

在机器学习研究中,特征选择是十分重要的一个环节。很多脑影像机器学习研究者更多追求的是所选特征的预测精度,而本文的作者更关注所选特征的可重复性。作者提出的基于图论的FS-Select算法,在挑选出具有可重复性特征的同时,兼顾了其预测准确性。该研究由土耳其伊斯坦布尔科技大学的Nicolas Georges 等人发表在最近的Pattern Recognition杂志上。
关键词:机器学习 特征选择 脑连接组 图论
考虑到在许多领域中(包括计算机视觉和医疗应用程序,比如计算机辅助诊断)高维度数据的增加,用于在一个给定分类任务(如区分健康和混乱的大脑状态)中减少数据维度并识别最相关特征的高级技术是必要的。尽管使用特定的特征选择(FS,Feature Selection)方法来提高分类精度的工作有很多,但是从现有的FS技术中选择最佳的方法来提高感兴趣的数据集中的特征的可重复性仍然是一个艰巨的挑战。值得注意的是,一个特定的FS方法的良好性能并不一定意味着该实验是可重复的,也不意味着所确定的特征对于整个样本来说是最优的。本质上,本文提出了解决以下挑战的第一次尝试: 给定一组不同的特征选择方法和一组感兴趣的数据,那么如何识别最具有“可重复性”和“值得信赖”的连接特征,从而产生可靠的生物标记来准确区分两种特定情况? 为了达到这个目的,研究者提出了FS-Select框架来探索不同的FS方法之间的关系。这个框架使用了一个基于每个FS方法的特征可重复效力、平均准确度和特征稳定性这三个指标的multi-graph框架。通过提取“中心”graph节点,研究者识别出了最可靠并且可重复的FS方法用于目标大脑状态分类任务,同时识别出这些大脑状态的最具识别性的特征。为了评估FS-Select的可重复性,研究者使用不同的交叉验证策略,对多视图的小规模脑连接组数据集(晚期轻度认知障碍vs阿尔茨海默病)和大规模脑连接组数据集(自闭症患者vs健康受试者)的训练集进行了扰动。他们的实验揭示了具有可重复性的表征异常大脑状态的连接特征。 介绍最近的研究表明,神经系统疾病,如阿尔茨海默病(AD)、自闭症谱系障碍(ASD)或轻度认知障碍(MCI),可以影响人类大脑的形态学连接。揭示这些神经和精神疾病的形态学连接有助于改善这些疾病的诊断和预后。为此,许多研究利用了机器学习技术以及图论分析技术找出健康的大脑和异常的大脑之间的联系。一旦这些紊乱的连接(或特征)被识别出来,它们就可以作为生物标记,从而有助于改善疾病的检测并促进有效的治疗。在生物信息学中,研究人员通常使用小样本数据,这些数据中的每个样本都具有很高的维度,这可能会导致目标学习任务的问题(如偏差)。特征选择(Feature Selection, FS)方法被认为是解决这一问题的潜在方法,该方法从感兴趣的数据集中提取高度相关的特征子集,以减少数据样本的维数,从而提高分类器的整体性能。学习如何有效且可靠地选择具有较高分辨能力的特征子集是模式识别的基本要求之一。从高维数据中选择特征的算法已经进行了广泛的应用研究。越来越多的工作延续了现有的FS(特征选择)方法,试图为他们的目标应用选择最合适的FS技术。这表明,FS方法的性能在很大程度上随输入数据集的变化而变化,因此所选择的方法会影响所产生的结果。另一方面,开发一种能够产生最佳分类结果并为所有数据类型识别最可靠特性的新方法似乎是一个棘手的问题。