

语音是我们日常生活中最重要的声音信号。它所传递的信息不仅可以用于人际交往,还可以用于识别个人的身份和情绪状态。最相关的信息类型取决于特定的环境和暂时的行为目标。因此,语音处理需要具有很强的自适应能力和效率。这种效率和适应性是通过早期听觉感觉区域的自下而上的物理输入处理和自上而下的听觉和非听觉(如额叶)区域驱动的自上而下的调节机制之间的积极相互作用实现的。因此,交互语音模型提出对输入进行初始自下向上的处理,激活声音的多种可能的语言表示。同时,高水平的语音识别机制会对这些相互竞争的解释产生抑制作用,最终导致正确解释的激活。因此,自上而下的调节被认为改变了自下而上的语音处理。然而我们尚不清楚这些自顶向下的调制是否以及以何种方式改变了声音内容的神经表征(以下简称语音编码)。这些变化发生在皮层处理通路的什么部位也不清楚。
因此,来自日内瓦大学的研究在Nature Human Behaviour上发文讨论了这一问题。在该研究中,作者使用基于模型的功能磁共振成像,在基本声学特征(频谱时变)的表示水平上,检查听觉皮层机制对语音编码的情境依赖性。作者发现使用相同的语音执行不同的任务会导致刺激中的大脑对任务绩效相关的声学特征的神经处理的增强,这种自上而下的增强机制在听觉感知的早期阶段就已能观察到。
前言:
根据先前在动物和人类中的研究,学者们已经提出皮质的声音编码可以通过一组调制滤波器来表征。在耳蜗中的初始频率分解之后,声音在皮层下(丘脑)和皮层处理过程中就其联合频谱和时间调制内容进行分解。这种分解提供了声音的多分辨率表示。有证据表明,语音信息是在人类颞上回(STG)的多维空间中编码的。对动物的多项研究表明,主要听觉区域的神经处理的时间敏感性很灵活,可以动态适应任务需求,任务难度或联想学习。这些自上而下对早期听觉处理的影响在人脑中发生的程度仍有待探索。在人类中,已经发现了对语音神经处理的自上而下的影响,但基本是在较高处理级别的区域中发现的,例如下顶叶或额叶皮层或位于后颞上回(postSTG)和颞上沟的(听觉)关联区域中。这些针对人类的研究表明,语音处理的神经机制积极地适应任务需求、注意力和先前的语义知识。
在先前的两项研究中,研究者们发现自上而下的调制作用会依据被试在先前任务中的信息去调节声音信息在颞叶内编码的特定方面。这些声音编码的动态变化主要发生在初级听觉皮层的后颞上回、颞上沟区域或者初级听觉皮层上方的额下回区域。
然而,语音处理的交互模型预测,自上而下的机制甚至影响早期听觉词汇前的处理水平,使早期处理能够调整或放大与语音处理至关重要的声学特征。根据此类模型,可以预期,任务需求调节已经存在于早期听觉皮层区域(即颞横回(HG)和颞横沟(HS))的语音编码。然而,目前仍旧没有一致的证据表明,在主要听觉区域发现任务依赖导致的自上而下的调节所引起的激活。例如,对语音刺激执行语义分类任务对HG的活动影响最小。相比之下,其他使用模式分类技术的研究表明,在早期听觉区域中,语音唤起的反应模式受任务需求、感知和学习的调节。然而,这些后续的研究都没有将这些观察结果与语音输入的特定特征处理联系起来。
