谢转发支持与推荐
欢迎浏览思影的数据处理业务及课程介绍。(请直接点击下文文字即可浏览思影科技所有的课程,欢迎添加微信号siyingyxf或18983979082进行咨询,所有课程均开放报名,报名后我们会第一时间联系,并保留已报名学员名额):
脑电及红外、眼动:
上海:
北京:
重庆:
第四届脑电机器学习数据处理班(Matlab版本,重庆,9.24-29)
核磁:上海:
第二十一届磁共振脑影像结构班(上海,9.19-24)
第二十四届脑影像机器学习班(上海,10.9-14)
第三十一届磁共振脑网络数据处理班(上海,10.28-11.2)
南京:
第六十七届磁共振脑影像基础班(南京,9.15-20)
第五届弥散磁共振成像提高班(南京,9.22-27)
第三十三届磁共振脑网络数据处理班(南京,10.16-21)
第二十二届磁共振脑影像结构班(南京,10.24-29)
北京:
第六十八届磁共振脑影像基础班(北京,9.21-26)
第十届脑网络数据处理提高班(北京,10.20-25)
第十一届磁共振ASL(动脉自旋标记)数据处理班(北京,11.3-6)
重庆:
第二十五届脑影像机器学习班(重庆,9.17-22)
第九届脑网络数据处理提高班(重庆,10.13-18)
第七十届磁共振脑影像基础班(重庆,10.22-27)
第二十八届弥散成像数据处理班(重庆,11.5-10)
数据处理业务介绍:
思影科技功能磁共振(fMRI)数据处理业务
思影科技弥散加权成像(DWI/dMRI)数据处理
思影科技脑结构磁共振成像数据处理业务(T1)
思影科技定量磁敏感(QSM)数据处理业务
思影科技啮齿类动物(大小鼠)神经影像数据处理业务
思影科技灵长类动物fMRI分析业务
思影数据处理业务三:ASL数据处理
思影科技脑影像机器学习数据处理业务介绍
思影科技微生物菌群分析业务
思影科技EEG/ERP数据处理业务
思影科技近红外脑功能数据处理服务
思影科技脑电机器学习数据处理业务
思影数据处理服务六:脑磁图(MEG)数据处理
思影科技眼动数据处理服务
招聘及产品:
思影科技招聘数据处理工程师 (上海,北京,南京,重庆)
BIOSEMI脑电系统介绍