此外,包括为HCP(Human Connectome Project)项目收集的结构和功能磁共振成像(MRI)数据在内的多中心医学数据的不断增加,对于设计能够在不同中心数据中生成可重复的生物标记的特征选择方法提出了前所未有的挑战。这是因为每个数据源都有其独特的特征和统计分布,可能与其他数据源不匹配。因此,确定最佳的特征选择方法来揭示特定数据集的固有特征仍然是一个主要的挑战。然而,除了过去几年在设计稳健而精确的FS方法来识别神经系统疾病的可靠生物标记方面取得的进展外,还出现了新的挑战,包括实例稳定性和可伸缩性。对小数据集进行操作会不可避免地导致结果的变化。为了解决这个问题,几项研究调查了FS算法的稳定性,该算法测量所选特征对数据扰动的鲁棒性。更好的抗扰动能力将具有更好的结果一致性,从而提高了重现性。它解释了为什么一些论文甚至认为稳定性与准确性一样重要。不可否认,特别是在生物信息学中,结果需要在相同情况下的患者之间重复。每个发现的生物标记都需要是可重复的和稳定的。如果能够依赖稳定的FS方法,这种方法对于特定的数据集来说是“最优的”,并且能够检测出可靠的、可重复的生物标记,那么通过连接组数据来检测无序的大脑变化将有一个根本性的变化。他们的假设是,对于某个感兴趣的数据集,针对它的最好的FS方法对于其它不同的数据集来说,在分类精度和特征可重复性方面可能并不是是最佳的。基本上,他们在这项工作中要解决的问题是:给出了一系列不同的特征选择方法,如何识别最可重复和最可信的连接特征,从而生成能够准确区分两种特定情况的可靠生物标记? (图1)
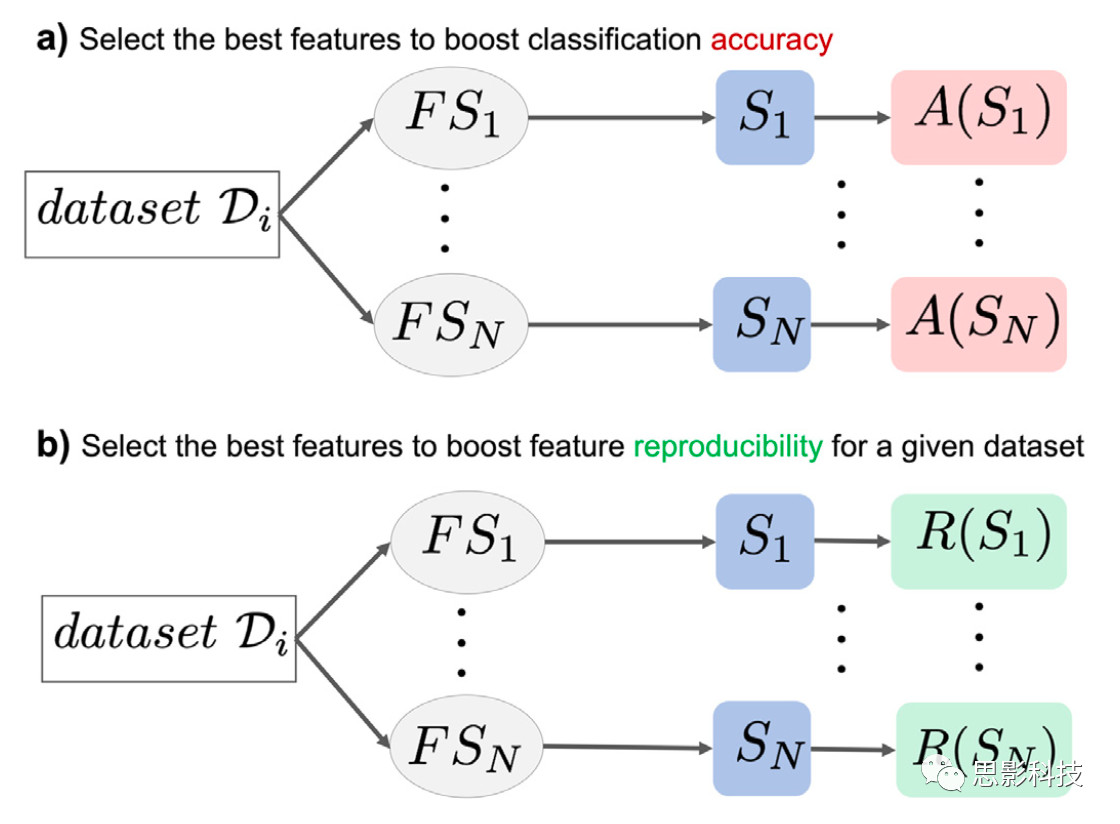
图1. 用于识别感兴趣的数据集的最佳特征选择方法的关系图。
a) 给定一个感兴趣的数据集Di和一个特征选择方法池,典型的方法是找到一个能够产生最优特征子集S的方法以生成最佳的分类精度A。然而,这忽略了特征可重复性的问题,这是在生物学和临床应用中识别可靠的生物标记的基础;
b) 研究者提出的一种基于数据驱动的方法用于识别具有最具有可重复性的特征子集的特征选择方法
相对于那些专注于提高分类任务准确率(或单独改善稳定性)的FS方法,他们的主要目标不是最大化分类器的性能,而是识别那些将会产生具有可重复性的与特定大脑疾病相关的大脑特征的最优FS方法。为此,研究者提出了FS- select框架,该框架利用multi-graph结构对不同的FS方法之间的关系进行建模,以识别最可靠的FS方法,为感兴趣的数据集找到最可重复的特征。特别地,研究者提出了三个图,分别建模每个FS方法的可重复性、平均准确率的相似性和特征稳定性之间的关系,每个FS方法对一些最佳特征进行排序(即“特征阈值”K)。最后,通过整合所有可重复性、准确率相似度和稳定性图,他们生成了一个整体图,它可以识别出与图中其他FS方法相比具有最可重复性特征的中心FS方法。在最终生成的图中,连接两个FS节点的边的权值代表了在精度和稳定性上得到平衡的特征在前K个特征的重合率。这允许识别感兴趣的数据集的“中心”节点(强度最高的节点),该节点将用于识别感兴趣的大脑疾病中最有意义和可重复的连接组特征。这个框架是简单、直观的,并首次尝试解决识别不同神经疾病的最可重复的生物标记这一具有挑战性的问题。它也是通用的,可以应用于任何数据集,以识别数据中的可重复模式。本文的贡献如下:1. 通过设计一个简单而有效的基于图的分析框架,对一组FS方法之间的多方面关系进行建模,为感兴趣的数据集识别出最可重复使用的FS方法;2. 他们提出了研究不同FS方法之间关系的重要性——在为特定数据集寻找最佳FS方法时,这方面通常被忽略;3. 将根植于社会科学领域的中心性概念引入到数据驱动的FS识别问题中;4. 它能够为感兴趣的小型和大型数据集识别最可重复的FS方法,并发现大脑疾病的连接组生物标记。