基于模型的功能性磁共振成像(fMRI)分析的最新发展可以使我们现在能够将空间分布的神经声音表征与任务要求下的特定声学特征联系起来。
因此,在本研究中,作者使用基于模型的功能磁共振成像来探究语境是如何通过人类听觉皮层调节语言编码的。具体来说,作者研究了相同语音的神经编码是如何随着语音中不同声学特征的优先处理而变化的。在高分辨率fMRI测量中,被试在相同的语音刺激(与法语音韵学相似但没有意义的假话)背景下执行语音识别(识别用于停止的辅音)或副语言信息识别(识别说话人)任务。然后,作者使用基于模型的解码方法来检测大脑在三个声学维度上编码的声学能力:频率、频谱调制和时间调制。这些声学维度对于描述语音信号中语言和副语言信息的特定方面具有不同的重要性。例如,对爆破辅音(如/p/、/t/和/k/)具有突然的频谱宽度爆发,而语音处理或说话人识别则更依赖于精细的频谱细节和音高处理。
因此,为准确执行这些任务,被试需要专注于在声音中的不同类型的声学信息。因此,作者希望通过这种方法将得到反映听觉输入动态编码的具体过程。具体而言,基于先前对语音不同方面的神经处理的发现,作者假设辨别说话者的任务将导致较高频谱调制的优先编码,而音素任务将导致较低频谱调制和更快的时间调制的优先编码。此外,作者使用基于ROI的分析,研究了跨听觉不同区域的神经编码的任务驱动调制,并评估了在早期听觉区域是否会发生这种调制。
研究方法
被试:
十三名右利手、母语为法语的成年人(6名妇女;平均年龄(s.d.)= 23岁(4岁))参加了这项研究。自我报告听觉正常和阅读能力正常,没有从事音乐家或与音乐相关的研究。研究的批准是由瑞士沃州的州伦理委员会批准的。所有被试在研究前均已签署知情同意书,并为其参与获得金钱补偿。没有使用统计方法来确定样本量,但是我们的样本量大于先前研究的报道。其他四名被试最初被包括在这项研究中,但后来被排除在外,因为两个没有完成完整的实验,另外两个在fMRI采集过程中表现出过度的头部运动(也就是说本来参加实验的人是17个)。
任务和刺激:
语音刺激包括120个假词,这些假词符合法语的语音标准,但没有意义。假词是从预选的法语单词列表中创建的,该单词列表是使用Lexique心理语言工具箱从Lexique单词数据库(http://www.lexique.org)中检索的,该工具包在遵循法语注音规则的情况下有选择地对单词中的字母进行打乱。刺激的持续时间为1,000毫秒至1,200毫秒,采样频率为16 kHz。刺激的长度范围为3至5个音节,平均为4个音节。
被试执行了一个说话人识别任务(三个目标说话者)和一个音素识别(三个目标停止辅音; / p /,/ t /和/ k /)任务,例如,向被试展示了/gabʁatadə/这个音节,在说话人识别任务中,他们需要确定相应的说话人(在此示例中为说话人2),而在音素识别任务中,他们指出了刺激中的目标音位(在本示例中为/ t /)。所有目标(特定说话者或特定音素)均等地分布在整个刺激中( n =每个目标40),并且与任务无关的目标在与任务相关的目标之间保持平衡。
例如,说话者1说出了包含/ t / target的所有假词中的13个,说话者2说出了14个假词,说话者3说了13个(同理类推,作者一共有三个音素,三个说话人,这样会形成每个人说包含这三个目标音素的最终组合都是14、13、13)。
所有三个假词只包含了三个目标中的一个音素,并且这些目标在每次刺激中发生一次或两次(发生的可能性相等)。此外,有25%的单词以目标音素开头。刺激由一位女性专业语音讲师讲出,并且为了创造出不同说话者的感觉,使用基于Audacity中实现的基于波形相似度(WSOLA)的重叠叠加技术来控制所记录假词的基本频率(www.audacityteam.org)。由于时间延长和重采样的结合,作者使用的音高移位算法最小地改变了信号的速度。
为了创建与说话者1相对应的刺激,刺激的随机子集(三分之一)的基本频率相对于原始值下移了7.5%。为了产生对应于说话者2的刺激,将另外三分之一的项目的基频下移0.01%,并且为了产生对应于说话者3的刺激,将其余项目的基频上移至下一级。与原始刺激相比,说话者2的基本频率变化听不到。这些音调变化的刺激的自然性在先前的实验中进行了研究,通过使用不同的被试验证了创建不同说话者的感知的成功程度。
功能磁共振成像测量
功能磁共振成像实验包括两个session,每个session间隔长达一周。在第一次实验之前,被试熟悉了两个识别任务,以确保他们正确理解和执行了任务。在这两个fMRI实验中,被试执行了两个识别任务。
被试通过双手按下按钮来报告他们的反应。他们只需要对暗示试验(试验的13%)做出反应,这些刺激信号是通过刺激后呈现的视觉提示来表示的(暗示试验不包括在脑成像数据分析中)。为了激发任务投入,如果被试在扫描过程中的任务绩效达到或高于期望的绩效水平(正确率为75%),则可以在两次实验结束时获得额外的奖金。所有被试都实现了这一目标。使用Sensimetrics(www.sens.com)的S14型fMRI兼容耳机以舒适的聆听水平双声道呈现声音,并调节声音强度以使其与被试感知的响度相等。
刺激分为四个不重叠的组(每组n = 30),每个组包含不同目标的平衡子集。 四组中的每组均在一个fMRI扫描中显示,并在下一个扫描中重复。在一个环节中,被试根据特定刺激执行说话者辨别任务,然后在另一个扫描中执行音素辨别任务。