FS-Select算法框架 FS-to-FS多图(multi-graph)构建 给定一个特定的数据集,算法的目标是找出最佳的特征选择方法,提供最可重复且最可靠的特征,以便区分两类(例如,健康和异常的大脑状态)。研究者假设最可靠的FS方法能够再现其他方法识别出的最具鉴别性的特征,从而与其他FS方法达成最高的一致性。这个方法最吸引人的特点就是,它能够在一个截止阈值K(K代表用于训练分类器(如支持向量机)的排名前K个特征)上评估一个给定FS方法的重要性,同时考虑到其他的FS方法。给定一组N个FS方法,研究者构造了一个由N个节点组成的无向全连通图,其中每个节点代表一个FS方法,每两个节点之间的边描述了这两个节点之间在特定特征(可重复性、准确性、相似性或稳定性)中的关系。每个图都表示为一个相似度矩阵(图2),最终通过对所构建的三个图的相似度矩阵进行平均,得到最终的FS-to-FS相似度矩阵S。FS-to-FS 特征可重复性矩阵构建 给定一组N个FS方法F={FS_1, ..., FS_n},可以构造一个图G_k = (V_k, E_k)。V_k为节点集,每个节点代表一个FS方法,E_k为带有权重的连边,表示成对方法之间在前K个特征上的重合度。每个图G_k表示为一个相似矩阵S_k(图2)。通过改变阈值K,研究者定义了一组图G(或称为multi-graph)来模拟不同阈值条件下FS方法之间在前K个特征上的重合度。接下来,为了合并生成的多图(multi-graph),研究者将每个G_k表示为一个相似矩阵S_k(图2),其中每个元素S_k (i, j)表示FS方法i和方法j之间在前K个特征的重合度。最后,研究者通过平均合并在所有阈值K下生成的相似度矩阵后得到一个平均相似度矩阵S_bar。FS-to-FS准确率相似度矩阵构建 由于分类精度将影响所产生的特征的可信度,研究者提出了基于平均分类精度相似度的方法来建模FS方法之间的关系。研究者定义了一个平均准确率相似度矩阵A_bar,其中A_bar(i, j) 代表每两个节点之间的准确率相似度。A_bar(i, j) = exp(-|a_i - a_j|/σ_A), 其中a_i表示在不同阈值K下的平均准确率。在之后的实验中,σ_A被设置为10用于数值范围的归一化。FS-to-FS稳定性矩阵构建 一个性能良好的分类器并且具有较好的全局分类精度是很重要的;然而,在处理生物标记时,可重复性是至关重要的。分类结果必须对每个被试都是有效的。一些研究强调了FS方法的稳定性对于特定的FS方法结果可重复性的重要性。一种可以更好地识别特征可重复性的方法是进一步利用稳定性评分,该评分能够建模FS方法所选择的特征的鲁棒性。类似于通过平均不同阈值下的multi-graph来构建S_bar的过程,研究人员构建了矩阵K_bar。K_bar是通过平均在不同阈值下的稳定性矩阵得到的。稳定性矩阵K_bar中的每个元素K_bar(i, j) 表示方法FS_i与方法FS_j之间的归一化Kuncheva 稳定性得分。最终,FS的相似度矩阵通过对上述方法计算出来的矩阵进行逐元素相乘得到, 即:S=A_bar x S_bar x K_bar。 