每个刺激都出现了3次,并且刺激的顺序是伪随机的,因此在连续的试验中没有与任务相关的目标被重复,并且无关的目标也没有连续重复两次。一次实验总共包含八个run。每个run持续了大约8分钟,包括60次试验。被试要求被试在13%的试验中做出回应,而在12%的试验中,没有声音出现(无效试验)以增加刺激间隔。
MRI参数
使用7T西门子设备、32通道RF头阵列线圈进行脑成像。快速事件相关设计,35层重复时间(TR)= 2,600 ms;采集时间(TA)= 1,250 ms,回波时间(TE)= 20 ms,体素大小= 1.5×1.5×1.5 mm 3。作者采用了听觉实验中较为常见的长TR设计,在每个全脑扫描之间有1500的间隔,这个期间听觉刺激出现,这样可以尽可能的避免核磁扫描带来的噪声影响。扫描过程中采取了jitter的方法来随机间隔刺激,分别有两个,三个或四个TR的随机刺激间隔。最小的刺激间隔为5,100毫秒。
采集了T1结构像用于配准,采集了feildmap图用于场强校正。数据预处理使用BrainVoyager和BrainVoyager QX(Brain Innovation)分析功能和解剖像(T1)。Brain Voyager是一款商业的且成熟的核磁数据处理软件,每个模态的都有,并且基于windows的界面化处理。
单变量组对比的fMRI分析
单变量分析基于在被试的皮质表面(与基于voxel的分析不同,现在基于皮质映射的方法可以将时间序列信息映射在对应皮层的皮质表面,进行基于surface的分析,但是单变量分析的对象仍旧是时间序列)重建中重新采样的功能时间序列。作者建立的GLM模型中确定了两个contrast,分别是音素识别的条件和说话人识别的条件。
ROI的选取
作者手动标记了以下六个听觉ROI:HG(赫氏回),PT(颞平面),PP(颞极),antSTG(颞上回前部),midSTG(颞上回中部)和postSTG(颞上回后部),具体ROI的皮质概率图见图3。作者在文中很具体的描述了不同ROI的解剖位置和选择方法,感兴趣的朋友可阅读原文method部分。
文中的数据分析与结果部分基本重合,因此集中在结果部分一起解释。
结果识别任务和行为表现
在fMRI扫描仪(7T)中,被试对相同的假词执行了音素和说话者识别任务(请参见“方法”中的“任务和刺激”部分)。在说话者识别任务中,要求被试辨别听到的假词是三个说话者中的哪一个说的,而在音素识别任务中,被试听到了相同的假词,但被要求指出他们是否包含/ p /,/ t /或/ k /声音。假词用于减少词汇信息用于预测目标声音的存在并促进音素任务期间对听觉输入的依赖。为了在被试执行任务期间将声学焦点特别导向频谱信息,作者在本研究中未使用实际的人来说话。而是通过操纵一位女性说话者记录的假词的基本频率来创建三种不同说话者,从而能够以特定的频谱信息来衡量声学特征。被试对两项任务的识别成功率均高于阈值(75%),说话人辨别任务:平均值±标准误差 = 88.8%±2%,音素任务的平均±均值标准误差 = 96.5%±0.9%);然而,与不同的音素相比,被试在识别不同的说话人时更加困难(t 12 = −4.193,P = 0.001(双尾),差异(平均值±均值标准误差)= −7.7%±1.8%,95%置信区间(CI)= -11.7%至-3.71%)。在每个任务中,对不同的刺激对象的反应没有显着差异(对不同音素或者不同说话人)。
基于刺激构建的音素和说话人的调制模型
这项研究的目的是检验当不同的任务在相同的语音播放中执行时,相同的语音是否在听觉皮层中以不同的方式编码。因此,作者需要确定材料中的声音其本身的哪些声学方面对执行各自的任务最有帮助。为了做到这一点,作者使用了一个模拟皮层声音表征的模型来模拟作者设计的声音刺激。这个模型由三个维度组成,包括声音特征的频率(图1中的单位f,)、频谱调制(spectral modulation图1中的单位Ω)以及时间调制(temporal modulation,图1中的单位ω)。通过这个三个维度,可以唯一的表示每个说话人或者每个具体音素,如图1中的图所示,其中a里面上面标着speaker的是三个模拟的说话人的模型表征,其中前三个图是在通过信号变换后,在频阈上的波谱特征的变化,后三个是在通过短时傅里叶变换后的在频域上的时间信息的变化。在下面的6张图中表示了三个音素的对应的频域上的波谱特征的变化和时间信息的变化。b图中展示了标准化后的声学特征在频谱调制和时间调制上所展现出来的不同的分辨能力。从b图的第一张图中可以看出,在中心频率为0.8 kHz和2.9 kHz以上的高频谱调制)下,不同说话者的调制曲线的声学变化最为显著。从b图的第二张图可以看出:不同音素的声学特征主要表现在以快速的时间调制速率(>7.8Hz上下)和较宽的频谱调制频率(中心频率范围较宽)下的声学变化,主要表现在0.6 kHz以上的频率上。从以上的分析可以看出,说话人的声学特征变化集中在频谱调制维度,而音素的声学特征变化集中在较广频率范围的时间调制维度上。因此,作者预期在具体的任务中对神经解码的分析应该与其声学特征的表征是一致的。
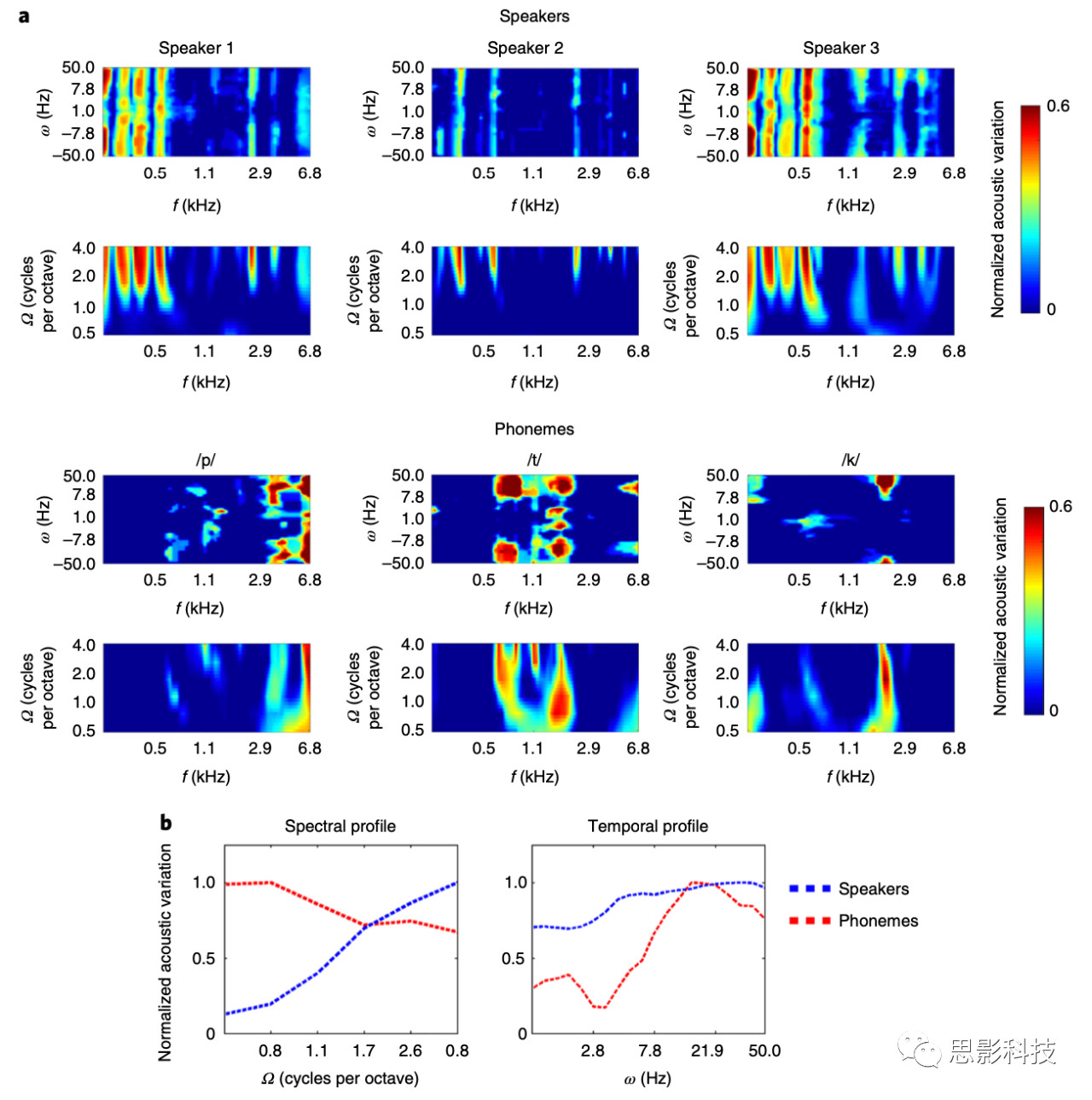
图1 三个说话人和三个音素在三个不同维度上的组合表征,a为未标准化的数据,b为标准化后的数据
听觉皮层对说话者任务和音素辨别任务的激活响应
听觉语音在双侧颞上皮层广泛区域引起显著的BOLD反应,包括HG、HS、颞平面(PT)、颞极(PP)、STG和颞上沟(STS);图2)。虽然作者的本次研究并不关注单变量分析中两种任务的激活差异,但是全脑单变量分析的结果仍旧发现,说话者辨别任务相比于音素辨别任务在右侧颞极出现了更强的激活。但是音素辨别任务并未在任何一个脑区表现出比说话者辨别任务更强的激活。这说明,只用简单的单变量分析虽然也能看到一点儿由于任务不同所带来的对相同声音刺激表现出的脑区激活的不同,但是这种对比显然不能提供更多的信息。