识别最具有可重复性的FS方法 在图论中,可以使用中心性度量来确定图中节点的重要性。节点中心度的概念旨在量化图中节点的重要性。有趣的是,在社会网络分析领域之外,这个概念还没有被广泛探索。节点中心度是度量图中节点相关性的有力工具。为了解决这一问题,研究者将所谓的图中心性引入到最可重复的FS方法的识别过程中。具体来说,算法在估计的FS邻接图矩阵S上使用中心性度量,同时考虑到FS方法在可重复性方面的重要性。FS方法在阈值K上可重复度的定义 研究者将特征选择方法FS_i在阈值K上的可重复性定义为与其他的特征选择方法FS_j在前K个特征上的平均重合率。FS方法平均可重复率的定义 特征选择方法的FS_i的平均可重复度定义为该方法在多个变化的阈值K上计算得到的多个可重复度的平均值。研究者使用“平均可重复率”的定义来量化一个给定的FS方法的可重复效力。较大的度中心性表示中心节点与周围的邻居节点紧密相连。在本文中,这表示与其他度节点享有更大数量的特征(比如较强的连接)的FS方法具有更强的可重复效力。这也意味着,在生成的加权图中具有最高节点中心度的节点代表着最具有可重复性的FS方法。 因此,为了识别最具有可重复性的FS方法,算法识别在图S中具有最高的中心度的节点v:
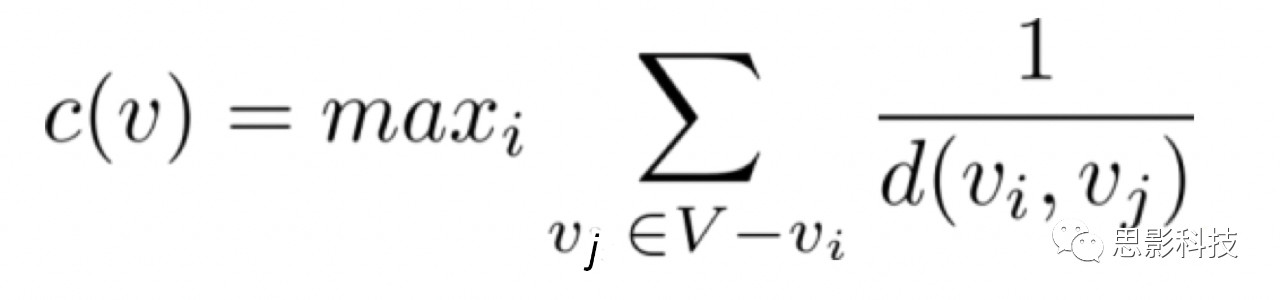
其中,d(v_i, v_j) 表示节点v_i 与节点v_j之间的最短距离。两个节点之间的相似度可以通过计算两节点间的距离的倒数得到。受图论分析理论的启发,研究者将c_i定义为中心性度量,这一度量表示在一给定长度的路径上访问FS方法的次数。具体来说,研究者为S中的每一个节点FS_i分配一个c_i分数,c_i量化了FS_i与其他方法在重复性、稳定性和准确性等方面的一致性。最终被选择的FS方法是S中具有最高中心的节点(同时也是与其他FS方法连接最紧密的方法)。 识别最具有可重复性的连接组特征 一旦识别出最可靠的FS方法,算法就使用前K个选择的特征训练支持向量机分类器,以发现最具鉴别性的特征。然后,通过使用circular图绘制最相关的连接特征来更深入地研究可重复性特征,circular图还显示了最佳FS方法的名称及其对该特定数据集的平均精度(图2)。 使用不同的交叉验证策略对FS-Select方法进行验证 为了评估FS-Select算法的可重复性并更好地评估其有效性,研究者使用P折交叉验证(CV)策略训练了一个线性SVM分类器。为了说明FS方法在三个标志性特征上的相似性(例如,可重复性、准确率和稳定性),研究者构建了矩阵M_b和矩阵M_w(图2)。第一个矩阵M_b中的每个元素表示在两个不同的交叉验证p和p’之间前K个特征的重合率:
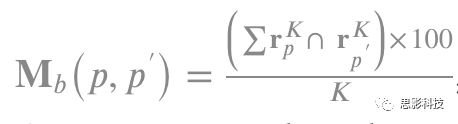
其中r^K_p表示第p个交叉验证中FS方法在前k个特征的序列向量。为了生成稳定性矩阵M_w,研究者首先识别出在交叉验证策略p和p'之间的前K个特征,然后平均由CV p和p'生成的排序分数w^K_p和w^K_p’,从而生成矩阵M_w(p,p’)。
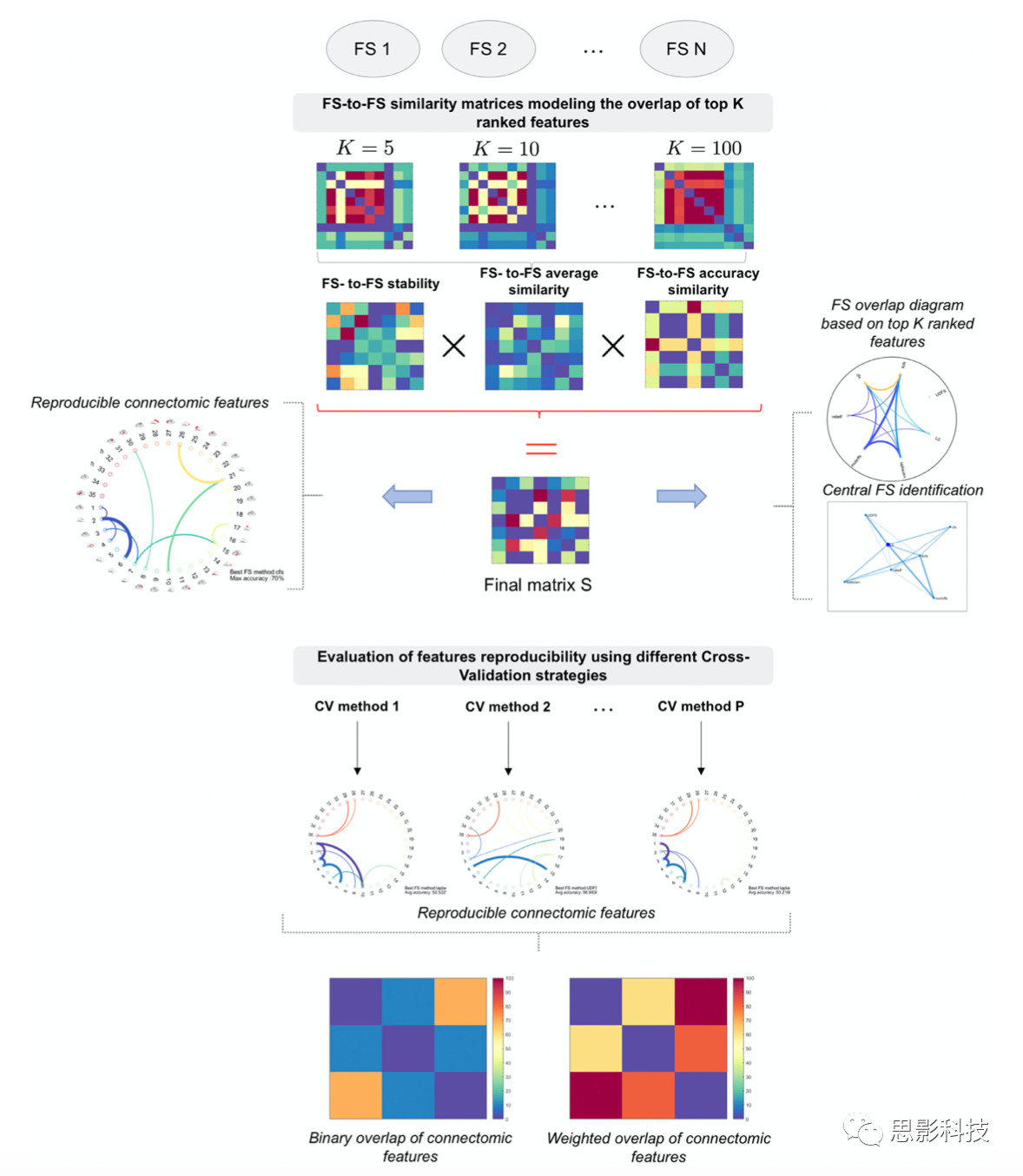
图2.提出了用于数据特征选择方法识别的FS-Select算法框架。给定一个特定的数据视图,研究人员定义了多个图,每个图都表示为一个相似矩阵,对数据特征选择方法中排名前K位的特征的一致性进行建模。
结果及讨论
验证数据集
研究人员在小规模脑连接组数据集(晚期轻度认知障碍vs阿尔茨海默病)和大规模数据集(包括自闭症患者vs健康受试者)上评估了FS-Select算法,如下所示。多视图连接组特征提取 每个被试的脑网络由一组包含n_v个网络的集合{V_i}(i=1,2, … ,n_v)表征,每一个网络编码了大脑连接组的一个特定视图。为了训练基于所挑选的FS方法的分类器模型,研究人员为每一个视图的脑网络V_k定义了一个特征向量v_k,特征向量v_k上的每个元素都属于相应的连接矩阵的非对称上三角部分(图2)。小数据集 为了区分阿尔茨海默病(AD)患者和晚期轻度认知障碍(LMCI)患者,研究人员对来自ADNI data的77名受试者的数据(41名AD患者和36名LMCI患者)进行了留一交叉验证,每个受试者都有T1w核磁共振影像。他们使用FreeSurfer软件从每个被试的T1w像中重建其左右大脑皮层。接下来,他们使用Desikan-Killiany 模版将每个半球划分为35个皮层区域。从而生成了两个大脑形态学网络,并得到两类皮层属性(视图):最大主曲率和平均皮质厚度。对于每个皮层属性,研究人员将每两个ROI之间属性值的差的绝对值作为形态学网络中每两个ROI之间的连边强度。然后,他们通过提取连接网络的非对称上三角部分作为网络的特征向量。大数据集 为了验证算法的通用性和可扩展性,研究人员在大数据集上对FS-Select算法进行了评估。该数据来自ABIDE数据集,包括341名被试,其中155名被诊断为自闭症谱系障碍(ASD),以及186名正常被试。这个数据的多视图形态学脑网络和相应的特征向量的构建方法与上面提到的方法是一样的。
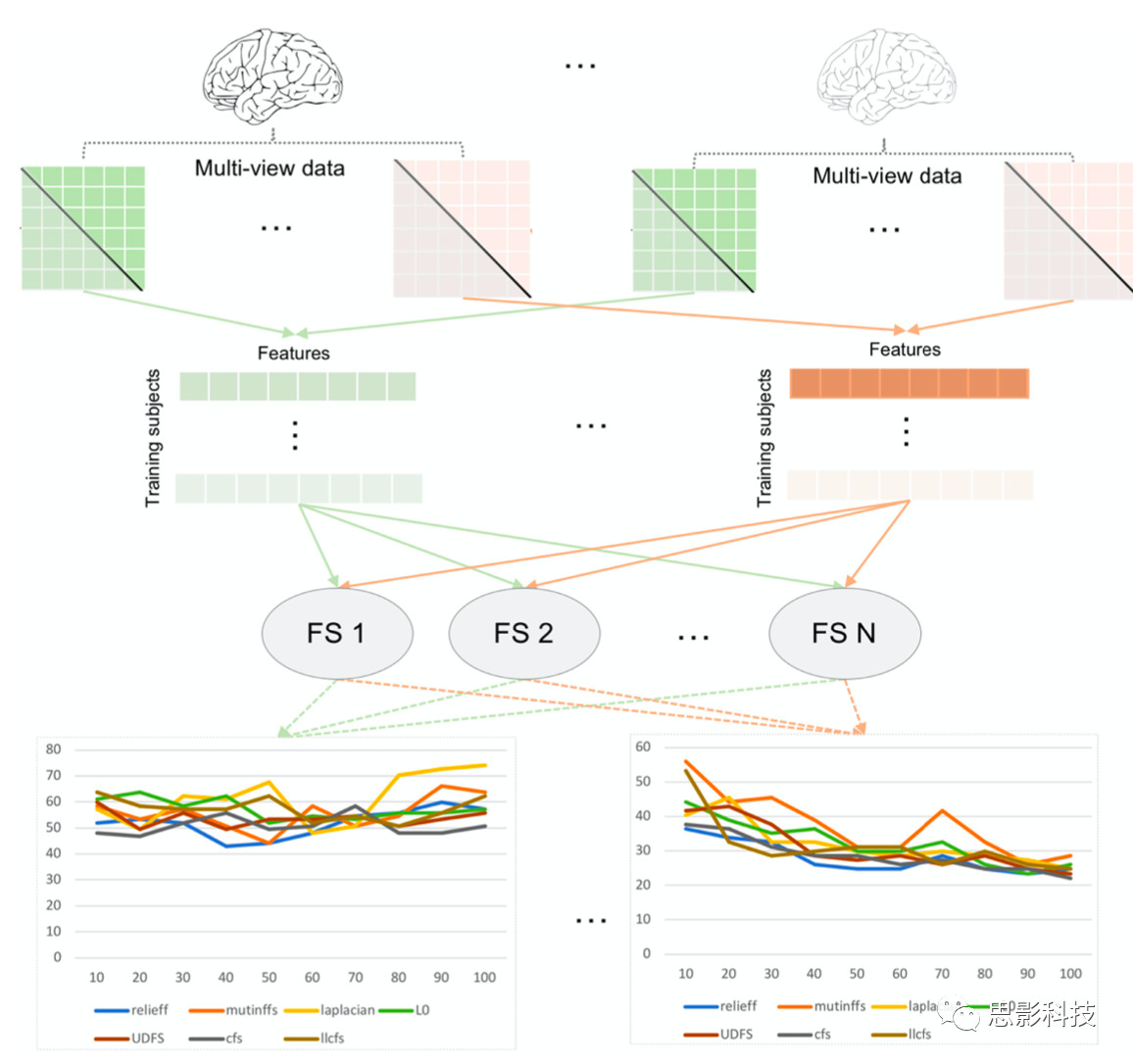
图3.特征选择方法在不同数据集上的性能波动。对于每个被试,研究人员定义了一个连接特征向量,每个特征向量来自于特定的大脑视图。因为每个大脑连接矩阵是对称的。忽略掉自连接,只对每个矩阵的非对角上三角部分进行矢量化特征提取。他们在不同的数据集上使用留一交叉验证和七个特征选择(FS)方法来训练支持向量机(SVM)分类器,每个数据都来自大脑连接的特定表示(或视图)。右边的图展示了视图一(最大主曲率)中,在不同数量的选择特征下7个FS方法的分类准确率,左图则表示视图二(平均皮质厚度)中7个FS方法的分类准确率。他们注意到,不同的FS方法的性能随数据类型的不同而不同。
实验设置FS方法和训练
为了构建FS方法池,研究人员使用了Matlab提供的Feature Selection Library。他们选择了7种FS方法:relieff、MutInfFS、laplacian、L0、UDFS、llcFS和cFS,并采用留一交叉验证策略,结合SVM分类器训练每个FS。对于需要参数调优的FS方法,他们使用了嵌套的交叉验证策略(relieff, UDFS)。对于每个FS方法,他们评估了SVM分类器在不同数量的前K个特征上的性能,这些特征的数量从10到100不等(步长为10个特征)。实验结果初步证实了之前的假设:一种特定的方法在不同的数据上性能是不一样的(如图三)。接下来,文章将继续讨论不同FS方法之间的排名差异,并确定能够产生最具有可重复性的特征以及总体上令人满意的准确性和稳定性的方法。 FS-Select性能表现小数据集(晚期轻度认知障碍vs阿兹海默症)图4给出了加权FS相似矩阵及其对应的图,以及FS- select识别的可重复特征。该图证实了之前的假设,即一种数据类型的最优的FS方法对另一种数据类型可能不是最优的。如view1 LH连接组数据上最优的FS方法为relieff,它的分类准确率为61.03%;view2 LH连接组数据的最优FS方法为L0,它的分类准确率为70.3%,如图4所示。