图2 语音任务引起的激活(这里并未对比两项任务的激活差异)
感兴趣听觉区域中语音的神经编码
通过对以往研究的分析和作者的语音激活的结果,作者确定了6个ROI,并且映射于每个被试的皮质表面重建中,分别是:HG,PT,PP,前颞上回(antSTG),中颞上回(midSTG)和后颞上回(图3;请参阅“方法”部分中的“解剖ROI的描述”部分划定标准)。在这里,作者使用每个ROI和每个半球,分别训练一个线性解码器,根据声音表示模型的定义,重构每个声音的声学特征。对声音表征模型的所有特征的组重建精度是通过一个特定于任务的调制传递函数(MTF)来完成的。在这里,我们来了解下什么是MTF,MTF全称为modulation transfer function,翻译为调制传递函数。该函数是描绘不同空间频率下成像系统细节分辨力的函数,其主要考查影像中信号的调制度相比于物体(对应于理想成像系统)中信号的调制度的降低程度。1962年国际放射界“模仿”了通讯工程学信息论的“频率调制”概念,将其以时间频率为自变量的频率响应函数,换成以空间频率(lp/mm)为变量的调制传递函数。所谓调制传递函数(MTF)即“响应函数”,可以简单理解为记录(输出)信息量与有效(输入)信息量之比。在这里,通过对fMRI这12个ROI的时间序列的信息来衡量如何表征作者在上一步分析中通过频率、频谱调制和时间调制表征的不同的声学特征。作者这里利用的线性解码器其实是使用机器学习的方法来重建一个MTF函数,用这个函数来表征这些ROI是如何特定的表征一个作者之前所建立的由三个特征所表征的不同的声音的(三个不同说话人和三个不同音素)。作者对表示每个不同声学特征的ROI的MTF进行了统计校正,然后获得每个MTF的重建精度的平均值作为后续统计检验的指标。在这两项任务中,作者指出所有刺激的声音特征可以被准确地重建为由两个维度所表征的数据——频谱调制和时间调制维度(图4)。然而,在速度更快的时间调制(>10Hz上下)和中心频率在0.5 kHz到1.7kHz之间的重构通常精度更高。结果表明,六个ROI中有五个ROI的MTF中的任务有所不同。在说话者辨别任务期间,在以下ROI的MTF中,特定说话人声音特征的重建精度更高:双侧HG,PP和postSTG,右PT和左中颞上回。在音素任务中,发现双侧后STG和右中STG的MTF内的重建精度更高。

图3 ROIs概率图
注释:ROI概率图,每个ROI用颜色编码,显示了覆盖在LH和RH膨胀的曲面重建上的被试之间手动标记的ROI。特定于ROI的色标指示所有被试中各个ROI的重叠百分比(n = 13)。
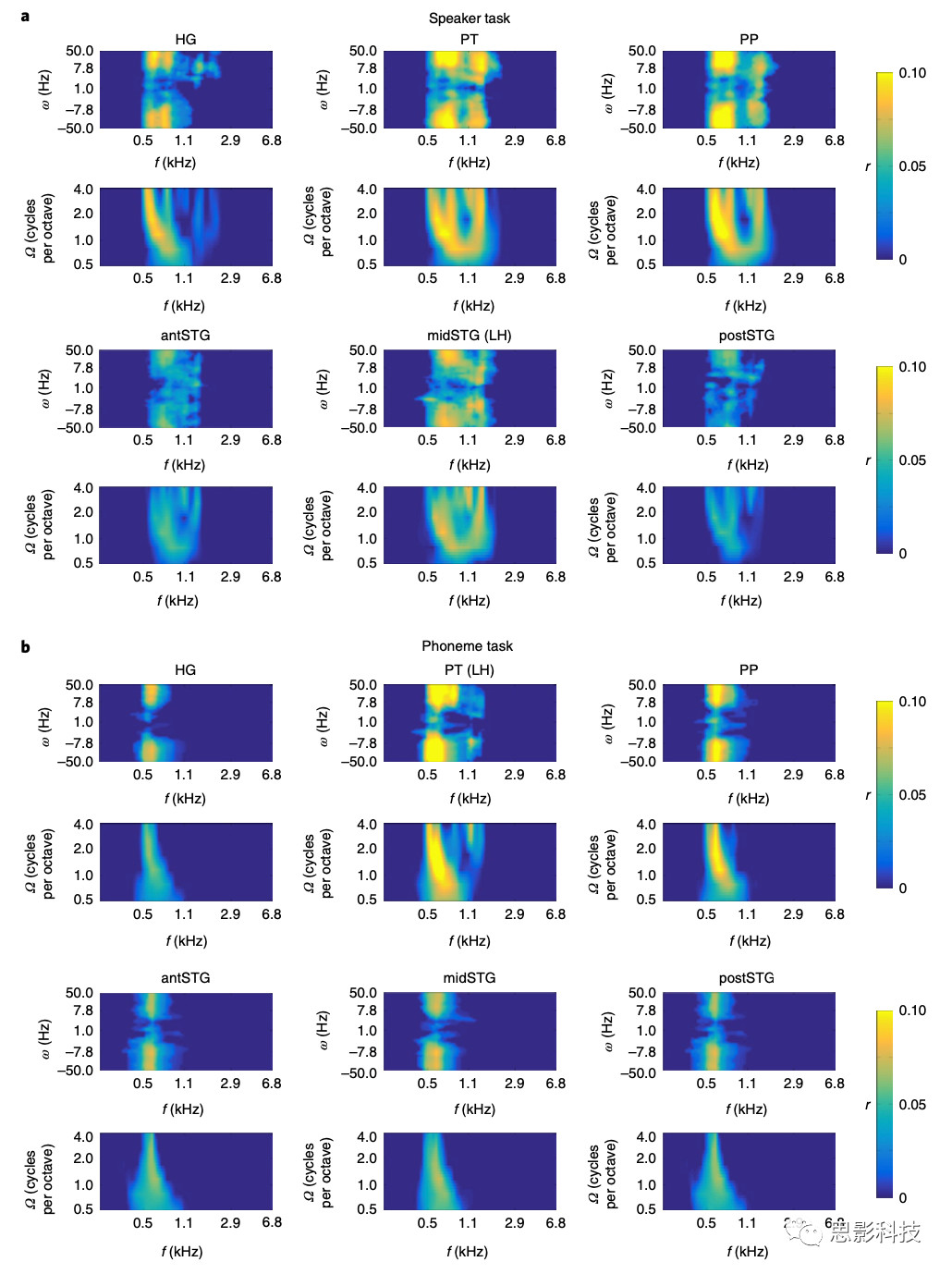