图4. FS-Select算法在小数据集(AD vs LCMI)上的表现。
此外,研究者还注意到两个半球之间的准确率有显著差异(≈70% vs ≈40%)。最具有判别能力的形态学特征包括这些形态学连接:(i)[顶叶皮层↔脑岛皮层]和(ii)[尾前扣带皮层↔胼胝体]。ROI(尾额中回↔胼胝体)和[胼胝体↔楔片皮层(5)]经常被选中。颞上沟(1)、前扣带皮层(2)和岛叶皮层(35)也被认为是形态学网络枢纽(hub)。大数据集(自闭症谱系障碍vs正常被试)图5展示了算法在大数据集上的结果。首先,注意到算法所选的四种FS方法是不同的(laplacian、relieff、cfs、mutinffs),因此算法似乎不依赖于大脑网络连接视图。同样,没有注意到在跨视图的准确性上有显著的差异(对于所有视图≈52%)。当观察这个数据集中最具有可重复性的特征时,形态学连接[顶叶皮层(29)↔脑岛皮层(35)]总是被发现;[尾前扣带皮层(2)↔胼胝体(4)]和[颞上回后坡(1)↔内嗅皮层(6)]作为相关特性出现。同时研究人员还注意到,为ASD识别的最具鉴别性的特征不同于为AD数据集识别的特征。总的来说,这可能表明FS-Select能够为特定的数据集选择与其相关的连接特征。

图5.FS-Select在大数据集(ASD vs NC)上的表现。
使用多种交叉验证策略评估FS-Select方法 FS- select从给定的FS池中识别出最佳的FS方法,并能够找出在感兴趣的生物医学数据集中分离两个类的最具有可重复性和最具鉴别性的特性。然而,目前在生物医学数据分析领域,对于如何评估基于机器学习的特征的可重复性还没有达成共识。作为一个潜在的评估标准,研究者利用不同的交叉验证策略来证明特征的可重复性,以应对训练集的不同扰动。特别地,他们使用三种CV策略来应用FS-Select: 留一交叉验证、五折交叉验证和十折交叉验证。根据图6和图7所示的结果,他们的目标是突出FS-Select的两个关键方面: 1. 稳定性对结果的影响(即,选择的FS方法和识别的连接特征); 2.通过探索在不同的交叉验证情况下识别出来的特征的重叠率确定其可重复性。识别出最具有可重复性的脑形态学连接来区分阿兹海默症(AD)与晚期轻度认知障碍(LMCI)。FS-Select识别出cfs是最重要的方法,因为在所有实验中cfs被选中的次数达到50%。如图6所示,circular图显示了区分AD和LMCI之间最具有可重复性和最具有判别力的形态学连接。在三种交叉验证策略中出现最多的形态学连接特征包括:(尾前扣带皮层(2)↔胼胝体(4))和[顶叶皮层(29)↔脑岛皮层(35)],这些发现与之前发现的具有一定的相似性。从图7所示的交叉验证相似度矩阵中,可以注意到留一交叉验证与十折交叉验证策略在十个最具有判别性的特征的方面有最高的重叠率(100%)。识别出自闭症谱系障碍(ASD)和正常被试(NC)脑状态之间最具有可重复性的脑形态学连接。在这个数据集上,cfs方法只被选中一次,relieff和laplacian经常被选中。