图4 说话人和音素任务期间MTF函数重建的声音表征
注释: a,b,显示了针对每个ROI在说话者(a)和音素任务(b)期间声音特征的重建精度的二维调制曲线。颜色代码表示预测的声能与声音特征的实际能之间的组平均值r。
a,在说话者辨别任务期间,发现峰值重构精度在0.5 kHz至1.7 kHz之间实现更快的时间调制(上下> 10> Hz)和更高的频谱调制(每倍频程4个周期)。
b,在音素任务期间,发现中心频率在0.4 kHz和1.0 kHz之间的快速时间调制(上下> 10> Hz)具有峰值重建精度。所有相关性均经过统计学验证。
进一步的分析结果表明,对于每倍频程1.1个周期以上的频谱调制,说话者任务期间的重建精度明显高于音素任务(Ω= 1.7:t 12 = 3.548,P = 0.004;Ω= 2.6:t 12 = 4.225,P = 0.001;Ω= 4.0:t 12 = 5.092,P <0.001;所有测试均经过Bonferroni校正后的测试数量;图6)。相比之下,在最低音谱范围内,音素任务期间的重建精度显着高于说话者任务期间的重建精度(Ω= 0.5:t 12 = -6.387,P <0.001;图6)。时间调制的结果表明,两个任务之间的精度在时间调制重建速率较高的情况下重叠,而在时间调制重建速率较慢的情况下,说话人任务的准确度明显高于音素任务(ω= 1.0:t 12 = 4.932 ,P <0.001;ω= 1.2:t 12 = 4.960,P <0.001;ω= 2.8:t 12 = 5.361,P <0.001。ω= 3.4:t 12 = 4.725,P <0.001;图6)。这些差异表明,与更广泛的语音编码相比,快速时间调制的编码更特定于音素任务。最后,作者检查了在任务中观察到的声音的神经编码中的差异是否显示出与任务性能相关的声音特征的放大。使用多种声音功能分析目标可分离性。对于每个任务,对所有正重构的声音特征进行分类,并分别对两个半球进行分类。结果发现了目标类别和任务之间的交互效应(F 1,12 = 17.714; P = 0.001),以及目标类别,任务和ROI之间的三交互效应(F 5,8 = 6.516; P = 0.011)。当分别测试每个ROI时,仅在前颞上回中发现了该任务的主效应,并且相比音素任务,对说话人判别任务具有更高的分类准确性(F 1,12 = 5.869,P = 0.032;图7b)。没有在其他任何ROI中发现任务的这种影响(HG:F 1,12 = 0.690,P = 0.422; PT:F 1,12 = 0.915,P = 0.358; PP:F 1,12 = 0.015,P = 0.904; 中颞上回:F 1,12 = 0.116,P = 0.739;后颞上回:F 1,12 = 2.162,P = 0.167;图7b).