图6显示(顶叶皮层(29)↔脑岛(35)]在不同的交叉验证策略中是具有可重复性的连接特征。在考虑稳定性时,连接颞上回后坡(1)与内嗅皮层(6)以及尾侧额中回(3)的连接被认为是最具判别性的。当不考虑稳定性来产生最终的S矩阵时,可以观察到区域1(颞上回后坡)不常被选择。相反,第2区(尾侧前扣带皮层)出现的频率更高。如果不考虑稳定性,并且只选择一次更多的节点,并且图看起来不那么相似,则会重现相同的模式。考虑进稳定性将倾向于增加在多个交叉验证策略中所选择的特征的数量。总的来说,所显示的circular图看起来更相似,它们有更多重要的共同特征。从交叉验证相似矩阵来看(图6),他们可以得出结论, 由十折交叉验证以及留一交叉验证识别出来的最具有可判别性的形态学连接是最具有可重复性的,这是因为留一交叉验证与十折交叉验证在所有成对的交叉验证中显示出了最高的重合度。
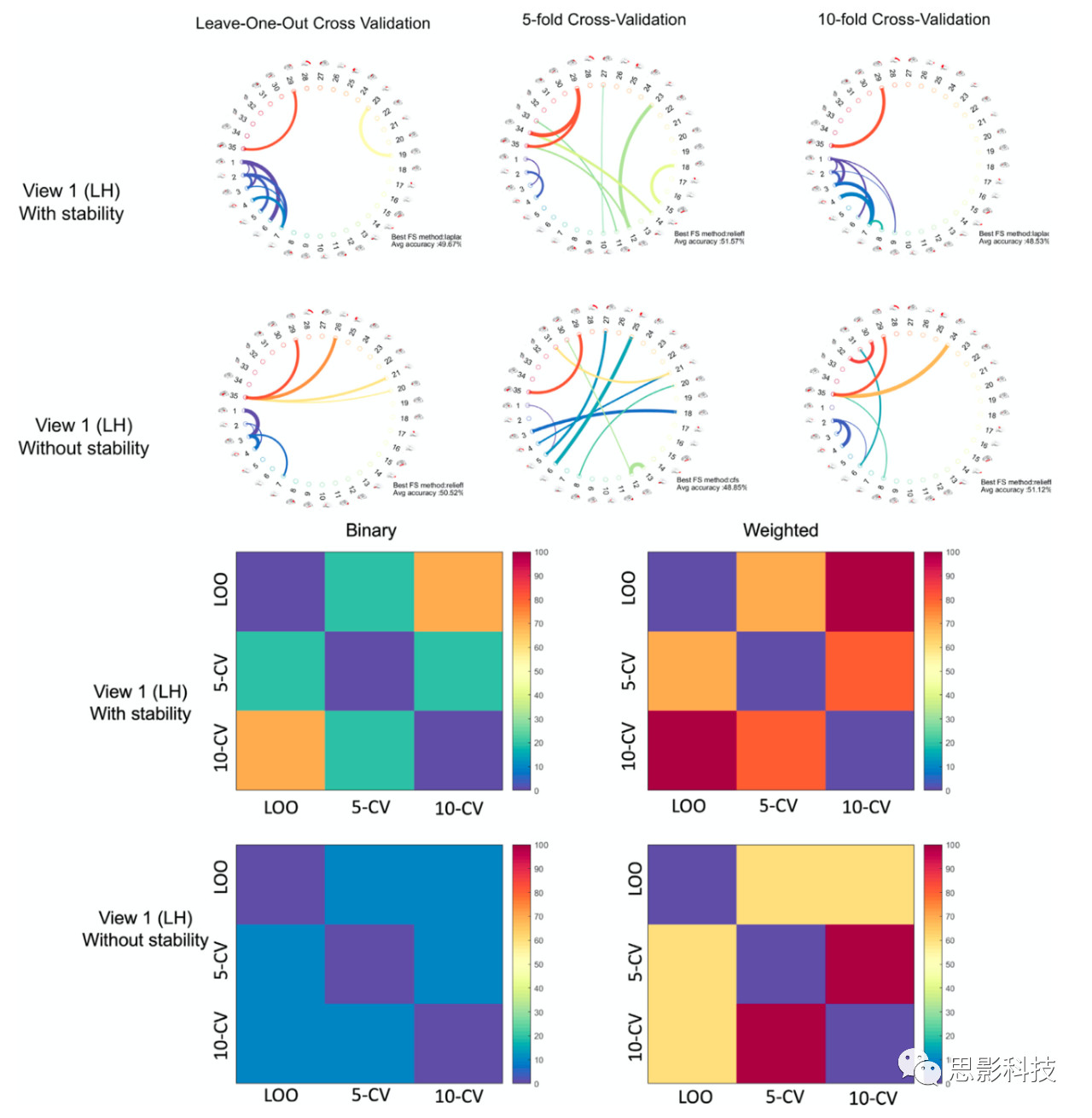
图6. 在AD vs LMCI数据集上,不同的CV方法得到的可重复性特征以及CV-CV相似度矩阵。
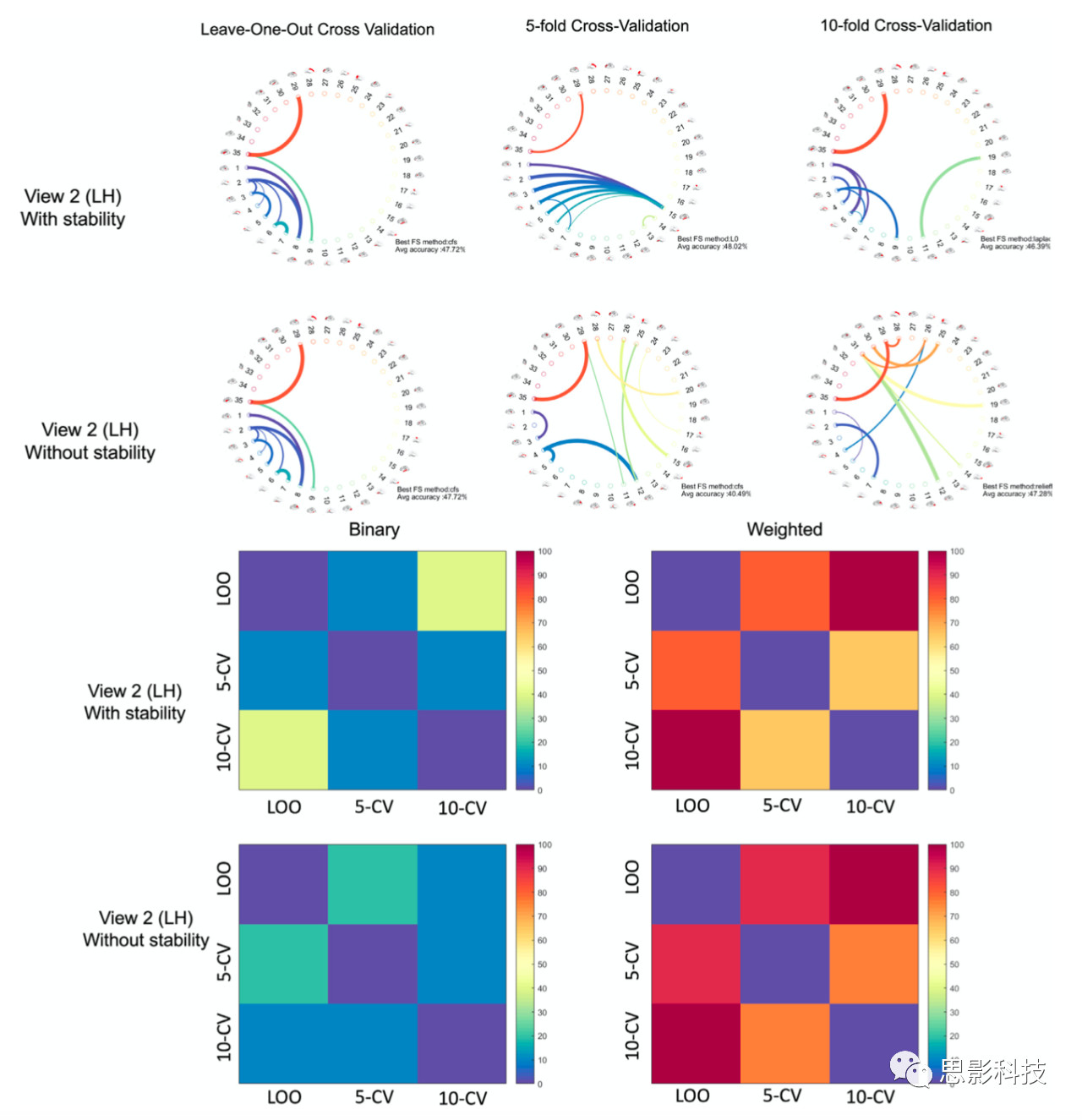
图7. 在ASD vs NC数据集上,不同的CV方法得到的可重复性特征以及CV-CV相似度矩阵。
FS-Select的临床发现 表2展示了为每个数据集和每个大脑视图所识别出来的的两个最具判别性和可重复性的形态学连接。图4-6展示出,无论输入数据集和视图是什么,有一个连接特性一直被选择:[顶叶皮层(29)↔脑岛皮层(35)]。在以前的研究中,这两个皮层区域都在AD和ASD中被报告过。对于AD vs LMCI数据集,可以得出这样的结论:连接特征(尾前扣带皮层(2)↔胼胝体(4)]和[尾前扣带皮层(2)↔内嗅皮层(6)]被确定是最具有可判别性的和可重复性的。与尾前扣带皮层相对应的皮质区域2被发现是一个重要的中枢(hub)区域,这个发现与之前关于AD的研究是一致的。对于ASD vs NC数据集,连接特征包括(尾前扣带皮层(2)↔尾额中回(3)]和[(颞上回后坡1)↔内嗅皮层(6)]被发现是最具有可重复性和判别性的。这些形态学连接涉及到之前关于自闭症谱系障碍的研究中所提到的皮层区域。这些区域可能是重要的生物标记,可能有助于诊断和治疗这两种神经系统疾病。表2. 在不同的交叉验证策略中被选中的FS方法识别出来的最具有可重复性和判别性的连接特征。

FS-Select方法的性能和限制 FS-Select实现了他们的首要目标,即识别最具有可重复性和最具判别性的连接特征,用于检测感兴趣的神经大脑疾病,并具有良好的分类准确性。通过采用三种不同的交叉验证策略,他们证明了FS-Select在训练集不同扰动下的特征可重复的效力。FS-Select使用至少2个不同的交叉验证策略选择合适的脑连接生物标记。FS-Select揭示了对所有不同交叉验证策略(包括颞上沟、尾前扣带皮层和楔叶皮层)反复确认的具有判别性的特定大脑区域的重要性。这可能表明,在研究晚期痴呆对大脑形态的影响时,应该首先考虑这些标志性区域。虽然FS-Select有许多吸引人的方面,但它有一些限制,研究人员打算在未来的工作中解决:1. 在7个FS方法中,只有5个被定期选为最适合评估数据集的方法。udf和llcFS从未被选中。在这项工作中,他们只在两个不同的数据集上测试了框架。需要对不同数据集上的FS- select进行评估,以可靠地评估使用的FS方法的潜力;2. 在研究最具有可重复性的连接特征时,只选择了前10个特征。根据病情的严重程度和所处的阶段,神经障碍疾病可能会改变不同数量的大脑连接,因此可以探索更多的特征;3. 每个FS方法输出一个特征的排序和权重向量。到目前为止,他们只考虑了选择最具鉴别性和可重复性的特征的等级。还可以将特征权重集成到可重复性图的估计中;4. 识别最可重复的FS方法的计算时间取决于所使用的FS方法的时间复杂度和数据大小。这可以通过并行计算来解决,不同的FS方法可以同时训练,因此时间复杂度不是一个大问题。此外,目前最先进的FS方法具有相当合理的时间复杂度。总的来说,最终选择的FS方法的计算代价并不高,但在生物数据模式识别任务中,如发现存在有效治疗神经系统疾病的生物标记,可重复性可以抵消掉计算所花费的时间。本文并不关注所使用的FS方法的时间复杂度,而是关注每个FS方法在选择最具有可重复性特征时的可重复效力。 未来工作与改进 有几个未来的方向可以探索,以进一步提高这项开创性工作。 首先,可以用一种更通用的方法来学习这些关联,而不是预先定义一个相似矩阵来根据顶级特征一致性来建模FS方法之间的关系。 其次,可以在多个连接组数据集上对FS-Select进行评估,包括功能连接和结构连接。 第三,在理想的情况下,具有最佳分类精度的FS方法将识别最具判别性和可重复性的特征。他们的目标是进一步改进FS-Select框架,以识别满足这两个标准的特定于数据的FS方法。 第四,在本研究中,本文只关注于使用FS-Select来演示感兴趣的数据集中的特征可重复性。在未来的工作中,他们将调查这个方法在不同医疗中心获得的特定疾病的独立数据集的可重复性潜力。 第五,如何评估给定特征选择方法的可重复性是一个开放的研究领域,需要开发更先进的数学工具来进行准确和全面的评估和比较。
总结
虽然大多数特征选择方法侧重于提高预测精度,但在本文中,研究者解决了为感兴趣的数据集选择最佳FS方法以提高特征可重复性的问题。特别地,本文介绍了FS-Select,一种能够识别最佳特征选择方法的方法,以发现区分两组(例如,健康的和紊乱的大脑)数据的最可重复和最可靠的特征子集。利用小尺度和大尺度的多视图脑连接数据集,他们用不同的交叉验证策略证明了FS- Select选择的FS方法的可重复性。还发现了不同的可重复的连接特征,可以对自闭症患者和痴呆患者的大脑形态进行“指纹识别”。由于这是为特定数据集寻找最可重复的FS方法的第一次尝试,他们只研究了多重图中编码的不同FS方法之间的两两关系。在未来的工作中,他们将使用超图学习技术来研究不同FS方法之间的高阶关系,在这里将学习如何对FS方法子集之间的关系建模,以增强区别性数据驱动模式的可重复性。尽管证明关于简单程序行为的数学命题似乎非常困难,但是提供FS-select这个方法正确性的证明将为选择甚至设计更严格且可重复的FS方法打下基础,也可以进一步研究替代的FS方法。
原文:Identifying the best data-driven feature selection method for boosting reproducibility in classification tasks

微信扫码或者长按选择识别关注思影
第六届任务态fMRI专题班(重庆4.8-13)
第二十八届磁共振脑影像基础班(重庆2.24-29)
第十四届磁共振脑网络数据处理班(重庆3.18-23)
第二十九届磁共振脑影像基础班(南京3.15-20)