此外,作者还发现目标类别与以下ROI中MTF的识别精度相关:HG,PT,中颞上回和后颞上回(HG:F 1,12 = 26.078,P <0.001; PT:F 1,12 = 7.638,P = 0.017; 中颞上回:F 1,12 = 5.077,P = 0.044;后颞上回:F 1,12 = 15.161,P = 0.002)。在以上这些ROI中,从fMRI信号中重建的声音特征对说话人任务分类的准确度高于音素任务。在音素分类中发现了相反的情况(图6c)。这些结果表明,声音的声学表示随任务要求而变化。

图5 通过MTF重建的不同ROI的声学特征的表征模型的统计结果
注释:a,显示出任务调节效果的ROIs被叠加在LH和RH膨胀的组表面重建上。

图6 通过MTF重建的声学特征模型在频谱调制和时间调制上表现出的任务分离能力注释:a,b,说话人辨别任务(蓝色)和音素辨别任务(红色)在频谱调制(a)和时间调制上的变化。阴影区域代表SE。从图中可以,说话者任务期间,每倍频程1.7、2.6和4个周期的频谱调制的重构精度显着高于音素任务,而在音位辨别任务中,每倍频程0.5个周期的频谱调制的重构精度较高。b的时间调制模型表明,在音素辨别任务中,重建精度在较高的时间调制速率下(非显著)最高,而在说话者任务期间的重建精度在1.0 Hz,1.2 Hz的较慢和中等调制速率下较高,2.8 Hz和3.4 Hz。
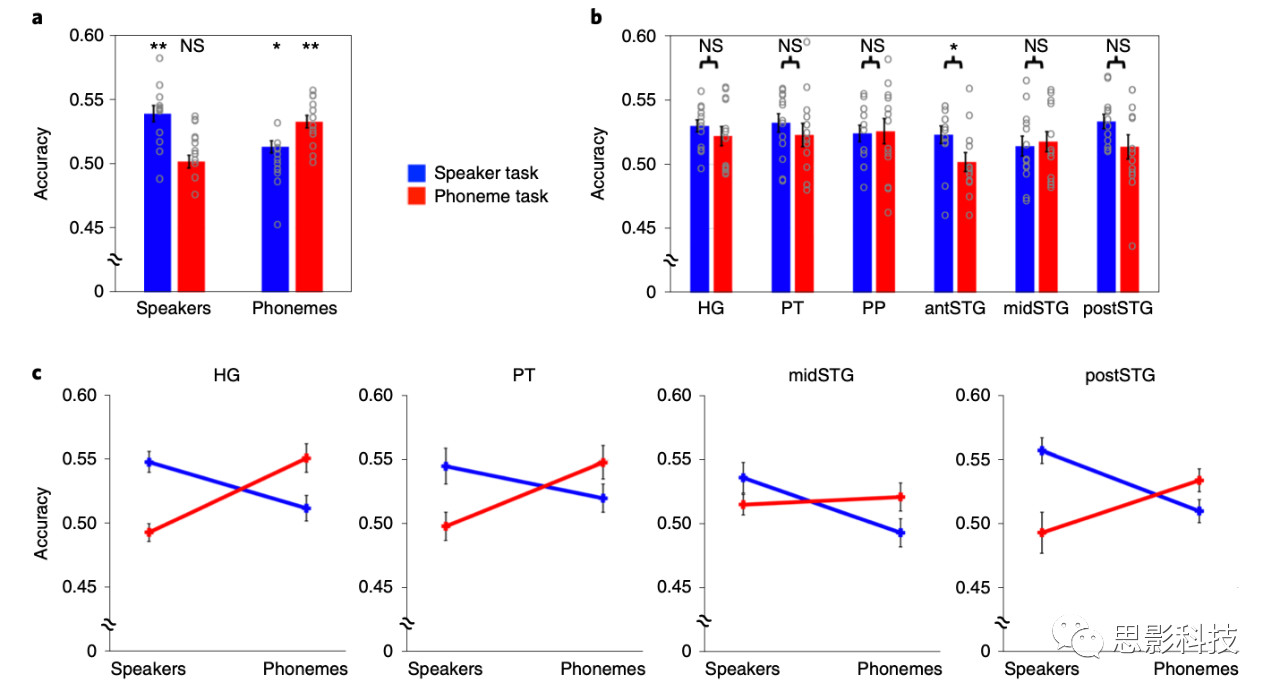
图7 通过MTF函数得到的重建精度在不同ROI对不同任务的预测能力
总结:
总之作者的数据阐明了听觉处理过程中自上而下的预测能力对听觉皮质语音感知调节的神经计算机制,提供了人脑如何在听觉环境中动态的处理语音信息的新的见解。作者发现,在相同的语音环境中,不同任务的表现会导致与任务表现密切相关的听觉特征的神经增强。这些任务效应在听觉皮层处理的早期阶段就已经出现,这说明自上而下的控制机制对听觉感官灵活地处理语音信息是至关重要的。该研究结果为人类大脑中听觉编码的灵活性提供了有意义的见解。
原文:Cortical encoding of speech enhances task-relevant acoustic information

微信扫码或者长按选择识别关注思影
如对思影课程感兴趣也可微信号siyingyxf或18983979082咨询。觉得有帮助,给个转发,或许身边的朋友正需要。请直接点击下文文字即可浏览思影科技其他课程及数据处理服务,欢迎报名与咨询,目前全部课程均开放报名,报名后我们会第一时间联系,并保留名额。
第六届任务态fMRI专题班(重庆4.8-13)
第二十八届磁共振脑影像基础班(重庆2.24-29)
第十四届磁共振脑网络数据处理班(重庆3.18-23)
第二十九届磁共振脑影像基础班(南京3.15-20)